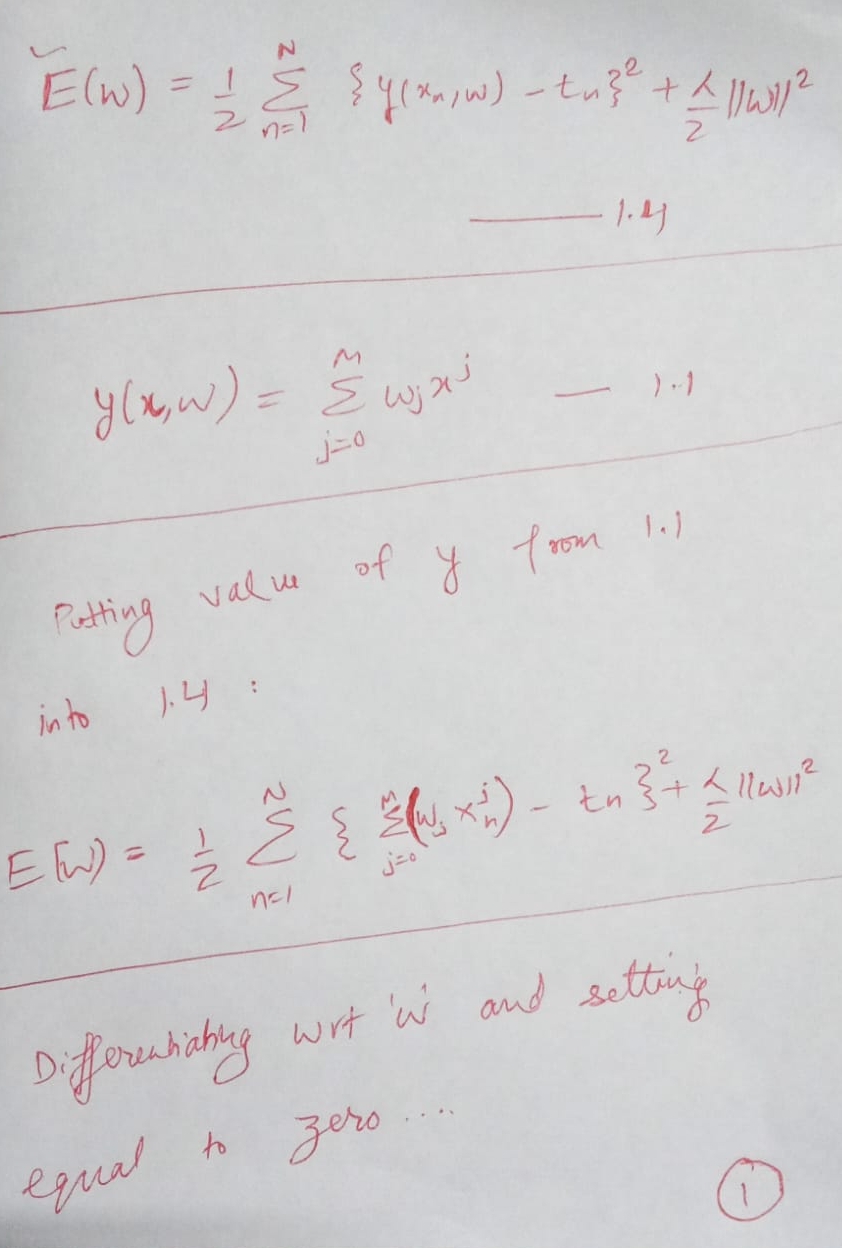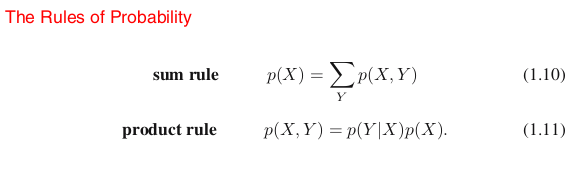Let's quiz you for the basic concepts of probability theory by considering a simple example.
Imagine we have two boxes, one red and one blue, and in the red box we have 2 apples and 6 oranges, and in the blue box we have 3 apples and 1 orange.
This is illustrated in Figure 1.9. Now suppose we randomly pick one of the boxes and from that box we randomly select an item of fruit, and having observed which sort of fruit it is we replace it in the box from which it came. We could imagine repeating this process many times.
Let us suppose that in so doing we pick the red box 40% of the time and we pick the blue box 60% of the time, and that when we remove an item of fruit from a box we are equally likely to select any of the pieces of fruit in the box.
In this example, the identity of the box that will be chosen is a random variable, which we shall denote by B. This random variable can take one of two possible values, namely r (corresponding to the red box) or b (corresponding to the blue box). Similarly, the identity of the fruit is also a random variable and will be denoted by F . It can take either of the values a (for apple) or o (for orange).
To begin with, we shall define the probability of an event to be the fraction of times that event occurs out of the total number of trials, in the limit that the total number of trials goes to infinity. Thus the probability of selecting the red box is 4/10 and the probability of selecting the blue box is 6/10. We write these probabilities as:
p(B = r) = 4/10 and p(B = b) = 6/10.
Note that, by definition, probabilities must lie in the interval [0, 1]. Also, if the events are mutually exclusive and if they include all possible outcomes (for instance, in this example the box must be either red or blue), then we see that the probabilities for those events must sum to one.
We can now ask questions such as:
“what is the overall probability that the selection procedure will pick an apple?”,
or
“given that we have chosen an orange, what's the probability that the box we chose was the blue one?”
We can answer questions such as these, and indeed much more complex questions associated with
problems in pattern recognition, once we have equipped ourselves with the two elementary rules of probability, known as the sum rule and the product rule.
Sum Rule and Product Rule
Here p(X, Y ) is a joint probability and is verbalized as “the probability of X and Y ”. Similarly, the quantity p(Y |X) is a conditional probability and is verbalized as “the probability of Y given X”, whereas the quantity p(X) is a marginal probability and is simply “the probability of X”.
Let us now return to our example involving boxes of fruit. For the moment, we
shall once again be explicit about distinguishing between the random variables and
their instantiations. We have seen that the probabilities of selecting either the red or
the blue boxes are given by
p(B = r) = 4/10
p(B = b) = 6/10
respectively. Note that these satisfy p(B = r) + p(B = b) = 1.
Now suppose that we pick a box at random, and it turns out to be the blue box.
Then the probability of selecting an apple is just the fraction of apples in the blue
box which is 3/4, and so p(F = a|B = b) = 3/4. In fact, we can write out all four
conditional probabilities for the type of fruit, given the selected box
p(F = a|B = r) = 1/4
p(F = o|B = r) = 3/4
p(F = a|B = b) = 3/4
p(F = o|B = b) = 1/4
Practice Exercise
Suppose that we have three coloured boxes r (red), b (blue), and g (green).
Box r contains 3 apples, 4 oranges, and 3 limes, box b contains 1 apple, 1 orange, and 0 limes, and box g contains 3 apples, 3 oranges, and 4 limes. If a box is chosen at random with probabilities p(r) = 0.2, p(b) = 0.2, p(g) = 0.6, and a piece of fruit is removed from the box (with equal probability of selecting any of the items in the box), then what is the probability of selecting an apple?
If we observe that the selected fruit is in fact an orange, what is the probability that it came from the green box?
Solution
Ref: ChatGPT








 Solution for problem 1.2: Pg 1:
Solution for problem 1.2: Pg 1: Pg 2:
Pg 2: Pg 3:
Pg 3: Pg 4:
Pg 4:

 Here p(X, Y ) is a joint probability and is verbalized as “the probability of X and Y ”. Similarly, the quantity p(Y |X) is a conditional probability and is verbalized as “the probability of Y given X”, whereas the quantity p(X) is a marginal probability and is simply “the probability of X”.
Let us now return to our example involving boxes of fruit. For the moment, we
shall once again be explicit about distinguishing between the random variables and
their instantiations. We have seen that the probabilities of selecting either the red or
the blue boxes are given by
p(B = r) = 4/10
p(B = b) = 6/10
respectively. Note that these satisfy p(B = r) + p(B = b) = 1.
Now suppose that we pick a box at random, and it turns out to be the blue box.
Then the probability of selecting an apple is just the fraction of apples in the blue
box which is 3/4, and so p(F = a|B = b) = 3/4. In fact, we can write out all four
conditional probabilities for the type of fruit, given the selected box
p(F = a|B = r) = 1/4
p(F = o|B = r) = 3/4
p(F = a|B = b) = 3/4
p(F = o|B = b) = 1/4
Here p(X, Y ) is a joint probability and is verbalized as “the probability of X and Y ”. Similarly, the quantity p(Y |X) is a conditional probability and is verbalized as “the probability of Y given X”, whereas the quantity p(X) is a marginal probability and is simply “the probability of X”.
Let us now return to our example involving boxes of fruit. For the moment, we
shall once again be explicit about distinguishing between the random variables and
their instantiations. We have seen that the probabilities of selecting either the red or
the blue boxes are given by
p(B = r) = 4/10
p(B = b) = 6/10
respectively. Note that these satisfy p(B = r) + p(B = b) = 1.
Now suppose that we pick a box at random, and it turns out to be the blue box.
Then the probability of selecting an apple is just the fraction of apples in the blue
box which is 3/4, and so p(F = a|B = b) = 3/4. In fact, we can write out all four
conditional probabilities for the type of fruit, given the selected box
p(F = a|B = r) = 1/4
p(F = o|B = r) = 3/4
p(F = a|B = b) = 3/4
p(F = o|B = b) = 1/4





 Ref: ChatGPT
Ref: ChatGPT