Heroku Dashboard URL: https://dashboard.heroku.com/appsWe have two projects hosted on Heroku Cloud: 1. polar-mountain-... 2. rocky-spire-... We would open the settings for "rocky-spire". https://dashboard.heroku.com/apps/rocky-spire-96801/settings Project "Settings"Even if somebody has your project name and 'git.heroku.com' link, the project is safe and protected by a login prompt as shown below:If you want to see additional settings, they appear below on the page such as in these screenshots:Additional Settings to 'Transfer App Ownership', 'Turn on Maintenance Mode' and 'Delete App':'rocky-spire' Resources https://dashboard.heroku.com/apps/rocky-spire-96801/resourcesIf you have an 'Add-On' such as a Postgres Database, it will also show up in 'Resources' Tab:'Deployment' Tab https://dashboard.heroku.com/apps/rocky-spire-96801/deploy/heroku-git'Activity' Tab https://dashboard.heroku.com/apps/rocky-spire-96801/activity'Access' Tab https://dashboard.heroku.com/apps/rocky-spire-96801/access'Overview' Tab https://dashboard.heroku.com/apps/rocky-spire-96801Note: An app hosted on Heroku may not have a 'Homepage' but may show content via an API endpoint. See images below: For URL: https://rocky-spire-96801.herokuapp.com/For URL: https://rocky-spire-96801.herokuapp.com/tracksInteresting Fact: When type "abc..." and hit enter in Visual Studio Code, the VS Code auto-completes this 'abc...' to "<abc class=''></abc>"
Monday, October 19, 2020
Heroku Dashboard And Settings

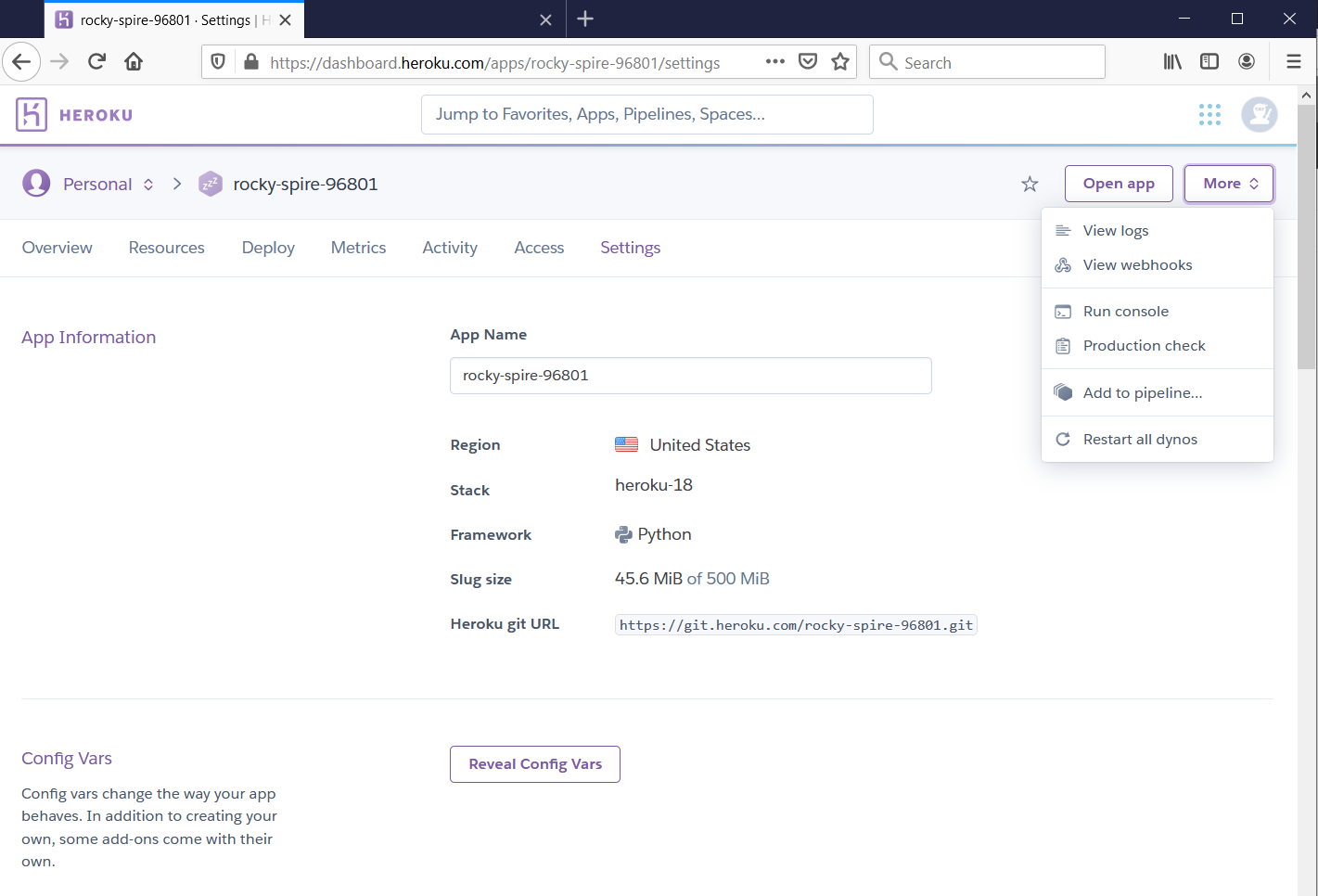















Sunday, October 18, 2020
Data Visualization's Basic Theory
DefinitionWhy should we be interested in visualization? Abelas' Chart Selection Diagram
Abelas' Chart Selection Diagram Some principles of effective visualizations
Some principles of effective visualizations Basic components of every chart
Basic components of every chart Combo-chart: Line plot, Column chart (or Bar graph) combined
Combo-chart: Line plot, Column chart (or Bar graph) combined Comba-chart: Stacked Column Chart
Comba-chart: Stacked Column Chart Heat Maps
Heat Maps Grouped Column Chart and Stacked Column Chart: For doing data comparison
Grouped Column Chart and Stacked Column Chart: For doing data comparison












Thursday, October 15, 2020
BERT is aware of the context of a word in a sentence
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.metrics.pairwise import cosine_similarity
import torch
import transformers as ppb
import warnings
warnings.filterwarnings('ignore')
from joblib import load, dump
import json
import re
print(ppb.__version__)
'3.0.1'
Loading the Pre-trained BERT model
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
# Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
When run first time, the above statements loads a model of 440MB in size.
Word Ambiguities
def get_embedding(in_list):
tokenized = [tokenizer.encode(x, add_special_tokens=True) for x in in_list]
max_len = 0
for i in tokenized:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0]*(max_len-len(i)) for i in tokenized])
attention_mask = np.where(padded != 0, 1, 0)
input_ids = torch.LongTensor(padded)
attention_mask = torch.tensor(attention_mask)
with torch.no_grad():
last_hidden_states = model(input_ids = input_ids, attention_mask = attention_mask)
features = last_hidden_states[0][:,0,:].numpy()
return features
python_strings = [
'I love coding in Python language.',
'Python is more readable than Java.',
'Pythons are famous for their very long body.',
'Python is famous for its very long body.',
'All six continents have a python species.',
'Python is a programming language.',
'Python is a reptile.',
'The python ate a mouse.',
'python ate a mouse'
]
string_embeddings = get_embedding(python_strings)
print(string_embeddings.shape)
(9, 768)
csm = cosine_similarity(X = string_embeddings, Y=None, dense_output=True)
print(csm.round(2))
In the picture below, if we ignore the diagnol (that is similarity of a sentence to itself), we are able to see which sentence is closer to which.
[[1. 0.83 0.8 0.79 0.8 0.84 0.84 0.81 0.81]
[0.83 1. 0.79 0.76 0.8 0.87 0.79 0.8 0.79]
[0.8 0.79 1. 0.96 0.86 0.77 0.88 0.77 0.78]
[0.79 0.76 0.96 1. 0.82 0.77 0.9 0.75 0.77]
[0.8 0.8 0.86 0.82 1. 0.78 0.85 0.8 0.8 ]
[0.84 0.87 0.77 0.77 0.78 1. 0.81 0.76 0.78]
[0.84 0.79 0.88 0.9 0.85 0.81 1. 0.81 0.86]
[0.81 0.8 0.77 0.75 0.8 0.76 0.81 1. 0.9 ]
[0.81 0.79 0.78 0.77 0.8 0.78 0.86 0.9 1. ]]
for i in range(len(csm)):
ord_indx = np.argsort(csm[i])[::-1]
print(python_strings[ord_indx[0]])
print([python_strings[j] for j in ord_indx[1:]])
print()
I love coding in Python language.
['Python is a reptile.', 'Python is a programming language.', 'Python is more readable than Java.', 'python ate a mouse', 'The python ate a mouse.', 'All six continents have a python species.', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.']
Python is more readable than Java.
['Python is a programming language.', 'I love coding in Python language.', 'All six continents have a python species.', 'The python ate a mouse.', 'Python is a reptile.', 'python ate a mouse', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.']
Pythons are famous for their very long body.
['Python is famous for its very long body.', 'Python is a reptile.', 'All six continents have a python species.', 'I love coding in Python language.', 'Python is more readable than Java.', 'python ate a mouse', 'Python is a programming language.', 'The python ate a mouse.']
Python is famous for its very long body.
['Pythons are famous for their very long body.', 'Python is a reptile.', 'All six continents have a python species.', 'I love coding in Python language.', 'python ate a mouse', 'Python is a programming language.', 'Python is more readable than Java.', 'The python ate a mouse.']
All six continents have a python species.
['Pythons are famous for their very long body.', 'Python is a reptile.', 'Python is famous for its very long body.', 'I love coding in Python language.', 'Python is more readable than Java.', 'The python ate a mouse.', 'python ate a mouse', 'Python is a programming language.']
Python is a programming language.
['Python is more readable than Java.', 'I love coding in Python language.', 'Python is a reptile.', 'All six continents have a python species.', 'python ate a mouse', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.', 'The python ate a mouse.']
Python is a reptile.
['Python is famous for its very long body.', 'Pythons are famous for their very long body.', 'python ate a mouse', 'All six continents have a python species.', 'I love coding in Python language.', 'Python is a programming language.', 'The python ate a mouse.', 'Python is more readable than Java.']
The python ate a mouse.
['python ate a mouse', 'I love coding in Python language.', 'Python is a reptile.', 'All six continents have a python species.', 'Python is more readable than Java.', 'Pythons are famous for their very long body.', 'Python is a programming language.', 'Python is famous for its very long body.']
python ate a mouse
['The python ate a mouse.', 'Python is a reptile.', 'I love coding in Python language.', 'All six continents have a python species.', 'Python is more readable than Java.', 'Python is a programming language.', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.']
Few observations
1. "python ate a mouse" is more closer to "Python is a reptile." than "The python ate a mouse."
For closeness of these sentences to "Python is a reptile" shows "python ate a mouse" at number 3 while "The python ate a mouse" appears at number 7.
2. The model we are using is "uncased" so capitalization does not matter.
3. Sentences about Python language are similar to each other, and sentences about Python reptile are similar to each other.
4. Word "python" or "Python" alone is closest to 'I love coding in Python language.' then to 'Python is a reptile.', see code snippet below.
from scipy.spatial import distance
python_embedding = get_embedding('python')
csm = [1 - distance.cosine(u = python_embedding[0], v = i) for i in string_embeddings]
print([python_strings[j] for j in np.argsort(csm)[::-1]])
['I love coding in Python language.',
'Python is a reptile.',
'python ate a mouse',
'The python ate a mouse.',
'All six continents have a python species.',
'Python is a programming language.',
'Python is more readable than Java.',
'Python is famous for its very long body.',
'Pythons are famous for their very long body.']
Wednesday, October 14, 2020
Compare pip and conda installations
1. View all environments. (base) C:\Users\aj>conda env list # conda environments: # base * D:\programfiles\Anaconda3 bert_aas D:\programfiles\Anaconda3\envs\bert_aas e20200909 D:\programfiles\Anaconda3\envs\e20200909 ... tf D:\programfiles\Anaconda3\envs\tf 2. View all Jupyter Kernels. (base) C:\Users\aj>jupyter kernelspec list Available kernels: temp C:\Users\aj\AppData\Roaming\jupyter\kernels\temp tf C:\Users\aj\AppData\Roaming\jupyter\kernels\tf python3 D:\programfiles\Anaconda3\share\jupyter\kernels\python3 py38 C:\ProgramData\jupyter\kernels\py38 (base) C:\Users\aj> ========== 3. A note about updating a package in Conda (from debugging instructions). (base) C:\Users\aj>conda update ipykernel jupyter -c conda-forge Updating ipykernel is constricted by anaconda -> requires ipykernel==5.1.4=py37h39e3cac_0 If you are sure you want an update of your package either try `conda update --all` or install a specific version of the package you want using `conda install [pkg]=[version]` done ==> WARNING: A newer version of conda exists. current version: 4.8.4 latest version: 4.8.5 Please update conda by running $ conda update -n base -c defaults conda In this command, by '-n base' we mean 'base' is the name of the environment. By '-c defaults', we mean download 'conda' from the 'defaults' channel. Note: Following are three commonly used channels for downloading Python packages: 1. pkgs/main 2. defaults 3. conda-forge ========== 4. Installing a new Jupyter kernel. (e20200909) CMD>python -m ipykernel install --user --name e20200909 Installed kernelspec e20200909 in C:\Users\aj\AppData\Roaming\jupyter\kernels\e20200909 ========== 5. Checking installation Differentiating between 'pip' and 'conda' installation. (e20200909) D:\ws\jupyter>pip freeze | findstr /C:"jupyter" /C:"jupyterlab" jupyter-client @ file:///tmp/build/80754af9/jupyter_client_1594826976318/work jupyter-console @ file:///home/conda/feedstock_root/build_artifacts/jupyter_console_1598728807792/work jupyter-core==4.6.3 jupyterlab==2.2.8 jupyterlab-pygments @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_pygments_1601375948261/work jupyterlab-server @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_server_1593951277307/work (e20200909) C:\Users\aj>pip freeze | findstr /C:"transformers" /C:"tensorflow" /C:"torch" torch @ file:///C:/ci/pytorch_1596373105144/work transformers==3.0.1 Important Note: In the above two outputs, where we see a "@ file" based path in place of package version, that package has been installed via 'conda'. (e20200909) C:\Users\aj>python -c "import torch; print(torch.__version__);" 1.6.0 View only Conda installations (e20200909) CMD>pip freeze | findstr /C:"file" argon2-cffi @ file:///D:/bld/argon2-cffi_1596630042503/work attrs @ file:///home/conda/feedstock_root/build_artifacts/attrs_1599308529326/work bleach @ file:///home/conda/feedstock_root/build_artifacts/bleach_1600454382015/work cffi @ file:///C:/ci/cffi_1598352710791/work ... View only Pip installations (e20200909) CMD>pip freeze | findstr /v /C:"file" async-generator==1.10 backcall==0.2.0 bert-serving-client==1.10.0 bert-serving-server==1.10.0 certifi==2020.6.20 chardet==3.0.4 click==7.1.2 ... (e20200909) CMD>pip list Package Version ------------------- ------------------- argon2-cffi 20.1.0 async-generator 1.10 attrs 20.2.0 backcall 0.2.0 bert-serving-client 1.10.0 bert-serving-server 1.10.0 bleach 3.2.1 certifi 2020.6.20 cffi 1.14.2 chardet 3.0.4 click 7.1.2 ... ========== 6. Conda has more clarity about getting a good match between versions of already installed packages and the new packages that are to be installed: (e20200909) C:\Users\Ashish Jain>conda install tensorflow -c conda-forge Collecting package metadata (repodata.json): done Solving environment: failed with initial frozen solve. Retrying with flexible solve. Solving environment: - Found conflicts! Looking for incompatible packages. This can take several minutes. Press CTRL-C to abort. Examining python=3.8: 50%|███████████████ | 1/2 [00:03<00:03, 3.41s/it]-failed UnsatisfiableError: The following specifications were found to be incompatible with the existing python installation in your environment: Specifications: - tensorflow -> python[version='3.5.*|3.6.*|>=3.5,<3.6.0a0|>=3.6,<3.7.0a0|>=3.7,<3.8.0a0|3.7.*'] Your python: python=3.8 If python is on the left-most side of the chain, that's the version you've asked for. When python appears to the right, that indicates that the thing on the left is somehow not available for the python version you are constrained to. Note that conda will not change your python version to a different minor version unless you explicitly specify that. ========== 7. Getting all the available versions of a package in PyPI: (base) CMD>pip install tensorflow== ERROR: Could not find a version that satisfies the requirement tensorflow== (from versions: 1.13.0rc1, 1.13.0rc2, 1.13.1, 1.13.2, 1.14.0rc0, 1.14.0rc1, 1.14.0, 1.15.0rc0, 1.15.0rc1, 1.15.0rc2, 1.15.0rc3, 1.15.0, 1.15.2, 1.15.3, 1.15.4, 2.0.0a0, 2.0.0b0, 2.0.0b1, 2.0.0rc0, 2.0.0rc1, 2.0.0rc2, 2.0.0, 2.0.1, 2.0.2, 2.0.3, 2.1.0rc0, 2.1.0rc1, 2.1.0rc2, 2.1.0, 2.1.1, 2.1.2, 2.2.0rc0, 2.2.0rc1, 2.2.0rc2, 2.2.0rc3, 2.2.0rc4, 2.2.0, 2.2.1, 2.3.0rc0, 2.3.0rc1, 2.3.0rc2, 2.3.0, 2.3.1) ERROR: No matching distribution found for tensorflow== If Conda does not have a package in one of the mentioned channels such as 'conda-forge' or 'defaults', it raises the below exception: ResolvePackageNotFound: - tensorflow=1.15.4 ========== 8. Checking TensorFlow 1.X installation: (bert_env) CMD>conda list tensorflow # packages in environment at E:\programfiles\Anaconda3\envs\bert_env: # # Name Version Build Channel tensorflow 1.14.0 h1f41ff6_0 conda-forge tensorflow-base 1.14.0 py37hc8dfbb8_0 conda-forge tensorflow-estimator 1.14.0 py37h5ca1d4c_0 conda-forge (bert_env) CMD>python >>> import tensorflow as tf >>> print(tf.__version__) 2.3.0 >>> ~ ~ ~ ~ ~ (bert_env) CMD>pip freeze | find "tensorflow" tensorflow==2.3.0 tensorflow-estimator==2.3.0 (bert_env) CMD>pip freeze | findstr "tensorflow" tensorflow==2.3.0 tensorflow-estimator==2.3.0 (bert_env) CMD>python -c "import tensorflow as tf; print(tf.__version__)" 2.3.0 (bert_env) CMD>pip show tensorflow Name: tensorflow Version: 2.3.0 Summary: TensorFlow is an open source machine learning framework for everyone. Home-page: https://www.tensorflow.org/ Author: Google Inc. Author-email: packages@tensorflow.org License: Apache 2.0 Location: c:\users\aj\appdata\roaming\python\python37\site-packages Requires: wheel, astunparse, numpy, protobuf, wrapt, gast, six, tensorflow-estimator, scipy, grpcio, termcolor, tensorboard, opt-einsum, absl-py, keras-preprocessing, h5py, google-pasta Required-by: ==========
Tuesday, October 13, 2020
Flutter for Android Development (Notes, Oct 2020)
Follow these steps as part of setting up an old project on a new system. Such as in case of taking a project from Ubuntu machine to a Windows machine. 1.1 - Go to SDK Manager1.2 - Install the required Android SDK 2 - Build.grade changes - Removing unnecessary dependencies
2 - Build.grade changes - Removing unnecessary dependencies 3 - Changes in Gradle.properties to use AndroidX and Jetifier
3 - Changes in Gradle.properties to use AndroidX and Jetifier 4 - Flutter Commands To Begin With
4 - Flutter Commands To Begin With






Extracting Information From Search Engines
1. Google A Google Search URL looks like: https://www.google.com/search?q=nifty+50&start=0 In "nifty+50", "+" indicates [SPACE]. Pagination with 10 results per page, can be queried using 'start' parameter starting from 0. For first 10, start = 0 For second 10, start = 10 Notes: Google throws in a Captcha on sensing access through code or robots: Error: About this page Prove that you are not a robot by solving this Captcha... Our systems have detected unusual traffic from your computer network. This page checks to see if it's really you sending the requests, and not a robot. Why did this happen? IP address: 34.93.163.15 Time: 2020-10-09T09:23:07Z URL: https://www.google.com/search?q=VERB+RIK&start=0 Ref 1: Guide to the Google Search Parameters Ref 2: RapidAPI Google Search (Free usage allows 300 requests per month. '300 requests per month' means you better look for other free alternative.) 2. Bing A Bing Search URL looks like: https://www.bing.com/search?q=nifty+50&first=21 In "nifty+50", "+" indicates [SPACE]. Pagination with 10 results per page, can be queried using 'first' parameter starting from 1. For first 10, first = 1 For second 10, first = 11 Notes: 2.1. The search engine ranks home pages, not blogs. 2.2. Forums are often ranked low in the search results. 2.3. Sends back empty pages with no results on sensing access through code or robots. 2.4. RapidAPI offers an API for Bing Search but it has '1000 / month quota Hard Limit' on free usage and this means you better look for other free alternatives of RapidAPI. 3. Yahoo By Oct 2020, Yahoo has dropped to the third spot in terms of market share. Its web portal is still popular, and it is said to be the eleventh most visited site according to Alexa. Notes: 3.1. Unclear labeling of ads make it hard to distinguish between organic and non-organic results 3.2. Boasts other services such as Yahoo Finance, Yahoo mail, Yahoo answers, and several mobile apps. 3.3. Search URL for Yahoo can formed using its "p" argument as in this URL: https://in.search.yahoo.com/search?p=nifty50 3.4. RapidAPI is not available for Yahoo. 4. Contextual Web Search Contextual Web says on its Home-page: Search APIs & Custom Search: Easy to use search APIs. Search through billions of webpages with a simple API call and without breaking the bank. Get started in minutes. [ Ref: contextualweb.io ] 'Contextual Web Search' has URL: usearch The 'Contextual Web Search' are available via RapidAPI site. It is a paid service with a 'free and limited' version allowing '500 / day quota Hard Limit (After which usage will be restricted)'. Code for RapidAPI: import requests from time import time import datetime import os import json url = "https://contextualwebsearch-websearch-v1.p.rapidapi.com/api/Search/WebSearchAPI" querystring = { "pageNumber" : "1", "q" : "nifty50", "autoCorrect" : "false", "pageSize" : "100" } headers = { 'x-rapidapi-host': "contextualwebsearch-websearch-v1.p.rapidapi.com", 'x-rapidapi-key': "..." } response = requests.request("GET", url, headers=headers, params=querystring) with open(os.path.join("output", querystring['q'] + "_" + str(datetime.datetime.now()).replace(":", "_") + ".json"), mode = 'w', encoding = 'utf-8') as f: f.write(json.dumps(response.json(), indent=2, sort_keys=True)) The above code produces output in the form of a JSON file in a folder alongside this script named "output" (this should be created before running the script). References % RapidAPI's All API(s)

Friday, October 9, 2020
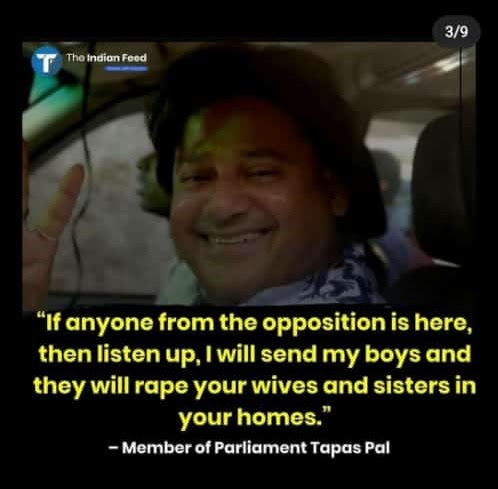
Indian Politicians Supporting Rapist Men
A collation of statements made by Indian politicians from time to time in support of rapists as Uttar Pradesh CM Yogi makes an anti-women comment following Hathras rape case in October, 2020.
















Wednesday, October 7, 2020
Word Embeddings using BERT and testing using Word Analogies, Nearest Words, 1D Spectrum
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.metrics.pairwise import cosine_similarity
from joblib import load, dump
import torch
import transformers as ppb
import warnings
warnings.filterwarnings('ignore')
ppb.__version__
'3.0.1'
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
The above code downloads three files when it runs for the first time:
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=433.0, style=ProgressStyle(description_…
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=231508.0, style=ProgressStyle(descripti…
HBox(children=(FloatProgress(value=0.0, description='Downloading', max=440473133.0, style=ProgressStyle(descri…
The third file is the model with size 440MB.
Our first step is to tokenize the sentences -- break them up into word and subwords in the format BERT is comfortable with.
sentences = ['First do it', 'then do it right', 'then do it better']
sentences_df = pd.DataFrame({"sentences": sentences})
tokenized = sentences_df['sentences'].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
Padding
After tokenization, `tokenized` is a list of sentences -- each sentences is represented as a list of tokens. We want BERT to process our examples all at once (as one batch). It's just faster that way. For that reason, we need to pad all lists to the same size, so we can represent the input as one 2-d array, rather than a list of lists (of different lengths).
max_len = 0
for i in tokenized.values:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0]*(max_len-len(i)) for i in tokenized.values])
Masking
If we directly send `padded` to BERT, that would slightly confuse it. We need to create another variable to tell it to ignore (mask) the padding we've added when it's processing its input. That's what attention_mask is:
attention_mask = np.where(padded != 0, 1, 0)
%%time
input_ids = torch.LongTensor(padded)
attention_mask = torch.tensor(attention_mask)
with torch.no_grad():
last_hidden_states = model(input_ids = input_ids, attention_mask = attention_mask)
features = last_hidden_states[0][:,0,:].numpy()
Let's slice only the part of the output that we need. That is the output corresponding the first token of each sentence. The way BERT does sentence classification, is that it adds a token called `[CLS]` (for classification) at the beginning of every sentence. Last token is representing [SEP]. The output corresponding to that token can be thought of as an embedding for the entire sentence.
 We'll save those in the `features` variable, as they'll serve as the features to our logitics regression model.
We'll save those in the `features` variable, as they'll serve as the features to our logitics regression model.
Testing
Word Analogies
def get_embedding(in_list):
tokenized = [tokenizer.encode(x, add_special_tokens=True) for x in in_list]
max_len = 0
for i in tokenized:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0]*(max_len-len(i)) for i in tokenized])
attention_mask = np.where(padded != 0, 1, 0)
input_ids = torch.LongTensor(padded)
attention_mask = torch.tensor(attention_mask)
with torch.no_grad():
last_hidden_states = model(input_ids = input_ids, attention_mask = attention_mask)
features = last_hidden_states[0][:,0,:].numpy()
return features
analogies = [['king', 'man', 'queen', 'woman'],
['king', 'prince', 'queen', 'princess'],
['miami', 'florida', 'dallas', 'texas'],
['einstein', 'scientist', 'picasso', 'painter'],
['japan', 'sushi', 'germany', 'bratwurst'],
['man', 'woman', 'he', 'she'],
['man', 'woman', 'uncle', 'aunt'],
['man', 'woman', 'brother', 'sister'],
['man', 'woman', 'husband', 'wife'],
['man', 'woman', 'actor', 'actress'],
['man', 'woman', 'father', 'mother'],
['heir', 'heiress', 'prince', 'princess'],
['nephew', 'niece', 'uncle', 'aunt'],
['france', 'paris', 'japan', 'tokyo'],
['france', 'paris', 'china', 'beijing'],
['february', 'january', 'december', 'november'],
['france', 'paris', 'germany', 'berlin'],
['week', 'day', 'year', 'month'],
['week', 'day', 'hour', 'minute'],
['france', 'paris', 'italy', 'rome'],
['paris', 'france', 'rome', 'italy'],
['france', 'french', 'england', 'english'],
['japan', 'japanese', 'china', 'chinese'],
['china', 'chinese', 'america', 'american'],
['japan', 'japanese', 'italy', 'italian'],
['japan', 'japanese', 'australia', 'australian'],
['walk', 'walking', 'swim', 'swimming']]
for i in analogies:
king = get_embedding([i[0]])
queen = get_embedding([i[2]])
man = get_embedding([i[1]])
woman = get_embedding([i[3]])
q = king - man + woman
print(i[0], '-', i[1], '+', i[3], 'and', i[2], cosine_similarity(queen, q))
king - man + woman and queen [[0.95728725]]
king - prince + princess and queen [[0.9805071]]
miami - florida + texas and dallas [[0.93608725]]
einstein - scientist + painter and picasso [[0.9021458]]
japan - sushi + bratwurst and germany [[0.8383053]]
man - woman + she and he [[0.97603536]]
man - woman + aunt and uncle [[0.9624729]]
man - woman + sister and brother [[0.970188]]
man - woman + wife and husband [[0.9585104]]
man - woman + actress and actor [[0.95233154]]
man - woman + mother and father [[0.9783108]]
heir - heiress + princess and prince [[0.9558885]]
nephew - niece + aunt and uncle [[0.9844531]]
france - paris + tokyo and japan [[0.95287836]]
france - paris + beijing and china [[0.94868445]]
february - january + november and december [[0.89765096]]
france - paris + berlin and germany [[0.9586985]]
week - day + month and year [[0.9131064]]
week - day + minute and hour [[0.9280644]]
france - paris + rome and italy [[0.92742187]]
paris - france + italy and rome [[0.9252609]]
france - french + english and england [[0.9143828]]
japan - japanese + chinese and china [[0.9681916]]
china - chinese + american and america [[0.9371264]]
japan - japanese + italian and italy [[0.97318065]]
japan - japanese + australian and australia [[0.96878356]]
walk - walking + swimming and swim [[0.90309924]]
Nearest Words
We have retrieved nouns from the 'BERT Base Uncased' vocabulary. There are 15269 nouns in this vocabulary.
You can download "vocab.txt" from here: GitHub
We have used to SpaCy to identify the nouns.
nouns = load('files_5_p3/list_of_nouns_from_bert_base_uncased_vocab.joblib')
%%time
noun_embeddings = [get_embedding([i]) for i in nouns]
dump(noun_embeddings, 'files_2_p2/list_of_noun_embeddings.joblib')
Wall time: 20min 8s
noun_embeddings = load('files_2_p2/list_of_noun_embeddings.joblib')
noun_embeddings = [n[0] for n in noun_embeddings]
from scipy.spatial import distance
def get_nn_of_words(in_list):
for k in in_list:
input_word = k
if k not in nouns:
continue
p = noun_embeddings[nouns.index(input_word)]
closest_embedding_indices = distance.cdist(np.array(p).reshape(1, -1),
np.array(noun_embeddings).reshape(len(noun_embeddings),-1))[0].argsort()[1:11]
closest_nouns = [nouns[i] for i in closest_embedding_indices]
print("For", k, closest_nouns)
get_nn_of_words(set(pd.core.common.flatten(analogies)))
For germany ['austria', 'bavaria', 'berlin', 'luxembourg', 'europe', 'japan', 'britain', 'wurttemberg', 'dresden', 'sweden']
For niece ['nephew', 'granddaughter', 'fiancee', 'daughter', 'grandparents', 'grandson', 'stepmother', 'aunt', 'cousins', 'wife']
For aunt ['grandmother', 'grandfather', 'uncle', 'cousin', 'sister', 'mother', 'miriam', 'vicki', 'uncles', 'cousins']
For february ['january', 'april', 'june', 'november', 'march', 'july', 'august', 'december', 'october', 'spring']
For england ['britain', 'wales', 'australia', 'ireland', 'barbados', 'stoke', 'brentford', 'lancashire', 'cuba', 'luxembourg']
For america ['planet', 'dakota', 'hawaii', 'britain', 'hemisphere', 'coral', 'virginia', 'nina', 'columbia', 'victoria']
For italian ['italy', 'russian', 'catalan', 'portuguese', 'french', 'azerbaijani', 'indonesian', 'austrian', 'japanese', 'irish']
For uncle ['aunt', 'cousin', 'grandfather', 'brother', 'grandmother', 'uncles', 'doc', 'bobby', 'mother', 'kid']
For miami ['tampa', 'seattle', 'vancouver', 'portland', 'arizona', 'vegas', 'sydney', 'florida', 'houston', 'orlando']
For italy ['austria', 'germany', 'luxembourg', 'europe', 'rico', 'japan', 'africa', 'indonesia', 'florence', 'tuscany']
For woman ['teenager', 'girl', 'spouse', 'brother', 'partner', 'daughter', 'mother', 'consort', 'wife', 'stallion']
For english ['afrikaans', 'hindi', 'latin', 'portuguese', 'sanskrit', 'french', 'italian', 'hebrew', 'azerbaijani', 'lithuanian']
For king ['duke', 'prince', 'queen', 'princess', 'throne', 'consort', 'deity', 'queens', 'abbot', 'lords']
For dallas ['jasmine', 'travis', 'savannah', 'eden', 'lucas', 'mia', 'lexi', 'jack', 'hunter', 'penny']
For mother ['grandmother', 'brother', 'mothers', 'parents', 'daughter', 'mom', 'father', 'grandfather', 'sister', 'mary']
For heiress ['landowner', 'heir', 'daughters', 'heirs', 'daughter', 'granddaughter', 'siblings', 'grandson', 'childless', 'clerk']
For japanese ['korean', 'japan', 'thai', 'russian', 'hawaiian', 'malaysian', 'indonesian', 'khmer', 'taiwanese', 'bengali']
For heir ['heirs', 'consort', 'spouse', 'prince', 'womb', 'attendants', 'fulfillment', 'duke', 'daughter', 'keeper']
For january ['november', 'april', 'august', 'february', 'december', 'summer', 'july', 'spring', 'october', 'june']
For brother ['sister', 'grandfather', 'cousin', 'grandmother', 'mother', 'daughter', 'partner', 'bowl', 'mentor', 'beau']
For wife ['husbands', 'daughter', 'spouse', 'husband', 'woman', 'girlfriend', 'household', 'supporter', 'boyfriend', 'granddaughter']
For minute ['moments', 'hour', 'dozen', 'mile', 'cycles', 'millennia', 'moment', 'sizes', 'clocks', 'twenties']
For picasso ['goldsmith', 'michelangelo', 'fresco', 'carousel', 'chopin', 'verdi', 'hercules', 'palette', 'canvas', 'britten']
For week ['month', 'series', 'replacement', 'primetime', 'position', 'highlight', 'zone', 'slot', 'office', 'showcase']
For japan ['america', 'ceylon', 'hawaii', 'malaysia', 'australia', 'taiwan', 'osaka', 'fukuoka', 'indonesia', 'korea']
For einstein ['aristotle', 'nobel', 'beckett', 'wiener', 'relativity', 'abel', 'strauss', 'skinner', 'clifford', 'bernstein']
For australian ['australia', 'canadian', 'canada', 'fremantle', 'oceania', 'america', 'brazil', 'nepal', 'jakarta', 'hawaii']
For painter ['musician', 'painting', 'paintings', 'designer', 'dancer', 'filmmaker', 'illustrator', 'teacher', 'soldier', 'boxer']
For man ['lump', 'woman', 'boss', 'bear', 'scratch', 'intruder', 'alpha', 'rat', 'touch', 'condo']
For florida ['maine', 'louisiana', 'arizona', 'virginia', 'charleston', 'indiana', 'tampa', 'colorado', 'alabama', 'connecticut']
For year ['season', 'month', 'eligibility', 'seasons', 'name', 'calendar', 'date', 'colour', 'highlight', 'divisional']
For tokyo ['osaka', 'kyoto', 'fukuoka', 'nagoya', 'seoul', 'kobe', 'moscow', 'honolulu', 'japan', 'nippon']
For november ['october', 'january', 'december', 'winter', 'spring', 'august', 'april', 'monday', 'halloween', 'wednesday']
For rome ['titan', 'vulcan', 'mesopotamia', 'damascus', 'alexandria', 'egypt', 'baghdad', 'orion', 'denver', 'nevada']
For china ['taiwan', 'fujian', 'indonesia', 'japan', 'asia', 'sichuan', 'malawi', 'lebanon', 'russia', 'zimbabwe']
For hour ['minute', 'hours', 'moments', 'dozen', 'weeks', 'inning', 'day', 'cycles', 'midnight', 'minutes']
For texas ['oregon', 'alabama', 'florida', 'colorado', 'ohio', 'indiana', 'georgia', 'houston', 'arkansas', 'arizona']
For sister ['brother', 'daughter', 'mother', 'grandmother', 'grandfather', 'cousin', 'aunt', 'padre', 'sisters', 'blossom']
For berlin ['vienna', 'stuttgart', 'hannover', 'hamburg', 'bonn', 'dresden', 'dusseldorf', 'gottingen', 'mannheim', 'rosenthal']
For actress ['actor', 'musician', 'singer', 'novelist', 'teacher', 'dancer', 'magician', 'poet', 'painter', 'actors']
For beijing ['tianjin', 'guangzhou', 'singapore', 'honolulu', 'taipei', 'ankara', 'osaka', 'manila', 'durban', 'jakarta']
For princess ['prince', 'madam', 'papa', 'kira', 'sweetie', 'witch', 'ruby', 'wedding', 'tasha', 'marta']
For nephew ['niece', 'grandson', 'granddaughter', 'daughter', 'fiancee', 'girlfriend', 'son', 'brother', 'sidekick', 'wife']
For month ['week', 'summers', 'evening', 'calendar', 'decade', 'semester', 'term', 'position', 'seasonal', 'occasion']
For swimming ['diving', 'weightlifting', 'judo', 'badminton', 'tennis', 'gymnastics', 'archery', 'swimmers', 'breaststroke', 'hockey']
For queen ['princess', 'queens', 'maid', 'king', 'prince', 'duke', 'consort', 'crown', 'stallion', 'madam']
For actor ['actress', 'actors', 'poet', 'television', 'singer', 'novelist', 'comedian', 'musician', 'screenwriter', 'painter']
For december ['november', 'january', 'october', 'april', 'march', 'june', 'july', 'september', 'august', 'autumn']
For american ['british', 'americans', 'america', 'britain', 'african', 'haitian', 'kenyan', 'bangladeshi', 'resident', 'canadian']
For french ['italian', 'portuguese', 'dutch', 'english', 'spanish', 'afrikaans', 'filipino', 'romanian', 'france', 'greek']
For prince ['princess', 'duke', 'consort', 'king', 'benedict', 'commander', 'papa', 'dean', 'throne', 'kevin']
For scientist ['physician', 'archaeologist', 'golfer', 'inventor', 'chef', 'consultant', 'investigator', 'teenager', 'astronaut', 'technician']
For paris ['bonn', 'laval', 'provence', 'dublin', 'geneva', 'eugene', 'michel', 'koln', 'benoit', 'ville']
For father ['mother', 'fathers', 'brother', 'daddy', 'uncles', 'son', 'sister', 'homeland', 'dad', 'protector']
For husband ['wife', 'spouse', 'lover', 'boyfriend', 'husbands', 'woman', 'daughter', 'son', 'fiance', 'mother']
For france ['martinique', 'luxembourg', 'marseille', 'geneva', 'bordeaux', 'lyon', 'paris', 'clermont', 'alsace', 'switzerland']
For australia ['australian', 'america', 'canada', 'tasmania', 'sydney', 'britain', 'japan', 'fremantle', 'malaysia', 'hawaii']
For day ['evening', 'nightfall', 'midnight', 'night', 'dawn', 'morning', 'moments', 'afternoon', 'epoch', 'sunrise']
1D Spectrum
for i in analogies:
king = get_embedding([i[0]])
queen = get_embedding([i[2]])
man = get_embedding([i[1]])
woman = get_embedding([i[3]])
q = king - man + woman
print(i[0], i[1], i[2], i[3], cosine_similarity(queen, q))
for j in i:
print(j, ":")
np.random.seed(1)
plt.rcParams["figure.figsize"] = 8, 2
x = np.linspace(0, 768, num=768)
y = get_embedding([j])
fig, (ax,ax2) = plt.subplots(nrows=2, sharex=True)
extent = [x[0]-(x[1]-x[0])/2., x[-1]+(x[1]-x[0])/2.,0,1]
ax.imshow(y, cmap="plasma", aspect="auto", extent=extent)
ax.set_yticks([])
ax.set_xlim(extent[0], extent[1])
ax2.plot(x, y.ravel())
plt.tight_layout()
plt.show()



Tuesday, October 6, 2020
Word embeddings using BERT (Demo of BERT-as-a-Service)
For installation we use a YAML file.
File: D:\f25\files_2\bert_aas.yaml
name: bert_aas
channels:
- conda-forge
- defaults
dependencies:
- termcolor
- numpy
- pyzmq
- tensorflow==1.14.0
- GPUtil
- sphinx-argparse
- pip:
- bert-serving-server
- bert-serving-client
==========
(base) CMD>conda env list
# conda environments:
#
base * D:\programfiles\Anaconda3
e20200909 D:\programfiles\Anaconda3\envs\e20200909
py38 D:\programfiles\Anaconda3\envs\py38
...
(base) CMD>jupyter kernelspec list
Available kernels:
tf C:\Users\aj\AppData\Roaming\jupyter\kernels\tf
python3 D:\programfiles\Anaconda3\share\jupyter\kernels\python3
py38 C:\ProgramData\jupyter\kernels\py38
==========
==> WARNING: A newer version of conda exists.
current version: 4.8.4
latest version: 4.8.5
Please update conda by running
$ conda update -n base -c defaults conda
==========
CMD> conda env create -f bert_aas_1.yaml
(base) CMD>conda activate bert_aas
==========
Checking TensorFlow installation
(bert_aas) CMD>pip freeze | find "tensorflow"
tensorflow @ file:///D:/bld/tensorflow_1594833538462/work/tensorflow-1.14.0-cp37-cp37m-win_amd64.whl
tensorflow-estimator==1.14.0
(bert_aas) CMD>python
Python 3.7.8 | packaged by conda-forge | (default, Jul 31 2020, 01:53:57) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
...
D:\programfiles\Anaconda3\envs\bert_aas\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
>>> tf.__version__
'1.14.0'
>>>
>>> hello = tf.constant('Hello, TensorFlow!')
>>> sess = tf.Session()
2020-10-05 14:47:48.399686: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
>>> print(sess.run(hello))
b'Hello, TensorFlow!'
>>>
==========
Setting up "model_dir"
This directory is passed as an input argument to "bert-serving-start" program from Command Prompt.
Model can be downloaded from here: storage.googleapis.com: BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
We also have these options for models (among others):
1. BERT-Large, Uncased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters
2. BERT-Large, Cased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parameters
3. BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters
4. BERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parameters
5. BERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parameters
6. BERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
Additional Note:
Fine-tuning with BERT
Important: All results on the paper were fine-tuned on a single Cloud TPU, which has 64GB of RAM. It is currently not possible to re-produce most of the BERT-Large results on the paper using a GPU with 12GB - 16GB of RAM, because the maximum batch size that can fit in memory is too small. We are working on adding code to this repository which allows for much larger effective batch size on the GPU. See the section on out-of-memory issues for more details.
This code was tested with TensorFlow 1.11.0. It was tested with Python2 and Python3 (but more thoroughly with Python2, since this is what's used internally in Google).
The fine-tuning examples which use BERT-Base should be able to run on a GPU that has at least 12GB of RAM using the hyperparameters given.
Ref: bert#pre-trained-models
==========
Issues with newer versions of TensorFlow and Bert-as-a-service
CMD> bert-serving-start -model_dir E:\e25/files_2/uncased_L-12_H-768_A-12 -num_worker=1
(bert_aas) E:\e25\files_2>bert-serving-start -model_dir E:\e25/files_2/uncased_L-12_H-768_A-12 -num_worker=1
2020-10-04 23:14:02.505211: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'cudart64_101.dll'; dlerror: cudart64_101.dll not found
2020-10-04 23:14:02.515231: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
e:\programfiles\anaconda3\envs\bert_aas\lib\site-packages\bert_serving\server\helper.py:176: UserWarning: Tensorflow 2.3.0 is not tested! It may or may not work. Feel free to submit an issue at https://github.com/hanxiao/bert-as-service/issues/
'Feel free to submit an issue at https://github.com/hanxiao/bert-as-service/issues/' % tf.__version__)
usage: E:\programfiles\Anaconda3\envs\bert_aas\Scripts\bert-serving-start -model_dir E:\e25/files_2/uncased_L-12_H-768_A-12 -num_worker=1
ARG VALUE
__________________________________________________
ckpt_name = bert_model.ckpt
config_name = bert_config.json
cors = *
cpu = False
device_map = []
do_lower_case = True
fixed_embed_length = False
fp16 = False
gpu_memory_fraction = 0.5
graph_tmp_dir = None
http_max_connect = 10
http_port = None
mask_cls_sep = False
max_batch_size = 256
max_seq_len = 25
model_dir = E:\e25/files_2/uncased_L-12_H-768_A-12
no_position_embeddings = False
no_special_token = False
num_worker = 1
pooling_layer = [-2]
pooling_strategy = REDUCE_MEAN
port = 5555
port_out = 5556
prefetch_size = 10
priority_batch_size = 16
show_tokens_to_client = False
tuned_model_dir = None
verbose = False
xla = False
I: [35mVENTILATOR [0m:freeze, optimize and export graph, could take a while...
e:\programfiles\anaconda3\envs\bert_aas\lib\site-packages\bert_serving\server\helper.py:176: UserWarning: Tensorflow 2.3.0 is not tested! It may or may not work. Feel free to submit an issue at https://github.com/hanxiao/bert-as-service/issues/
'Feel free to submit an issue at https://github.com/hanxiao/bert-as-service/issues/' % tf.__version__)
E: [36mGRAPHOPT [0m:fail to optimize the graph!
Traceback (most recent call last):
File "e:\programfiles\anaconda3\envs\bert_aas\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "e:\programfiles\anaconda3\envs\bert_aas\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "E:\programfiles\Anaconda3\envs\bert_aas\Scripts\bert-serving-start.exe\__main__.py", line 7, in
File "e:\programfiles\anaconda3\envs\bert_aas\lib\site-packages\bert_serving\server\cli\__init__.py", line 4, in main
with BertServer(get_run_args()) as server:
File "e:\programfiles\anaconda3\envs\bert_aas\lib\site-packages\bert_serving\server\__init__.py", line 71, in __init__
self.graph_path, self.bert_config = pool.apply(optimize_graph, (self.args,))
TypeError: cannot unpack non-iterable NoneType object
FROM HELPER.PY:
Path: e:\programfiles\anaconda3\envs\bert_aas\lib\site-packages\bert_serving\server\helper.py
import tensorflow as tf
tf_ver = tf.__version__.split('.')
if int(tf_ver[0]) <= 1 and int(tf_ver[1]) < 10:
raise ModuleNotFoundError('Tensorflow >=1.10 (one-point-ten) is required!')
elif int(tf_ver[0]) > 1:
warnings.warn('Tensorflow %s is not tested! It may or may not work. '
'Feel free to submit an issue at https://github.com/hanxiao/bert-as-service/issues/' % tf.__version__)
return tf_ver
~ ~ ~ ~ ~
Removing Conda Environment in Case of Failure
(bert_aas) CMD>conda deactivate
(base) CMD>conda env remove -n bert_aas
Remove all packages in environment E:\programfiles\Anaconda3\envs\bert_aas: y
Checking installation
(bert_aas) CMD>pip freeze | findstr "GPUtil"
GPUtil @ file:///home/conda/feedstock_root/build_artifacts/gputil_1590646865081/work
(bert_aas) CMD>pip freeze | findstr /C:"tensorflow" /C:"numpy" /C:"GPUtil"
GPUtil @ file:///home/conda/feedstock_root/build_artifacts/gputil_1590646865081/work
numpy==1.18.5
tensorflow==1.14.0
tensorflow-estimator==1.14.0
==========
Starting the server:
CMD> bert-serving-start -model_dir D:\ws\jupyter\f25_bert_for_sent_an\files_2\uncased_L-12_H-768_A-12 -num_worker=1
Logs:
ARG VALUE
__________________________________________________
ckpt_name = bert_model.ckpt
config_name = bert_config.json
model_dir = D:\ws\jupyter\f25_bert_for_sent_an\files_2\uncased_L-12_H-768_A-12
...
I: [36mGRAPHOPT [0m:model config: D:\ws\jupyter\f25_bert_for_sent_an\files_2\uncased_L-12_H-768_A-12\bert_config.json
I: [36mGRAPHOPT [0m:checkpoint: D:\ws\jupyter\f25_bert_for_sent_an\files_2\uncased_L-12_H-768_A-12\bert_model.ckpt
I: [36mGRAPHOPT [0m:build graph...
I: [36mGRAPHOPT [0m:load parameters from checkpoint...
I: [36mGRAPHOPT [0m:optimize...
I: [36mGRAPHOPT [0m:freeze...
I: [36mGRAPHOPT [0m:write graph to a tmp file: C:\Users\aj\AppData\Local\Temp\tmpxyxaq_b3
I: [35mVENTILATOR [0m:optimized graph is stored at: C:\Users\aj\AppData\Local\Temp\tmpxyxaq_b3
I: [35mVENTILATOR [0m:bind all sockets
I: [35mVENTILATOR [0m:open 8 ventilator-worker sockets
I: [35mVENTILATOR [0m:start the sink
...
I: [33mWORKER-0 [0m:ready and listening!
I: [35mVENTILATOR [0m:all set, ready to serve request!
==========
Running the client
(base) C:\Users\aj>conda activate bert_aas
(bert_aas) C:\Users\aj>python
>>> from bert_serving.client import BertClient
>>> bc = BertClient()
>>> enc_values = bc.encode(['First do it', 'then do it right', 'then do it better'])
>>> enc_values.shape
(3, 768)
>>> enc_values
array([[ 0.13186528, 0.3240411 , -0.82704353, ..., -0.37119573,
-0.39250126, -0.31721842],
[ 0.24873482, -0.12334437, -0.38933888, ..., -0.4475625 ,
-0.55913603, -0.11345193],
[ 0.2862734 , -0.18580128, -0.3090687 , ..., -0.29593647,
-0.39310572, 0.0764024 ]], dtype=float32)
>>>
Subscribe to:
Comments (Atom)