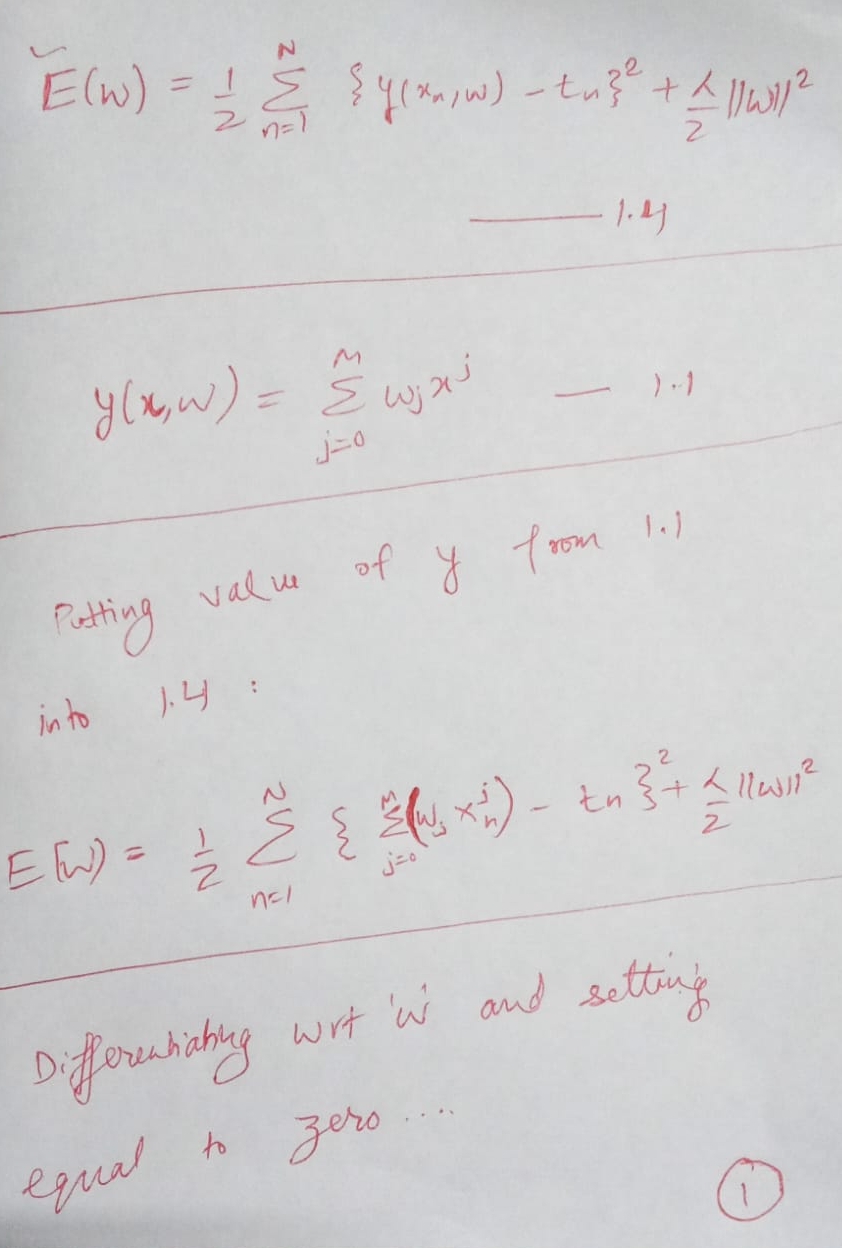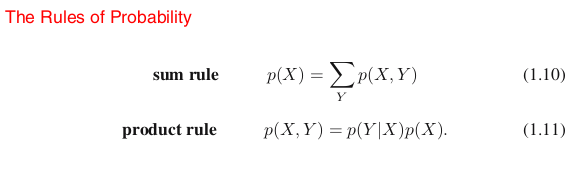Pre-read for exercise 1.2:Problem 1.2: Solution for problem 1.2: Pg 1:
Solution for problem 1.2: Pg 1: Pg 2:
Pg 2: Pg 3:
Pg 3: Pg 4:
Pg 4:

Pre-read for exercise 1.2:Problem 1.2:Solution for problem 1.2: Pg 1:Pg 2:Pg 3:Pg 4:
Let's quiz you for the basic concepts of probability theory by considering a simple example.
Imagine we have two boxes, one red and one blue, and in the red box we have 2 apples and 6 oranges, and in the blue box we have 3 apples and 1 orange.
This is illustrated in Figure 1.9. Now suppose we randomly pick one of the boxes and from that box we randomly select an item of fruit, and having observed which sort of fruit it is we replace it in the box from which it came. We could imagine repeating this process many times.
Let us suppose that in so doing we pick the red box 40% of the time and we pick the blue box 60% of the time, and that when we remove an item of fruit from a box we are equally likely to select any of the pieces of fruit in the box.
In this example, the identity of the box that will be chosen is a random variable, which we shall denote by B. This random variable can take one of two possible values, namely r (corresponding to the red box) or b (corresponding to the blue box). Similarly, the identity of the fruit is also a random variable and will be denoted by F . It can take either of the values a (for apple) or o (for orange).
To begin with, we shall define the probability of an event to be the fraction of times that event occurs out of the total number of trials, in the limit that the total number of trials goes to infinity. Thus the probability of selecting the red box is 4/10 and the probability of selecting the blue box is 6/10. We write these probabilities as:
p(B = r) = 4/10 and p(B = b) = 6/10.
Note that, by definition, probabilities must lie in the interval [0, 1]. Also, if the events are mutually exclusive and if they include all possible outcomes (for instance, in this example the box must be either red or blue), then we see that the probabilities for those events must sum to one.
We can now ask questions such as:
“what is the overall probability that the selection procedure will pick an apple?”,
or
“given that we have chosen an orange, what's the probability that the box we chose was the blue one?”
We can answer questions such as these, and indeed much more complex questions associated with
problems in pattern recognition, once we have equipped ourselves with the two elementary rules of probability, known as the sum rule and the product rule.
Sum Rule and Product Rule
 Here p(X, Y ) is a joint probability and is verbalized as “the probability of X and Y ”. Similarly, the quantity p(Y |X) is a conditional probability and is verbalized as “the probability of Y given X”, whereas the quantity p(X) is a marginal probability and is simply “the probability of X”.
Let us now return to our example involving boxes of fruit. For the moment, we
shall once again be explicit about distinguishing between the random variables and
their instantiations. We have seen that the probabilities of selecting either the red or
the blue boxes are given by
p(B = r) = 4/10
p(B = b) = 6/10
respectively. Note that these satisfy p(B = r) + p(B = b) = 1.
Now suppose that we pick a box at random, and it turns out to be the blue box.
Then the probability of selecting an apple is just the fraction of apples in the blue
box which is 3/4, and so p(F = a|B = b) = 3/4. In fact, we can write out all four
conditional probabilities for the type of fruit, given the selected box
p(F = a|B = r) = 1/4
p(F = o|B = r) = 3/4
p(F = a|B = b) = 3/4
p(F = o|B = b) = 1/4
Here p(X, Y ) is a joint probability and is verbalized as “the probability of X and Y ”. Similarly, the quantity p(Y |X) is a conditional probability and is verbalized as “the probability of Y given X”, whereas the quantity p(X) is a marginal probability and is simply “the probability of X”.
Let us now return to our example involving boxes of fruit. For the moment, we
shall once again be explicit about distinguishing between the random variables and
their instantiations. We have seen that the probabilities of selecting either the red or
the blue boxes are given by
p(B = r) = 4/10
p(B = b) = 6/10
respectively. Note that these satisfy p(B = r) + p(B = b) = 1.
Now suppose that we pick a box at random, and it turns out to be the blue box.
Then the probability of selecting an apple is just the fraction of apples in the blue
box which is 3/4, and so p(F = a|B = b) = 3/4. In fact, we can write out all four
conditional probabilities for the type of fruit, given the selected box
p(F = a|B = r) = 1/4
p(F = o|B = r) = 3/4
p(F = a|B = b) = 3/4
p(F = o|B = b) = 1/4


Practice Exercise
Suppose that we have three coloured boxes r (red), b (blue), and g (green).
Box r contains 3 apples, 4 oranges, and 3 limes, box b contains 1 apple, 1 orange, and 0 limes, and box g contains 3 apples, 3 oranges, and 4 limes. If a box is chosen at random with probabilities p(r) = 0.2, p(b) = 0.2, p(g) = 0.6, and a piece of fruit is removed from the box (with equal probability of selecting any of the items in the box), then what is the probability of selecting an apple?
If we observe that the selected fruit is in fact an orange, what is the probability that it came from the green box?
Solution



 Ref: ChatGPT
Ref: ChatGPT
Pre-read
Fig:1Fig:2Fig:3If we have several continuous variables x1,...,xD, denoted collectively by the vector x, then we can define a joint probability density p(x) = p(x1,...,xD) such Fig:4Question
Fig:5Solution


Pre-read

1.5: Using the definition (1.38) show that var[f(x)] satisfies (1.39).
Solution

Pre-read
Fig 1Fig 2

1.6: Show that if two variables x and y are independent, then their covariance is zero.
Solution
Fig 3Fig 4













Choropleth: A choropleth map is a type of statistical thematic map that uses pseudocolor, i.e., color corresponding with an aggregate summary of a geographic characteristic within spatial enumeration units, such as population density or per-capita income.
Cartography: the science or practice of drawing maps.

You are given a non-empty, zero-indexed array A of n (1 <= n <= 100000) integers a0, a1,..., an−1 (0 <= ai <= 1000). This array represents number of mushrooms growing on the consecutive spots along a road. You are also given integers k and m (0 <= k, m < n).
A mushroom picker is at spot number k on the road and should perform m moves. In one move she moves to an adjacent spot. She collects all the mushrooms growing on spots
she visits. The goal is to calculate the maximum number of mushrooms that the mushroom
picker can collect in m moves.
For example, consider array A such that:
A[0]=2, A[1]=3, A[2]=7, A[3]=5, A[4]=1, A[5]=3, A[6]=9
The mushroom picker starts at spot k = 4 and should perform m = 6 moves. She might
move to spots 3, 2, 3, 4, 5, 6 and thereby collect 1 + 5 + 7 + 3 + 9 = 25 mushrooms. This is the
maximal number of mushrooms she can collect.
# Counting prefix sums
def prefix_sums(A):
n = len(A)
P = [0] * (n + 1)
for k in xrange(1, n + 1):
P[k] = P[k - 1] + A[k - 1]
return P
# Total of one slice
def count_total(P, x, y):
return P[y + 1] - P[x]
# Mushroom picker — O(n + m)
def mushrooms(A, k, m):
n = len(A)
result = 0
pref = prefix_sums(A)
# When we first take p steps on the left and return from their back in right direction.
for p in xrange(min(m, k) + 1):
left_pos = k - p
right_pos = min(n - 1, max(k, k + m - 2*p))
result = max(result, count_total(pref, left_pos, right_pos))
# When we first take p steps on the right and return from their back in left direction.
for p in xrange(min(m + 1, n - k)):
right_pos = k + p
left_pos = max(0, min(k, k - (m - 2*p)))
result=max(result, count_total(pref, left_pos, right_pos))
return result
# When we first take p steps on the left and return from their back in right direction.
for p in xrange(min(m, k) + 1):
left_pos = k - p
right_pos = min(n - 1, max(k, k + m - 2*p))
result = max(result, count_total(pref, left_pos, right_pos))
Expression “for p in xrange(min(m, k) + 1)” has min(m, k) because we can only go m steps to the left or k steps to the left whichever number is minimum.
After going k steps, we cannot go past 0th position.
Or after taking m steps, we cannot take another step.
Expression “right_pos = min(n - 1, max(k, k + m – 2*p))” has ‘k+m-2*p’ because after taking p steps to the left, we are returning p steps back to position k, hence 2p.
And then number of steps left is: m – 2p
Then right position is identified by: m-2p steps after k ie, k+m-2p
Expression “right_pos = min(n - 1, max(k, k + m – 2*p))” has max(k, k + m – 2*p) because what if we take all the m steps to left and value of p becomes m.
Then there are no steps left to take to the right and right position is simply identified by k.
Similarly, for any value of p > m/2 (as in 0.6m or 0.75m), we would get same right position as k.
# When we first take p steps on the right and return from their back in left direction.
for p in xrange(min(m + 1, n - k)):
right_pos = k + p
left_pos = max(0, min(k, k - (m - 2*p)))
result = max(result, count_total(pref, left_pos, right_pos))
Here in the expression “for p in xrange(min(m + 1, n – k))”, we have m+1 and not just m because xrange goes till m when passed the argument m+1. Similarly, we have n-k and not (n-1)-k because xrange goes till (n-1)-k when passed the argument n-k.
And we take minimum of m or (n-1)-k because that’s is the possible number of steps we can take on the right.
Here in the expression “left_pos = max(0, min(k, k - (m – 2*p)))”, we have k-(m-2p) because we take p steps on the right, then take those p steps back to k (on the left now).
Number of steps yet to take: m-2p
Left position would be identified by: k-(m-2p)
If p takes value m, which means we have taken m steps on the right, then we have no steps remaining to take to the left and left position is identified by k itself. (This logic is valid for any value of p > m/2)
def get_mushrooms_sum(A, start, end): return sum(A[start : end + 1])