We are having a very simple tabular data that we have generated programmatically with the following structure:

| investorID | pcSoldAtProfit | pcHeldAtLoss | dispBias | |
|---|---|---|---|---|
| 0 | 29 | 0.17 | 0.89 | n |
| 1 | 68 | 0.16 | 0.08 | n |
| 2 | 23 | 0.97 | 0.07 | n |
| 3 | 80 | 0.20 | 0.67 | n |
| 4 | 2 | 0.74 | 0.77 | y |
Here, features are "pcSoldAtProfit" and "pcHeldAtLoss", and target variable is "dispBias".
The simple rule for generating this data is "if pcSoldAtProfit and pcHeldAtLoss are both greater than 0.7 then
dispBias is 'y' else dispBias is 'n'".
This rule is so straightforward that even a human would be able to guess it by looking at the few samples of
data but now lets look at how Decision Tree algorithm performs on various sizes of this data...
With 100 rows and splitting at 25%:
We see here that algorithm failed to classify 3 instances of the test data.
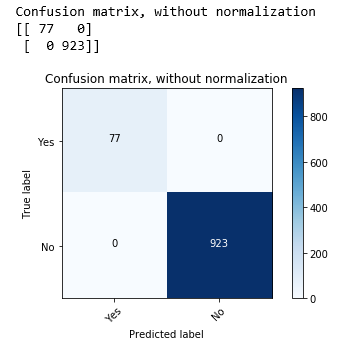
And this does not get any better until we increase the data points count to 10000 (with splitting at 10%):
So we conclude that even for very simple learning an ML algorithm needs huge amounts of training data.
No comments:
Post a Comment