import pandas as pd
import numpy as np
import category_encoders as ce
from collections import Counter
import scipy.stats as ss
from copy import deepcopy
# https://github.com/ashishjain1547/PublicDatasets/blob/master/sales%20orders%20products%20promos%20custs%20emps%20(202112)/sales_data_sample.csv
df_sales = pd.read_csv('sales orders products promos custs emps (202112)/sales_data_sample.csv')
df_sales.head()
 df_sales[['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']].head()
df_sales[['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']].head()
 df_sales.corr()
df_sales.corr()
 df_sales_2 = df_sales[list(set(df_sales.columns) - set(df_sales.corr().columns))]
df_sales_2.head()
df_sales_2 = df_sales[list(set(df_sales.columns) - set(df_sales.corr().columns))]
df_sales_2.head()
 from category_encoders.ordinal import OrdinalEncoder
oe = OrdinalEncoder(drop_invariant=False, return_df=True)
df_sales_3 = df_sales_2[list(set(df_sales.columns) - set(df_sales.corr().columns))]
df_sales_3.head()
from category_encoders.ordinal import OrdinalEncoder
oe = OrdinalEncoder(drop_invariant=False, return_df=True)
df_sales_3 = df_sales_2[list(set(df_sales.columns) - set(df_sales.corr().columns))]
df_sales_3.head()
 df_sales_3.columns
df_sales_3.columns
 oe_var = oe.fit(df_sales_3)
df_coe = oe_var.transform(df_sales_3)
df_coe
oe_var = oe.fit(df_sales_3)
df_coe = oe_var.transform(df_sales_3)
df_coe
 Counter(df_sales_3['PRODUCTLINE'].values).most_common()
Counter(df_sales_3['PRODUCTLINE'].values).most_common()
 df_coe.corr()
df_coe.corr()
 df_coe.corr().loc[['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE'],
['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']]
df_coe.corr().loc[['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE'],
['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']]
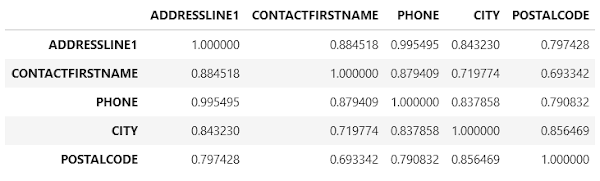 df_coe.corr(method='spearman').loc[['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE'],
['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']]
df_coe.corr(method='spearman').loc[['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE'],
['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']]
 Counter(df_sales_3['PRODUCTLINE'].values).most_common()
Counter(df_sales_3['PRODUCTLINE'].values).most_common()
 def cramers_v_original(confusion_matrix):
""" calculate Cramers V statistic for categorial-categorial association.
uses correction from Bergsma and Wicher,
Journal of the Korean Statistical Society 42 (2013): 323-328
"""
chi2 = ss.chi2_contingency(confusion_matrix)[0]
n = confusion_matrix.sum()
phi2 = chi2 / n
r, k = confusion_matrix.shape
phi2corr = max(0, phi2 - ((k-1)*(r-1))/(n-1))
rcorr = r - ((r-1)**2)/(n-1)
kcorr = k - ((k-1)**2)/(n-1)
return np.sqrt(phi2corr / min((kcorr-1), (rcorr-1)))
categorical_cols = ['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']
out_dict = {}
for i in categorical_cols:
out_dict[i] = []
for j in categorical_cols:
confusion_matrix = pd.crosstab(df_coe[j], df_coe[i]).values
#print('{:<25} {}'.format(i, round(cramers_v_original(confusion_matrix), 4)))
out_dict[i].append(round(cramers_v_original(confusion_matrix), 4))
df_rtn = pd.DataFrame(out_dict)
df_rtn.index = categorical_cols
df_rtn
def cramers_v_original(confusion_matrix):
""" calculate Cramers V statistic for categorial-categorial association.
uses correction from Bergsma and Wicher,
Journal of the Korean Statistical Society 42 (2013): 323-328
"""
chi2 = ss.chi2_contingency(confusion_matrix)[0]
n = confusion_matrix.sum()
phi2 = chi2 / n
r, k = confusion_matrix.shape
phi2corr = max(0, phi2 - ((k-1)*(r-1))/(n-1))
rcorr = r - ((r-1)**2)/(n-1)
kcorr = k - ((k-1)**2)/(n-1)
return np.sqrt(phi2corr / min((kcorr-1), (rcorr-1)))
categorical_cols = ['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']
out_dict = {}
for i in categorical_cols:
out_dict[i] = []
for j in categorical_cols:
confusion_matrix = pd.crosstab(df_coe[j], df_coe[i]).values
#print('{:<25} {}'.format(i, round(cramers_v_original(confusion_matrix), 4)))
out_dict[i].append(round(cramers_v_original(confusion_matrix), 4))
df_rtn = pd.DataFrame(out_dict)
df_rtn.index = categorical_cols
df_rtn
 categorical_cols = ['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']
out_dict = {}
for i in categorical_cols:
out_dict[i] = []
for j in categorical_cols:
confusion_matrix = pd.crosstab(df_sales_3[j], df_sales_3[i]).values
out_dict[i].append(round(cramers_v_original(confusion_matrix), 4))
df_rtn = pd.DataFrame(out_dict)
df_rtn.index = categorical_cols
df_rtn
categorical_cols = ['ADDRESSLINE1', 'CONTACTFIRSTNAME', 'PHONE', 'CITY', 'POSTALCODE']
out_dict = {}
for i in categorical_cols:
out_dict[i] = []
for j in categorical_cols:
confusion_matrix = pd.crosstab(df_sales_3[j], df_sales_3[i]).values
out_dict[i].append(round(cramers_v_original(confusion_matrix), 4))
df_rtn = pd.DataFrame(out_dict)
df_rtn.index = categorical_cols
df_rtn
 df_fe = deepcopy(df_sales_3)
def get_freq(in_):
return pl_dict[in_]
for i2 in categorical_cols:
pl_mc = Counter(df_sales_3[i2].values).most_common()
pl_dict = {}
for i,j in enumerate(pl_mc):
pl_dict[j[0]] = i
df_fe[i2] = df_fe[i2].apply(get_freq)
df_fe = df_fe[categorical_cols]
df_fe = deepcopy(df_sales_3)
def get_freq(in_):
return pl_dict[in_]
for i2 in categorical_cols:
pl_mc = Counter(df_sales_3[i2].values).most_common()
pl_dict = {}
for i,j in enumerate(pl_mc):
pl_dict[j[0]] = i
df_fe[i2] = df_fe[i2].apply(get_freq)
df_fe = df_fe[categorical_cols]

 from scipy.stats import chi2_contingency
chi2_dict = {}
for i in categorical_cols:
chi2_dict[i] = []
for j in categorical_cols:
obs = np.array([df_coe[i], df_coe[j]])
chi2_dict[i].append((round(chi2_contingency(obs)[0], 4), round(chi2_contingency(obs)[1], 4))) # chi2, p, dof, ex
chi2_df = pd.DataFrame(chi2_dict)
chi2_df.index = categorical_cols
from scipy.stats import chi2_contingency
chi2_dict = {}
for i in categorical_cols:
chi2_dict[i] = []
for j in categorical_cols:
obs = np.array([df_coe[i], df_coe[j]])
chi2_dict[i].append((round(chi2_contingency(obs)[0], 4), round(chi2_contingency(obs)[1], 4))) # chi2, p, dof, ex
chi2_df = pd.DataFrame(chi2_dict)
chi2_df.index = categorical_cols
 chi2_dict_2 = {}
for i in categorical_cols:
chi2_dict_2[i] = []
for j in categorical_cols:
obs = np.array([df_coe[i], df_coe[j]])
chi2_dict_2[i].append((round(chi2_contingency(obs)[0], 6))) # chi2, p, dof, ex
chi2_dict_2 = pd.DataFrame(chi2_dict_2)
chi2_dict_2.index = categorical_cols
chi2_dict_2 = {}
for i in categorical_cols:
chi2_dict_2[i] = []
for j in categorical_cols:
obs = np.array([df_coe[i], df_coe[j]])
chi2_dict_2[i].append((round(chi2_contingency(obs)[0], 6))) # chi2, p, dof, ex
chi2_dict_2 = pd.DataFrame(chi2_dict_2)
chi2_dict_2.index = categorical_cols
 from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaler.fit(chi2_dict_2)
chi2_dict_2_scaled = scaler.transform(chi2_dict_2)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaler.fit(chi2_dict_2)
chi2_dict_2_scaled = scaler.transform(chi2_dict_2)
 chi2_df_scaled = pd.DataFrame(data = (1 - chi2_dict_2_scaled),
index = categorical_cols,
columns = categorical_cols)
chi2_df_scaled = pd.DataFrame(data = (1 - chi2_dict_2_scaled),
index = categorical_cols,
columns = categorical_cols)

Thursday, December 2, 2021
Categorical encoding, correlation (numerical and cat), and chi-sq contingency Using Python




















Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment