Elbow method (clustering)
In cluster analysis, the elbow method is a heuristic used in determining the number of clusters in a data set. The method consists of plotting the explained variation as a function of the number of clusters, and picking the elbow of the curve as the number of clusters to use. The same method can be used to choose the number of parameters in other data-driven models, such as the number of principal components to describe a data set. Intuition Using the "elbow" or "knee of a curve" as a cutoff point is a common heuristic in mathematical optimization to choose a point where diminishing returns are no longer worth the additional cost. In clustering, this means one should choose a number of clusters so that adding another cluster doesn't give much better modeling of the data. The intuition is that increasing the number of clusters will naturally improve the fit (explain more of the variation), since there are more parameters (more clusters) to use, but that at some point this is over-fitting, and the elbow reflects this. For example, given data that actually consist of k labeled groups – for example, k points sampled with noise – clustering with more than k clusters will "explain" more of the variation (since it can use smaller, tighter clusters), but this is over-fitting, since it is subdividing the labeled groups into multiple clusters. The idea is that the first clusters will add much information (explain a lot of variation), since the data actually consist of that many groups (so these clusters are necessary), but once the number of clusters exceeds the actual number of groups in the data, the added information will drop sharply, because it is just subdividing the actual groups. Assuming this happens, there will be a sharp elbow in the graph of explained variation versus clusters: increasing rapidly up to k (under-fitting region), and then increasing slowly after k (over-fitting region). In practice there may not be a sharp elbow, and as a heuristic method, such an "elbow" cannot always be unambiguously identified. Measures of variation There are various measures of "explained variation" used in the elbow method. Most commonly, variation is quantified by variance, and the ratio used is the ratio of between-group variance to the total variance. Alternatively, one uses the ratio of between-group variance to within-group variance, which is the one-way ANOVA F-test statistic.Explained variance. The "elbow" is indicated by the red circle. The number of clusters chosen should therefore be 4. Related Concepts ANOVA Analysis of variance (ANOVA) is a collection of statistical models and their associated estimation procedures (such as the "variation" among and between groups) used to analyze the differences among group means in a sample. ANOVA was developed by the statistician Ronald Fisher. The ANOVA is based on the law of total variance, where the observed variance in a particular variable is partitioned into components attributable to different sources of variation. In its simplest form, ANOVA provides a statistical test of whether two or more population means are equal, and therefore generalizes the t-test beyond two means. Principal component analysis (PCA) Principal component analysis (PCA) is the process of computing the principal components and using them to perform a change of basis on the data, sometimes only using the first few principal components and ignoring the rest. PCA is used in exploratory data analysis and for making predictive models. It is commonly used for dimensionality reduction by projecting each data point onto only the first few principal components to obtain lower-dimensional data while preserving as much of the data's variation as possible. The first principal component can equivalently be defined as a direction that maximizes the variance of the projected data. The i(th) principal component can be taken as a direction orthogonal to the first (i-1) principal components that maximizes the variance of the projected data. Python based Software/source code % Matplotlib – Python library have a PCA package in the .mlab module. % Scikit-learn – Python library for machine learning which contains PCA, Probabilistic PCA, Kernel PCA, Sparse PCA and other techniques in the decomposition module. Reiterating... Determining the number of clusters in a data set Determining the number of clusters in a data set, a quantity often labelled k as in the k-means algorithm, is a frequent problem in data clustering, and is a distinct issue from the process of actually solving the clustering problem. For a certain class of clustering algorithms (in particular k-means, k-medoids and expectation–maximization algorithm), there is a parameter commonly referred to as k that specifies the number of clusters to detect. Other algorithms such as DBSCAN and OPTICS algorithm do not require the specification of this parameter; hierarchical clustering avoids the problem altogether. The correct choice of k is often ambiguous, with interpretations depending on the shape and scale of the distribution of points in a data set and the desired clustering resolution of the user. In addition, increasing k without penalty will always reduce the amount of error in the resulting clustering, to the extreme case of zero error if each data point is considered its own cluster (i.e., when k equals the number of data points, n). Intuitively then, the optimal choice of k will strike a balance between maximum compression of the data using a single cluster, and maximum accuracy by assigning each data point to its own cluster. If an appropriate value of k is not apparent from prior knowledge of the properties of the data set, it must be chosen somehow. There are several categories of methods for making this decision. The elbow method for clustering The elbow method looks at the percentage of variance explained as a function of the number of clusters: One should choose a number of clusters so that adding another cluster doesn't give much better modeling of the data. More precisely, if one plots the percentage of variance explained by the clusters against the number of clusters, the first clusters will add much information (explain a lot of variance), but at some point the marginal gain will drop, giving an angle in the graph. The number of clusters is chosen at this point, hence the "elbow criterion". This "elbow" cannot always be unambiguously identified, making this method very subjective and unreliable. Percentage of variance explained is the ratio of the between-group variance to the total variance, also known as an F-test. A slight variation of this method plots the curvature of the within group variance. The silhouette method (for clustering) The average silhouette of the data is another useful criterion for assessing the natural number of clusters. The silhouette of a data instance is a measure of how closely it is matched to data within its cluster and how loosely it is matched to data of the neighbouring cluster, i.e. the cluster whose average distance from the datum is lowest. A silhouette close to 1 implies the datum is in an appropriate cluster, while a silhouette close to −1 implies the datum is in the wrong cluster. Optimization techniques such as genetic algorithms are useful in determining the number of clusters that gives rise to the largest silhouette. It is also possible to re-scale the data in such a way that the silhouette is more likely to be maximised at the correct number of clusters. Silhouette coefficient The Silhouette Coefficient is calculated using the mean intra-cluster distance (a) and the mean nearest-cluster distance (b) for each sample. The Silhouette Coefficient for a sample is (b - a) / max(a, b). To clarify, b is the distance between a sample and the nearest cluster that the sample is not a part of. We can compute the mean Silhouette Coefficient over all samples and use this as a metric to judge the number of clusters. Ref 1: Elbow method (clustering) Ref 2: F-test Ref 3: Analysis of variance Ref 4: Principal component analysis Ref 5: Determining the number of clusters in a data set Elbow Method for optimal value of k in KMeans (using 'Distortion' and 'Inertia' and not with explainable variance) A fundamental step for any unsupervised algorithm is to determine the optimal number of clusters into which the data may be clustered. The Elbow Method is one of the most popular methods to determine this optimal value of k. We now define the following: Distortion: It is calculated as the average of the squared distances from the cluster centers of the respective clusters. Typically, the Euclidean distance metric is used.Inertia: It is the sum of squared distances of samples to their closest cluster center.Ref 6: Determining the optimal number of clusters Ref 7: Choosing the number of clusters (Coursera) In code from sklearn.cluster import KMeans from sklearn import metrics from scipy.spatial.distance import cdist import numpy as np import matplotlib.pyplot as plt %matplotlib inline #Creating the data x1 = np.array([3, 1, 1, 2, 1, 6, 6, 6, 5, 6, 7, 8, 9, 8, 9, 9, 8]) x2 = np.array([5, 4, 5, 6, 5, 8, 6, 7, 6, 7, 1, 2, 1, 2, 3, 2, 3]) X = np.array(list(zip(x1, x2))).reshape(len(x1), 2) #Visualizing the data plt.plot() plt.xlim([0, 10]) plt.ylim([0, 10]) plt.title('Dataset') plt.scatter(x1, x2) plt.show()distortions = [] inertias = [] mapping1 = {} mapping2 = {} K = range(1,10) for k in K: #Building and fitting the model kmeanModel = KMeans(n_clusters=k).fit(X) kmeanModel.fit(X) distortions.append(sum(np.min(cdist(X, kmeanModel.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0]) inertias.append(kmeanModel.inertia_) mapping1[k] = sum(np.min(cdist(X, kmeanModel.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0] mapping2[k] = kmeanModel.inertia_ for key, val in mapping1.items(): print(str(key), ': ', str(val)) plt.plot(K, distortions, 'bx-') plt.xlabel('Values of K') plt.ylabel('Distortion') plt.title('The Elbow Method using Distortion') plt.show()for key, val in mapping2.items(): print(str(key), ': ', str(val)) plt.plot(K, inertias, 'bx-') plt.xlabel('Values of K') plt.ylabel('Inertia') plt.title('The Elbow Method using Inertia') plt.show()A note about np.array(), np.min() and "from scipy.spatial.distance import cdist"Elbow Method for kNN (classification problem)
How to select the optimal K value (representing the number of Nearest Neighbors)? - Initialize a random K value and start computing. - Choosing a small value of K leads to unstable decision boundaries. - The substantial K value is better for classification as it leads to smoothening the decision boundaries. - Derive a plot between error rate and K denoting values in a defined range. Then choose the K value as having a minimum error rate. - Instead of "error", one could also plot for 'accuracy' against 'K'. With error, the curve is decreasing with K. With accuracy, the curve is increasing with K.
Saturday, August 29, 2020
Elbow Method for identifying k in kMeans (clustering) and kNN (classification)









Wednesday, August 26, 2020
Deploying Flask based 'Hello World' REST API on Heroku Cloud
Getting Started on Heroku with Python Basic requirement: - a free Heroku account - Python version 3.7 installed locally - see the installation guides for OS X, Windows, and Linux. - Heroku CLI requires Git You can Git from here: git-scm - For first time Git setup:Getting-Started-First-Time-Git-Setup Heroku CLI is avaiable for macOS, Windows and Linux. You use the Heroku CLI to manage and scale your applications, provision add-ons, view your application logs, and run your application locally. Once installed, you can use the heroku command from your command shell. On Windows, start the Command Prompt (cmd.exe) or Powershell to access the command shell. Use the heroku login command to log in to the Heroku CLI: (base) C:\Users\Ashish Jain>heroku login heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/cli/browser/716***J1k heroku: Waiting for login... -(base) C:\Users\Ashish Jain>heroku login heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/cli/browser/716***J1k Logging in... done Logged in as a***@gmail.comCreate the app
Create an app on Heroku, which prepares Heroku to receive your source code: When you create an app, a git remote (called heroku) is also created and associated with your local git repository. Heroku generates a random name (in this case serene-caverns-82714) for your app, or you can pass a parameter to specify your own app name. (base) C:\Users\Ashish Jain\OneDrive\Desktop>cd myapp (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp>dir Directory of C:\Users\Ashish Jain\OneDrive\Desktop\myapp 0 File(s) 0 bytes (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp>heroku create Creating app... done, ⬢ rocky-spire-96801 https://rocky-spire-96801.herokuapp.com/ | https://git.heroku.com/rocky-spire-96801.git (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp>git clone https://git.heroku.com/rocky-spire-96801.git Cloning into 'rocky-spire-96801'... warning: You appear to have cloned an empty repository.Writing a Python Script file
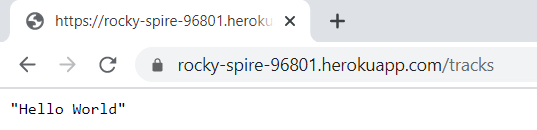
We are at: C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801 We create a Python script: MyRESTAPIUsingPythonScript.py It has following code: from flask import Flask, request from flask_restful import Resource, Api import os app = Flask(__name__) api = Api(app) class Tracks(Resource): def get(self): result = "Hello World" return result api.add_resource(Tracks, '/tracks') # URL Route if __name__ == '__main__': port = int(os.environ.get('PORT', 5000)) app.run(host='0.0.0.0', port=port) In the code above: Heroku dynamically assigns your app a port, so we cannot set the port to a fixed number. Heroku adds the port to the env, so we pull it from there. Wrong Code 1 if __name__ == '__main__': app.run(port='5002') Error Logs: 2020-08-26T16:20:58.493306+00:00 app[web.1]: * Running on http://127.0.0.1:5002/ (Press CTRL+C to quit) ... 2020-08-26T16:23:01.745361+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:23:01.782641+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:23:01.914043+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:23:01.987508+00:00 heroku[web.1]: State changed from starting to crashed Wrong Code 2 if __name__ == '__main__': app.run() Error logs: (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logs ... 2020-08-26T16:27:43.161519+00:00 app[web.1]: * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) 2020-08-26T16:27:45.000000+00:00 app[api]: Build succeeded 2020-08-26T16:28:40.527069+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:28:40.548232+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:28:40.611066+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:28:40.655930+00:00 heroku[web.1]: State changed from starting to crashed Wrong Code 3 if __name__ == '__main__': app.run(host='0.0.0.0') (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logs ... 2020-08-26T16:35:36.792884+00:00 heroku[web.1]: Starting process with command `python MyRESTAPIUsingPythonScript.py` 2020-08-26T16:35:40.000000+00:00 app[api]: Build succeeded 2020-08-26T16:35:40.100687+00:00 app[web.1]: * Serving Flask app "MyRESTAPIUsingPythonScript" (lazy loading) 2020-08-26T16:35:40.100727+00:00 app[web.1]: * Environment: production 2020-08-26T16:35:40.100730+00:00 app[web.1]: WARNING: This is a development server. Do not use it in a production deployment. 2020-08-26T16:35:40.100738+00:00 app[web.1]: Use a production WSGI server instead. 2020-08-26T16:35:40.100767+00:00 app[web.1]: * Debug mode: off 2020-08-26T16:35:40.103621+00:00 app[web.1]: * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) 2020-08-26T16:37:41.234182+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:37:41.260167+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:37:41.377892+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:37:41.426917+00:00 heroku[web.1]: State changed from starting to crashed About "git commit" logs Every time we do changes and commit, Heroku knows which release this is. See below, it says "Released v6": (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git add . (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git commit -m "1012" [master a4975c0] 1012 1 file changed, 3 insertions(+), 1 deletion(-) (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push Enumerating objects: 5, done. Counting objects: 100% (5/5), done. Delta compression using up to 4 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 423 bytes | 423.00 KiB/s, done. Total 3 (delta 1), reused 0 (delta 0), pack-reused 0 remote: Compressing source files... done. remote: Building source: remote: remote: -----> Python app detected remote: -----> No change in requirements detected, installing from cache remote: -----> Installing pip 20.1.1, setuptools 47.1.1 and wheel 0.34.2 remote: -----> Installing SQLite3 remote: -----> Installing requirements with pip remote: -----> Discovering process types remote: Procfile declares types -> web remote: remote: -----> Compressing... remote: Done: 45.6M remote: -----> Launching... remote: Released v6 remote: https://rocky-spire-96801.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/rocky-spire-96801.git 0391d70..a4975c0 master -> masterDefine a Procfile
We create a file "Procfile" at: C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801 Based on our code (which is a Python script to run a simple Flask based REST API), we write in Procfile: web: python MyRESTAPIUsingPythonScript.py Procfile naming and location The Procfile is always a simple text file that is named Procfile without a file extension. For example, Procfile.txt is not valid. The Procfile must live in your app’s root directory. It does not function if placed anywhere else. Procfile format A Procfile declares its process types on individual lines, each with the following format: [process type]: [command] [process type] is an alphanumeric name for your command, such as web, worker, urgentworker, clock, and so on. [command] indicates the command that every dyno of the process type should execute on startup, such as rake jobs:work. The "web" process type A Heroku app’s web process type is special: it’s the only process type that can receive external HTTP traffic from Heroku’s routers. If your app includes a web server, you should declare it as your app’s web process. For example, the Procfile for a Rails web app might include the following process type: web: bundle exec rails server -p $PORT In this case, every web dyno executes bundle exec rails server -p $PORT, which starts up a web server. A Clojure app’s web process type might look like this: web: lein run -m demo.web $PORT You can refer to your app’s config vars, most usefully $PORT, in the commands you specify. This might be the web process type for an executable Java JAR file, such as when using Spring Boot: web: java -jar target/myapp-1.0.0.jar More on Procfile here: devcenter.heroku Deploying to Heroku A Procfile is not technically required to deploy simple apps written in most Heroku-supported languages—the platform automatically detects the language and creates a default web process type to boot the application server. However, creating an explicit Procfile is recommended for greater control and flexibility over your app. For Heroku to use your Procfile, add the Procfile to the root directory of your application, then push to Heroku: (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>dir Directory of C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801 08/26/2020 09:47 PM [DIR] . 08/26/2020 09:47 PM [DIR] .. 08/26/2020 09:40 PM 326 MyRESTAPIUsingPythonScript.py 08/26/2020 09:42 PM 41 Procfile 08/26/2020 09:33 PM 22 requirements.txt 3 File(s) 389 bytes 2 Dir(s) 65,828,458,496 bytes free (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git add . (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git commit -m "first commit" [master (root-commit) ff73728] first commit 3 files changed, 18 insertions(+) create mode 100644 MyRESTAPIUsingPythonScript.py create mode 100644 Procfile create mode 100644 requirements.txt As opposed to what appears on the Heroku documentation, we simply have to do "git push" now. Otherwise we see following errors: (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push heroku master fatal: 'heroku' does not appear to be a git repository fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists. (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push master fatal: 'master' does not appear to be a git repository fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists. (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push Enumerating objects: 5, done. Counting objects: 100% (5/5), done. Delta compression using up to 4 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (5/5), 585 bytes | 292.00 KiB/s, done. Total 5 (delta 0), reused 0 (delta 0), pack-reused 0 remote: Compressing source files... done. remote: Building source: remote: remote: -----> Python app detected remote: -----> Installing python-3.6.12 remote: -----> Installing pip 20.1.1, setuptools 47.1.1 and wheel 0.34.2 remote: -----> Installing SQLite3 remote: -----> Installing requirements with pip remote: Collecting flask remote: Downloading Flask-1.1.2-py2.py3-none-any.whl (94 kB) remote: Collecting flask_restful remote: Downloading Flask_RESTful-0.3.8-py2.py3-none-any.whl (25 kB) remote: Collecting click>=5.1 remote: Downloading click-7.1.2-py2.py3-none-any.whl (82 kB) remote: Collecting Jinja2>=2.10.1 remote: Downloading Jinja2-2.11.2-py2.py3-none-any.whl (125 kB) remote: Collecting Werkzeug>=0.15 remote: Downloading Werkzeug-1.0.1-py2.py3-none-any.whl (298 kB) remote: Collecting itsdangerous>=0.24 remote: Downloading itsdangerous-1.1.0-py2.py3-none-any.whl (16 kB) remote: Collecting pytz remote: Downloading pytz-2020.1-py2.py3-none-any.whl (510 kB) remote: Collecting aniso8601>=0.82 remote: Downloading aniso8601-8.0.0-py2.py3-none-any.whl (43 kB) remote: Collecting six>=1.3.0 remote: Downloading six-1.15.0-py2.py3-none-any.whl (10 kB) remote: Collecting MarkupSafe>=0.23 remote: Downloading MarkupSafe-1.1.1-cp36-cp36m-manylinux1_x86_64.whl (27 kB) remote: Installing collected packages: click, MarkupSafe, Jinja2, Werkzeug, itsdangerous, flask, pytz, aniso8601, six, flask-restful remote: Successfully installed Jinja2-2.11.2 MarkupSafe-1.1.1 Werkzeug-1.0.1 aniso8601-8.0.0 click-7.1.2 flask-1.1.2 flask-restful-0.3.8 itsdangerous-1.1.0 pytz-2020.1 six-1.15.0 remote: -----> Discovering process types remote: Procfile declares types -> web remote: remote: -----> Compressing... remote: Done: 45.6M remote: -----> Launching... remote: Released v3 remote: https://rocky-spire-96801.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/rocky-spire-96801.git * [new branch] master -> master Checking Heroku process status (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku ps Free dyno hours quota remaining this month: 550h 0m (100%) Free dyno usage for this app: 0h 0m (0%) For more information on dyno sleeping and how to upgrade, see: https://devcenter.heroku.com/articles/dyno-sleeping === web (Free): python MyRESTAPIUsingPythonScript.py (1) web.1: restarting 2020/08/26 21:51:56 +0530 (~ 41s ago) (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku ps Free dyno hours quota remaining this month: 550h 0m (100%) Free dyno usage for this app: 0h 0m (0%) For more information on dyno sleeping and how to upgrade, see: https://devcenter.heroku.com/articles/dyno-sleeping === web (Free): python MyRESTAPIUsingPythonScript.py (1) web.1: up 2020/08/26 22:28:06 +0530 (~ 12m ago) Check Logs (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logs 2020-08-26T15:55:49.855840+00:00 app[api]: Initial release by user a***@gmail.com 2020-08-26T15:55:49.855840+00:00 app[api]: Release v1 created by user a***@gmail.com 2020-08-26T15:55:49.992678+00:00 app[api]: Enable Logplex by user a***@gmail.com 2020-08-26T15:55:49.992678+00:00 app[api]: Release v2 created by user a***@gmail.com 2020-08-26T16:20:26.000000+00:00 app[api]: Build started by user a***@gmail.com 2020-08-26T16:20:51.873133+00:00 app[api]: Release v3 created by user a***@gmail.com 2020-08-26T16:20:51.873133+00:00 app[api]: Deploy ff73728d by user a***@gmail.com 2020-08-26T16:20:51.891792+00:00 app[api]: Scaled to web@1:Free by user a***@gmail.com 2020-08-26T16:20:55.659055+00:00 heroku[web.1]: Starting process with command `python MyRESTAPIUsingPythonScript.py` 2020-08-26T16:20:58.489161+00:00 app[web.1]: * Serving Flask app "MyRESTAPIUsingPythonScript" (lazy loading) 2020-08-26T16:20:58.489192+00:00 app[web.1]: * Environment: production 2020-08-26T16:20:58.489257+00:00 app[web.1]: WARNING: This is a development server. Do not use it in a production deployment. 2020-08-26T16:20:58.489350+00:00 app[web.1]: Use a production WSGI server instead. 2020-08-26T16:20:58.489393+00:00 app[web.1]: * Debug mode: off 2020-08-26T16:20:58.493306+00:00 app[web.1]: * Running on http://127.0.0.1:5002/ (Press CTRL+C to quit) 2020-08-26T16:21:00.000000+00:00 app[api]: Build succeeded 2020-08-26T16:28:40.527069+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:28:40.548232+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:28:40.611066+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:28:40.655930+00:00 heroku[web.1]: State changed from starting to crashed ... 2020-08-26T16:43:04.803725+00:00 heroku[web.1]: State changed from crashed to starting 2020-08-26T16:43:07.586143+00:00 heroku[web.1]: Starting process with command `python MyRESTAPIUsingPythonScript.py` 2020-08-26T16:43:09.742529+00:00 app[web.1]: * Serving Flask app "MyRESTAPIUsingPythonScript" (lazy loading) 2020-08-26T16:43:09.742547+00:00 app[web.1]: * Environment: production 2020-08-26T16:43:09.742586+00:00 app[web.1]: WARNING: This is a development server. Do not use it in a production deployment. 2020-08-26T16:43:09.742625+00:00 app[web.1]: Use a production WSGI server instead. 2020-08-26T16:43:09.742662+00:00 app[web.1]: * Debug mode: off 2020-08-26T16:43:09.745322+00:00 app[web.1]: * Running on http://0.0.0.0:32410/ (Press CTRL+C to quit) 2020-08-26T16:43:09.847177+00:00 heroku[web.1]: State changed from starting to up 2020-08-26T16:43:12.000000+00:00 app[api]: Build succeeded (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku open In Firefox browser with URL: https://rocky-spire-96801.herokuapp.com/ Not Found The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again. In Firefox at URL: https://rocky-spire-96801.herokuapp.com/tracksIn Chrome at URL: https://rocky-spire-96801.herokuapp.com/tracksLogout (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logout Logging out... done



Tuesday, August 25, 2020
Working with 'dir' command on Windows CMD prompt
# Finding a file/folder with a string in its name.Note: /s Lists every occurrence of the specified file name within the specified directory and all subdirectories. Exploring "dir" documentation C:\Users\Ashish Jain>help dir Displays a list of files and subdirectories in a directory. DIR [drive:][path][filename] [/A[[:]attributes]] [/B] [/C] [/D] [/L] [/N] [/O[[:]sortorder]] [/P] [/Q] [/R] [/S] [/T[[:]timefield]] [/W] [/X] [/4] [drive:][path][filename] Specifies drive, directory, and/or files to list. /A Displays files with specified attributes. attributes D Directories R Read-only files H Hidden files A Files ready for archiving S System files I Not content indexed files L Reparse Points - Prefix meaning not /B Uses bare format (no heading information or summary). /C Display the thousand separator in file sizes. This is the default. Use /-C to disable display of separator. /D Same as wide but files are list sorted by column. /L Uses lowercase. /N New long list format where filenames are on the far right. /O List by files in sorted order. sortorder N By name (alphabetic) S By size (smallest first) E By extension (alphabetic) D By date/time (oldest first) G Group directories first - Prefix to reverse order /P Pauses after each screenful of information. /Q Display the owner of the file. /R Display alternate data streams of the file. /S Displays files in specified directory and all subdirectories. /T Controls which time field displayed or used for sorting timefield C Creation A Last Access W Last Written /W Uses wide list format. /X This displays the short names generated for non-8dot3 file names. The format is that of /N with the short name inserted before the long name. If no short name is present, blanks are displayed in its place. /4 Displays four-digit years Switches may be preset in the DIRCMD environment variable. Override preset switches by prefixing any switch with - (hyphen)--for example, /-W. --- --- --- --- --- # You can include files in the current or named directory plus all of its accessible subdirectories by using the /S option. This example displays all of the .WKS and .WK1 files in the D:\DATA directory and each of its subdirectories: dir /s d:\data\*.wks;*.wk1 --- --- --- --- --- # Look for text files in D: drive containing the letter 'ACC' in the case-insensitive manner. dir /s D:\*ACC*.txt OUTPUT: Directory of D:\Downloads\rw\jakarta-tomcat-8.0.35\logs 30-Dec-16 02:05 PM 61,549 localhost_access_log.2016-10-06.txt ... Directory of D:\Work Space\rw_new\temp\iTAP\licenses 27-Jan-16 07:46 PM 1,536 javacc-license.txt 1 File(s) 1,536 bytes --- --- --- --- --- We have following directory structure in a "test" folder: C:\Users\Ashish Jain\OneDrive\Desktop\test>tree /f Folder PATH listing for volume Windows Volume serial number is 8139-90C0 C:. │ 3.txt │ ├───1 │ └───a │ file.txt │ └───2 file_2.txt 1. List everything in this directory: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s/b C:\Users\Ashish Jain\OneDrive\Desktop\test\1 C:\Users\Ashish Jain\OneDrive\Desktop\test\2 C:\Users\Ashish Jain\OneDrive\Desktop\test\3.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a\file.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\2\file_2.txt 2. List subdirectories of this directory: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s/b /A:D C:\Users\Ashish Jain\OneDrive\Desktop\test\1 C:\Users\Ashish Jain\OneDrive\Desktop\test\2 C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a 3. List files in this directory and subdirectories: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s/b /A:-D C:\Users\Ashish Jain\OneDrive\Desktop\test\3.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a\file.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\2\file_2.txt Explanation for ‘dir /A:D’: D:\>dir /? Displays a list of files and subdirectories in a directory. DIR [drive:][path][filename] [/A[[:]attributes]] [/B] [/C] [/D] [/L] [/N] [/O[[:]sortorder]] [/P] [/Q] [/R] [/S] [/T[[:]timefield]] [/W] [/X] [/4] [drive:][path][filename] Specifies drive, directory, and/or files to list. /A Displays files with specified attributes. attributes D Directories R Read-only files H Hidden files A Files ready for archiving S System files I Not content indexed files L Reparse Points - Prefix meaning not Another way of listing only subdirectories: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s | find "\" Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test\1 Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test\2

Monday, August 24, 2020
Sentiment Analysis Books (Aug 2020)
Google Search String: "sentiment analysis books" 1. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions Book by Bing Liu Originally published: 28 May 2015 Author: Bing Liu Genre: Reference work 2. Sentiment Analysis and Opinion Mining Book by Bing Liu Originally published: 2012 Author: Bing Liu 3. A Practical Guide to Sentiment Analysis Book Originally published: 7 April 2017 Erik Cambria, Dipankar Das, Sivaji Bandyopadhyay, Antonio Feraco (eds.) Springer International Publishing 4. Sentiment Analysis in Social Networks Book Originally published: 30 September 2016 5. Opinion Mining and Sentiment Analysis Book by Bo Pang and Lillian Lee Originally published: 2008 Authors: Bo Pang, Lillian Lee 6. Deep Learning-Based Approaches for Sentiment Analysis Book Originally published: 24 January 2020 7. Text Mining with R: A Tidy Approach Book by David Robinson and Julia Silge Originally published: 2017 8. Advanced Positioning, Flow, and Sentiment Analysis in Commodity Markets: Bridging Fundamental and Technical Analysis Book by Mark J. S. Keenan Originally published: 20 December 2019 9. Prominent Feature Extraction for Sentiment Analysis Book by Basant Agarwal and Namita Mittal Originally published: 14 December 2015 10. Handbook of Sentiment Analysis in Finance Book Originally published: 2016 11. Sentiment Analysis and Knowledge Discovery in Contemporary Business Book Originally published: 25 May 2018 12. Visual and Text Sentiment Analysis Through Hierarchical Deep Learning Networks Book by Arindam Chaudhuri Originally published: 6 April 2019 Author: Arindam Chaudhuri 13. Affective Computing and Sentiment Analysis: Emotion, Metaphor and Terminology Book Originally published: 2011 Editor: Khurshid Ahmad 14. Sentiment Analysis and Ontology Engineering: An Environment of Computational Intelligence Book Originally published: 22 March 2016 15. Advances in Social Networking-based Learning: Machine Learning-based User Modelling and Sentiment Analysis Book by Christos Troussas and Maria Virvou Originally published: 20 January 2020 16. Machine Learning: An overview with the help of R software Book by Editor Ijsmi Originally published: 20 November 2018 17. People Analytics & Text Mining with R Book by Mong Shen Ng Originally published: 21 March 2019 18. The Successful Trader Foundation: How To Become The 1% Successful ... Book by Thang Duc Chu Originally published: 18 July 2019 19. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data Book by Bing Liu Originally published: 30 May 2007 20. Deep Learning in Natural Language Processing Book Originally published: 23 May 2018 Li Deng, Yang Liu Springer 21. Multimodal Sentiment Analysis Novel by Amir Hussain, Erik Cambria, and Soujanya Poria Originally published: 24 October 2018 22. Sentic Computing: Techniques, Tools, and Applications Novel by Amir Hussain and Erik Cambria Originally published: 28 July 2012 23. Semantic Sentiment Analysis in Social Streams Book by Hassan Saif Originally published: 2017 Author: Hassan Saif Genre: Dissertation 24. Trading on Sentiment: The Power of Minds Over Markets Book by Richard L. Peterson Originally published: 2 March 2016 25. Natural Language Processing with Python Book by Edward Loper, Ewan Klein, and Steven Bird Originally published: June 2009 26. Sentiment Analysis Book by BLOKDYK. GERARDUS Originally published: May 2018 27. Applied Text Analysis with Python: Enabling Language-Aware Data Products with Machine Learning Book by Benjamin Bengfort, Rebecca Bilbro, and Tony Ojeda Originally published: 2018 28. Sentiment Analysis in the Bio-Medical Domain: Techniques, Tools, and Applications Book by Amir Hussain, Erik Cambria, and Ranjan Satapathy Originally published: 23 January 2018 29. Sentiment in the Forex Market: Indicators and Strategies To Profit from Crowd Behavior and Market Extremes Book by Jamie Saettele Originally published: 2008 30. Big Data Analytics with Java Book by Rajat Mehta Originally published: 28 July 2017 31. Sentiment Analysis for Social Media Book Originally published: 2 April 2020 32. Applying Sentiment Analysis for Tweets Linking to Scientific Papers Book by Natalie Friedrich Originally published: 21 December 2015 33. A Survey of Sentiment Analysis Book by Moritz Platt Originally published: May 2014 34. Textual Classification for Sentiment Detection. Brand Reputation Analysis on the ... Book by Mike Nkongolo Originally published: 10 April 2018 35. Company Fit: A Decision Support Tool Based on Feature Level Sentiment ... Book by Akshi Kumar Originally published: 30 August 2017 36. KNN Classifier Based Approach for Multi-Class Sentiment Analysis of Twitter Data Book by Soudamini Hota and Sudhir Pathak Originally published: 18 October 2017 37. A Classification Technique for Sentiment Analysis in Data Mining Book Originally published: 13 September 2017 38. Exploration of Competitive Market Behavior Using Near-Real-Time Sentiment Analysis Book by Norman Peitek Originally published: 30 December 2014 39. Sentiment Analysis for PTSD Signals Book by Demetrios Sapounas, Edward Rossini, and Vadim Kagan Originally published: 25 October 2013 40. Lifelong Machine Learning: Second Edition Book by Bing Liu and Zhiyuan Chen Originally published: 7 November 2016 41. Handbook of Natural Language Processing Book Originally published: 19 February 2010 42. Neural Network Methods in Natural Language Processing Book by Yoav Goldberg Originally published: 2017 43. The General Inquirer: A Computer Approach to Content Analysis Book by Philip James Stone Originally published: 1966 44. Plutchik, Robert (1980), Emotion: Theory, research, and experience: Vol. 1. Theories of emotion, 1, New York: Academic 45. Foundations of Statistical Natural Language Processing Book by Christopher D. Manning and Hinrich Schütze Originally published: 1999 46. Sentiment Analysis: Quick Reference Book by BLOKDYK. GERARDUS Originally published: 14 January 2018 47. Intelligent Asset Management Book by Erik Cambria, Frank Xing, and Roy Welsch Originally published: 13 November 2019 48. Sentic Computing: A Common-Sense-Based Framework for Concept-Level Sentiment Analysis Book by Amir Hussain and Erik Cambria Originally published: 11 December 2015 49. Computational Linguistics and Intelligent Text Processing: 18th International Conference, CICLing 2017, Budapest, Hungary, April 17–23, 2017, Revised Selected Papers, Part II Book Originally published: 9 October 2018 50. The SenticNet Sentiment Lexicon: Exploring Semantic Richness in Multi-Word Concepts Book by Raoul Biagioni Originally published: 28 May 2016

Sunday, August 23, 2020
Compare Two Files Using 'git diff'
Note: Our current directory is not in a Git repository. We have two files "file_1.txt" and "file_2.txt". "file_1.txt" has content: Hermione is a good girl. Hermione is a bad girl. Hermione is a very good girl. "file_2.txt" has content: Hermione is a good girl. No, Hermione is not a bad girl. Hermione is a very good girl. The color coding below is as it appears in Windows CMD prompt: C:\Users\Ashish Jain\OneDrive\Desktop>git diff --no-index file_1.txt file_2.txt diff --git a/file_1.txt b/file_2.txt index fc04cd5..52bdfd9 100644 --- a/file_1.txt +++ b/file_2.txt, @@ -1,3 +1,3 @@ Hermione is a good girl. -Hermione is a bad girl. +No, Hermione is not a bad girl. Hermione is a very good girl. \ No newline at end of file C:\Users\Ashish Jain\OneDrive\Desktop>git diff --no-index file_2.txt file_1.txt diff --git a/file_2.txt b/file_1.txt index 52bdfd9..fc04cd5 100644 --- a/file_2.txt +++ b/file_1.txt @@ -1,3 +1,3 @@ Hermione is a good girl. -No, Hermione is not a bad girl. +Hermione is a bad girl. Hermione is a very good girl. \ No newline at end of file The output of the "git diff" is with respect to the first file. Output of "git diff file_1.txt file_2.txt" is read as: "What changed in file_1 as we move from file_1 to file_2".

Using Snorkel to create test data and classifying using Scikit-Learn
The data set we have is the "Iris" dataset. We will augment the dataset to create "test" dataset and then use "Scikit-Learn's Support Vector Machines' classifier 'SVC'" to classify the test points into one of the Iris species.
import pandas as pd
import numpy as np
from snorkel.augmentation import transformation_function
from snorkel.augmentation import RandomPolicy
from snorkel.augmentation import PandasTFApplier
from sklearn import svm
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
df = pd.read_csv('files_1/datasets_19_420_Iris.csv')
for i in set(df.Species):
# Other columns are ['count', 'mean', 'std', 'min', '25%', '50%', '75%', 'max']
print(i)
print(df[df.Species == i].describe().loc[['min', '25%', '50%', '75%', 'max'], :])
 features = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']
classes = ['Iris-setosa', 'Iris-virginica', 'Iris-versicolor']
desc_dict = {}
for i in classes:
desc_dict[i] = df[df.Species == i].describe()
df['Train'] = 'Train'
# random.randint returns a random integer N such that a <= N <= b
@transformation_function(pre = [])
def get_new_instance_for_this_class(x):
x.SepalLengthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['SepalLengthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['SepalLengthCm']].iloc[0,0], 2) * 100) / 100
x.SepalWidthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['SepalWidthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['SepalWidthCm']].iloc[0,0], 2) * 100) / 100
x.PetalLengthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['PetalLengthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['PetalLengthCm']].iloc[0,0], 2) * 100) / 100
x.PetalWidthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['PetalWidthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['PetalWidthCm']].iloc[0,0], 2) * 100) / 100
x.Train = 'Test'
return x
tfs = [ get_new_instance_for_this_class ]
random_policy = RandomPolicy(
len(tfs), sequence_length=2, n_per_original=1, keep_original=True
)
tf_applier = PandasTFApplier(tfs, random_policy)
df_train_augmented = tf_applier.apply(df)
print(f"Original training set size: {len(df)}")
print(f"Augmented training set size: {len(df_train_augmented)}")
Output:
Original training set size: 150
Augmented training set size: 300
df_test = df_train_augmented[df_train_augmented.Train == 'Test']
clf = svm.SVC(gamma = 'auto')
clf.fit(df[features], df['Species'])
Output:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
pred = clf.predict(df_test[features])
print("Accuracy: {:.3f}".format(accuracy_score(df_test['Species'], pred)))
print("Confusion matrix:\n{}".format(confusion_matrix(df_test['Species'], pred)))
features = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']
classes = ['Iris-setosa', 'Iris-virginica', 'Iris-versicolor']
desc_dict = {}
for i in classes:
desc_dict[i] = df[df.Species == i].describe()
df['Train'] = 'Train'
# random.randint returns a random integer N such that a <= N <= b
@transformation_function(pre = [])
def get_new_instance_for_this_class(x):
x.SepalLengthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['SepalLengthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['SepalLengthCm']].iloc[0,0], 2) * 100) / 100
x.SepalWidthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['SepalWidthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['SepalWidthCm']].iloc[0,0], 2) * 100) / 100
x.PetalLengthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['PetalLengthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['PetalLengthCm']].iloc[0,0], 2) * 100) / 100
x.PetalWidthCm = np.random.randint(round(desc_dict[x.Species].loc[['25%'], ['PetalWidthCm']].iloc[0,0], 2) * 100,
round(desc_dict[x.Species].loc[['75%'], ['PetalWidthCm']].iloc[0,0], 2) * 100) / 100
x.Train = 'Test'
return x
tfs = [ get_new_instance_for_this_class ]
random_policy = RandomPolicy(
len(tfs), sequence_length=2, n_per_original=1, keep_original=True
)
tf_applier = PandasTFApplier(tfs, random_policy)
df_train_augmented = tf_applier.apply(df)
print(f"Original training set size: {len(df)}")
print(f"Augmented training set size: {len(df_train_augmented)}")
Output:
Original training set size: 150
Augmented training set size: 300
df_test = df_train_augmented[df_train_augmented.Train == 'Test']
clf = svm.SVC(gamma = 'auto')
clf.fit(df[features], df['Species'])
Output:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
pred = clf.predict(df_test[features])
print("Accuracy: {:.3f}".format(accuracy_score(df_test['Species'], pred)))
print("Confusion matrix:\n{}".format(confusion_matrix(df_test['Species'], pred)))
 To confirm that we do not have an overlap in training and testing data:
left = df[features]
right = df_test[features]
print(left.merge(right, on = features, how = 'inner').shape)
Output:
(0, 4)
left = df[['Id']]
right = df_test[['Id']]
print(left.merge(right, on = ['Id'], how = 'inner').shape)
(150, 1)
To confirm that we do not have an overlap in training and testing data:
left = df[features]
right = df_test[features]
print(left.merge(right, on = features, how = 'inner').shape)
Output:
(0, 4)
left = df[['Id']]
right = df_test[['Id']]
print(left.merge(right, on = ['Id'], how = 'inner').shape)
(150, 1)
Friday, August 21, 2020
Using Snorkel, SpaCy to augment text data
We have some data that looks like this in a file "names.csv": names,text Harry Potter,Harry Potter is the protagonist. Ronald Weasley,Ronald Weasley is the chess expert. Hermione Granger,Hermione is the super witch. Hermione Granger,Hermione Granger weds Ron. We augment this data by replacing the names in the "text" column with new randomly selected different names. For this we write Python code as given below: import pandas as pd from collections import OrderedDict import numpy as np import names from snorkel.augmentation import transformation_function from snorkel.preprocess.nlp import SpacyPreprocessor spacy = SpacyPreprocessor(text_field="text", doc_field="doc", memoize=True) df = pd.read_csv('names.csv', encoding='cp1252') print(df.head()) print() # Pregenerate some random person names to replace existing ones with for the transformation strategies below replacement_names = [names.get_full_name() for _ in range(50)] # Replace a random named entity with a different entity of the same type. @transformation_function(pre=[spacy]) def change_person(x): person_names = [ent.text for ent in x.doc.ents if ent.label_ == "PERSON"] # If there is at least one person name, replace a random one. Else return None. if person_names: name_to_replace = np.random.choice(person_names) replacement_name = np.random.choice(replacement_names) x.text = x.text.replace(name_to_replace, replacement_name) return x tfs = [ change_person ] from snorkel.augmentation import RandomPolicy random_policy = RandomPolicy( len(tfs), sequence_length=2, n_per_original=1, keep_original=True ) from snorkel.augmentation import PandasTFApplier tf_applier = PandasTFApplier(tfs, random_policy) df_train_augmented = tf_applier.apply(df) print(f"Original training set size: {len(df)}") print(f"Augmented training set size: {len(df_train_augmented)}") print(df_train_augmented) print("\nDebugging for 'Hermione':\n") import spacy nlp = spacy.load('en_core_web_sm') def format_str(str, max_len = 25): str = str + " " * max_len return str[:max_len] for i, row in df.iterrows(): doc = nlp(row.text) for ent in doc.ents: # print(ent.text, ent.start_char, ent.end_char, ent.label_) print(format_str(ent.text), ent.label_) The Snorkel we are running is: (temp) E:\>conda list snorkel # packages in environment at E:\programfiles\Anaconda3\envs\temp: # # Name Version Build Channel snorkel 0.9.3 py_0 conda-forge Now, we run it in "Anaconda Prompt": (temp) E:\>python script.py names text 0 Harry Potter Harry Potter is the protagonist. 1 Ronald Weasley Ronald Weasley is the chess expert. 2 Hermione Granger Hermione is the super witch. 3 Hermione Granger Hermione Granger weds Ron. 100%|██████████| 4/4 [00:00<00:00, 34.58it/s] Original training set size: 4 Augmented training set size: 7 names text 0 Harry Potter Harry Potter is the protagonist. 0 Harry Potter Donald Gregoire is the protagonist. 1 Ronald Weasley Ronald Weasley is the chess expert. 1 Ronald Weasley John Hill is the chess expert. 2 Hermione Granger Hermione is the super witch. 3 Hermione Granger Hermione Granger weds Ron. 3 Hermione Granger Jonathan Humphrey weds Ron. Debugging for 'Hermione': Harry Potter PERSON Ronald Weasley PERSON Hermione ORG Hermione Granger PERSON Ron PERSON There is an error with the name "Hermione" (the red row above). Upon debugging we see that it is recognized as an 'Organization' and not a 'Person'.

Thursday, August 20, 2020
Using Conda to install and manage packages through YAML file and installing kernel
We are at path: E:\exp_snorkel\ File we are writing: env.yml CONTENTS OF THE YAML FILE FOR ENVIRONMENT: name: temp channels: - conda-forge dependencies: - pip - ca-certificates=2020.6.24=0 - matplotlib=3.1.1 - pip: - names==0.3.0 - nltk=3.4.5 - numpy>=1.16.0,<1.17.0 - pandas>=0.24.0,<0.25.0 - scikit-learn>=0.20.2 - spacy>=2.1.6,<2.2.0 - tensorflow=1.14.0 - textblob=0.15.3 prefix: E:\programfiles\Anaconda3\envs\temp WORKING IN THE CONDA SHELL: (base) E:\exp_snorkel>conda remove -n temp --all (base) E:\exp_snorkel>conda env create -f env.yml Warning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your conda dependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Please add an explicit pip dependency. I'm adding one for you, but still nagging you. Collecting package metadata (repodata.json): done Solving environment: done Preparing transaction: done Verifying transaction: done Executing transaction: done Installing pip dependencies: | Ran pip subprocess with arguments: ['E:\\programfiles\\Anaconda3\\envs\\temp\\python.exe', '-m', 'pip', 'install', '-U', '-r', 'E:\\exp_snorkel\\condaenv.m7xf9r2n.requirements.txt'] Pip subprocess output: Collecting names==0.3.0 Using cached names-0.3.0.tar.gz (789 kB) Building wheels for collected packages: names Building wheel for names (setup.py): started Building wheel for names (setup.py): finished with status 'done' Created wheel for names: filename=names-0.3.0-py3-none-any.whl size=803694 sha256=318443a7ae55ef0d24be16b374517a61494a29b2a0f0f07d164ab1ef058efb0a Stored in directory: c:\users\ashish jain\appdata\local\pip\cache\wheels\05\ea\68\92f6b0669e478af9b7c3c524520d03050089e034edcc775c2b Successfully built names Installing collected packages: names Successfully installed names-0.3.0 done # # To activate this environment, use # # $ conda activate temp # # To deactivate an active environment, use # # $ conda deactivate MANAGING A KERNEL: 1. Create a kernel: (base) E:\exp_snorkel>conda activate temp (temp) E:\exp_snorkel>pip install ipykernel jupyter (temp) E:\exp_snorkel>python -m ipykernel install --user --name temp 2. To remove a kernel from Jupyter Notebook: [Kernel name is "temp"] (base) E:\exp_snorkel>jupyter kernelspec uninstall temp 3. To view all installed kernels: (base) E:\exp_snorkel>jupyter kernelspec list Available kernels: temp C:\Users\Ashish Jain\AppData\Roaming\jupyter\kernels\temp python3 E:\programfiles\Anaconda3\share\jupyter\kernels\python3 Ref: docs.conda.io

Wednesday, August 19, 2020
Technology Listing related to web application security (Aug 2020)
1. Internet Message Access Protocol
In computing, the Internet Message Access Protocol (IMAP) is an Internet standard protocol used by email clients to retrieve email messages from a mail server over a TCP/IP connection. IMAP is defined by RFC 3501. IMAP was designed with the goal of permitting complete management of an email box by multiple email clients, therefore clients generally leave messages on the server until the user explicitly deletes them. An IMAP server typically listens on port number 143. IMAP over SSL (IMAPS) is assigned the port number 993. Virtually all modern e-mail clients and servers support IMAP, which along with the earlier POP3 (Post Office Protocol) are the two most prevalent standard protocols for email retrieval. Many webmail service providers such as Gmail, Outlook.com and Yahoo! Mail also provide support for both IMAP and POP3. Email protocols The Internet Message Access Protocol is an Application Layer Internet protocol that allows an e-mail client to access email on a remote mail server. The current version is defined by RFC 3501. An IMAP server typically listens on well-known port 143, while IMAP over SSL (IMAPS) uses 993. Incoming email messages are sent to an email server that stores messages in the recipient's email box. The user retrieves the messages with an email client that uses one of a number of email retrieval protocols. While some clients and servers preferentially use vendor-specific, proprietary protocols, almost all support POP and IMAP for retrieving email – allowing many free choice between many e-mail clients such as Pegasus Mail or Mozilla Thunderbird to access these servers, and allows the clients to be used with other servers. Email clients using IMAP generally leave messages on the server until the user explicitly deletes them. This and other characteristics of IMAP operation allow multiple clients to manage the same mailbox. Most email clients support IMAP in addition to Post Office Protocol (POP) to retrieve messages. IMAP offers access to the mail storage. Clients may store local copies of the messages, but these are considered to be a temporary cache. Ref: Wikipedia - IMAP2. Kerberos (krb5)
Kerberos (/ˈkɜːrbərɒs/) is a computer-network authentication protocol that works on the basis of tickets to allow nodes communicating over a non-secure network to prove their identity to one another in a secure manner. The protocol was named after the character Kerberos (or Cerberus) from Greek mythology, the ferocious three-headed guard dog of Hades. Its designers aimed it primarily at a client–server model and it provides mutual authentication—both the user and the server verify each other's identity. Kerberos protocol messages are protected against eavesdropping and replay attacks. Kerberos builds on symmetric key cryptography and requires a trusted third party, and optionally may use public-key cryptography during certain phases of authentication. Kerberos uses UDP port 88 by default. Ref: Kerberos3. Securing Java Enterprise Apps (Spring Security)
Spring Security is a Java/Java EE framework that provides authentication, authorization and other security features for enterprise applications. Key authentication features % LDAP (using both bind-based and password comparison strategies) for centralization of authentication information. % Single sign-on capabilities using the popular Central Authentication Service. % Java Authentication and Authorization Service (JAAS) LoginModule, a standards-based method for authentication used within Java. Note this feature is only a delegation to a JAAS Loginmodule. % Basic access authentication as defined through RFC 1945. % Digest access authentication as defined through RFC 2617 and RFC 2069. % X.509 client certificate presentation over the Secure Sockets Layer standard. % CA, Inc SiteMinder for authentication (a popular commercial access management product). % Su (Unix)-like support for switching principal identity over a HTTP or HTTPS connection. % Run-as replacement, which enables an operation to assume a different security identity. % Anonymous authentication, which means that even unauthenticated principals are allocated a security identity. % Container adapter (custom realm) support for Apache Tomcat, Resin, JBoss and Jetty (web server). % Windows NTLM to enable browser integration (experimental). % Web form authentication, similar to the servlet container specification. % "Remember-me" support via HTTP cookies. % Concurrent session support, which limits the number of simultaneous logins permitted by a principal. % Full support for customization and plugging in custom authentication implementations. Ref: Spring Security4. LDAP (Lightweight Directory Access Protocol)
The Lightweight Directory Access Protocol (LDAP /ˈɛldæp/) is an open, vendor-neutral, industry standard application protocol for accessing and maintaining distributed directory information services over an Internet Protocol (IP) network. Directory services play an important role in developing intranet and Internet applications by allowing the sharing of information about users, systems, networks, services, and applications throughout the network. As examples, directory services may provide any organized set of records, often with a hierarchical structure, such as a corporate email directory. Similarly, a telephone directory is a list of subscribers with an address and a phone number. LDAP is specified in a series of Internet Engineering Task Force (IETF) Standard Track publications called Request for Comments (RFCs), using the description language ASN.1. The latest specification is Version 3, published as RFC 4511 (a road map to the technical specifications is provided by RFC4510). A common use of LDAP is to provide a central place to store usernames and passwords. This allows many different applications and services to connect to the LDAP server to validate users. LDAP is based on a simpler subset of the standards contained within the X.500 standard. Because of this relationship, LDAP is sometimes called X.500-lite. Ref: LDAP (Lightweight Directory Access Protocol)5. Keycloak
Keycloak is an open source software product to allow single sign-on with Identity Management and Access Management aimed at modern applications and services. As of March 2018 this JBoss community project is under the stewardship of Red Hat who use it as the upstream project for their RH-SSO product. Features: Among the many features of Keycloak include : % User Registration % Social login % Single Sign-On/Sign-Off across all applications belonging to the same Realm % 2-factor authentication % LDAP integration % Kerberos broker % multitenancy with per-realm customizeable skin Components: There are 2 main components of Keycloak: % Keycloak server % Keycloak application adapter Ref: Keycloak6. OAuth
OAuth is an open standard for access delegation, commonly used as a way for Internet users to grant websites or applications access to their information on other websites but without giving them the passwords. This mechanism is used by companies such as Amazon, Google, Facebook, Microsoft and Twitter to permit the users to share information about their accounts with third party applications or websites. Generally, OAuth provides clients a "secure delegated access" to server resources on behalf of a resource owner. It specifies a process for resource owners to authorize third-party access to their server resources without sharing their credentials. Designed specifically to work with Hypertext Transfer Protocol (HTTP), OAuth essentially allows access tokens to be issued to third-party clients by an authorization server, with the approval of the resource owner. The third party then uses the access token to access the protected resources hosted by the resource server. OAuth is a service that is complementary to and distinct from OpenID. OAuth is unrelated to OATH, which is a reference architecture for authentication, not a standard for authorization. However, OAuth is directly related to OpenID Connect (OIDC), since OIDC is an authentication layer built on top of OAuth 2.0. OAuth is also unrelated to XACML, which is an authorization policy standard. OAuth can be used in conjunction with XACML, where OAuth is used for ownership consent and access delegation whereas XACML is used to define the authorization policies (e.g., managers can view documents in their region). Ref: OAuth7. OpenID
OpenID is an open standard and decentralized authentication protocol. Promoted by the non-profit OpenID Foundation, it allows users to be authenticated by co-operating sites (known as relying parties, or RP) using a third-party service, eliminating the need for webmasters to provide their own ad hoc login systems, and allowing users to log into multiple unrelated websites without having to have a separate identity and password for each. Users create accounts by selecting an OpenID identity provider and then use those accounts to sign onto any website that accepts OpenID authentication. Several large organizations either issue or accept OpenIDs on their websites, according to the OpenID Foundation. The OpenID standard provides a framework for the communication that must take place between the identity provider and the OpenID acceptor (the "relying party"). An extension to the standard (the OpenID Attribute Exchange) facilitates the transfer of user attributes, such as name and gender, from the OpenID identity provider to the relying party (each relying party may request a different set of attributes, depending on its requirements). The OpenID protocol does not rely on a central authority to authenticate a user's identity. Moreover, neither services nor the OpenID standard may mandate a specific means by which to authenticate users, allowing for approaches ranging from the common (such as passwords) to the novel (such as smart cards or biometrics). The final version of OpenID is OpenID 2.0, finalized and published in December 2007. The term OpenID may also refer to an identifier as specified in the OpenID standard; these identifiers take the form of a unique Uniform Resource Identifier (URI), and are managed by some "OpenID provider" that handles authentication. OpenID vs OAuth:The Top 10 OWASP vulnerabilities in 2020 are: % Injection % Broken Authentication % Sensitive Data Exposure % XML External Entities (XXE) % Broken Access control % Security misconfigurations % Cross Site Scripting (XSS) % Insecure Deserialization % Using Components with known vulnerabilities % Insufficient logging and monitoring Ref (a): OpenID Ref (b): Top 10 Security Vulnerabilities in 20208. Heroku
Heroku is a cloud platform as a service (PaaS) supporting several programming languages. One of the first cloud platforms, Heroku has been in development since June 2007, when it supported only the Ruby programming language, but now supports Java, Node.js, Scala, Clojure, Python, PHP, and Go. For this reason, Heroku is said to be a polyglot platform as it has features for a developer to build, run and scale applications in a similar manner across most languages. Heroku was acquired by Salesforce.com in 2010 for $212 million. Ref: Heroku9. Facebook Prophet
Prophet is a procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and several seasons of historical data. Prophet is robust to missing data and shifts in the trend, and typically handles outliers well. Prophet is open source software released by Facebook’s Core Data Science team. It is available for download on CRAN and PyPI. % CRAN is a network of ftp and web servers around the world that store identical, up-to-date, versions of code and documentation for R. Link: https://cran.r-project.org/ The Prophet procedure includes many possibilities for users to tweak and adjust forecasts. You can use human-interpretable parameters to improve your forecast by adding your domain knowledge. Ref: Facebook.github.io10. Snorkel
% Programmatically Build Training Data The Snorkel team is now focusing their efforts on Snorkel Flow, an end-to-end AI application development platform based on the core ideas behind Snorkel. The Snorkel project started at Stanford in 2016 with a simple technical bet: that it would increasingly be the training data, not the models, algorithms, or infrastructure, that decided whether a machine learning project succeeded or failed. Given this premise, we set out to explore the radical idea that you could bring mathematical and systems structure to the messy and often entirely manual process of training data creation and management, starting by empowering users to programmatically label, build, and manage training data. To say that the Snorkel project succeeded and expanded beyond what we had ever expected would be an understatement. The basic goals of a research repo like Snorkel are to provide a minimum viable framework for testing and validating hypotheses. Snorkel Related innovations are in weak supervision modeling, data augmentation, multi-task learning, and more. The ideas behind Snorkel change not just how you label training data, but so much of the entire lifecycle and pipeline of building, deploying, and managing ML: how users inject their knowledge; how models are constructed, trained, inspected, versioned, and monitored; how entire pipelines are developed iteratively; and how the full set of stakeholders in any ML deployment, from subject matter experts to ML engineers, are incorporated into the process. Over the last year, we have been building the platform to support this broader vision: Snorkel Flow, an end-to-end machine learning platform for developing and deploying AI applications. Snorkel Flow incorporates many of the concepts of the Snorkel project with a range of newer techniques around weak supervision modeling, data augmentation, multi-task learning, data slicing and structuring, monitoring and analysis, and more, all of which integrate in a way that is greater than the sum of its parts–and that we believe makes ML truly faster, more flexible, and more practical than ever before. Ref: snorkel.org


Subscribe to:
Posts (Atom)