We are going to try out scikit-learn's MinMaxScaler for two features of a dataset.
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# Two lists with 20 values
train_df = pd.DataFrame({'A': list(range(1000, 3000, 100)), 'B': list(range(1000, 5000, 200))})
# Two lists with 42 values
test_df = pd.DataFrame({'A': list(range(-200, 4000, 100)), \
'B': sorted(list(range(1000, 4900, 100)) + [1050, 1150, 1250])})
scaler_a = MinMaxScaler(feature_range = (0, 10)) # feature_range: tuple (min, max), default=(0, 1)
scaler_b = MinMaxScaler(feature_range = (0, 10)) # feature_range: tuple (min, max), default=(0, 1)
train_df['a_skl'] = scaler_a.fit_transform(train_df[['A']])
train_df['b_skl'] = scaler_b.fit_transform(train_df[['B']])
print(train_df[0:1])
print(train_df[-1:])
Output:
A B a_skl b_skl
0 1000 1000 0.0 0.0
A B a_skl b_skl
19 2900 4800 10.0 10.0
test_df['a_skl'] = scaler_a.transform(test_df[['A']])
test_df['b_skl'] = scaler_b.transform(test_df[['B']])
print(test_df[0:1])
print(test_df[-1:])
Output:
A B a_skl b_skl
0 -200 1000 -6.315789 0.0
A B a_skl b_skl
41 3900 4800 15.263158 10.0
train_df_minmax_a = train_df['A'].agg([np.min, np.max])
train_df_minmax_b = train_df['B'].agg([np.min, np.max])
test_df_minmax_a = test_df['A'].agg([np.min, np.max])
test_df_minmax_b = test_df['B'].agg([np.min, np.max])
print(train_df_minmax_a)
print(train_df_minmax_b)
Output:
amin 1000
amax 2900
Name: A, dtype: int64
amin 1000
amax 4800
Name: B, dtype: int64
The problem
We have two features A and B. In training data, A has range: 1000 to 2900 and B has range: 1000 to 4800.
In test data, A has range: -200 to 3900, and B has range: 1000 to 4800.
On test data, B gets converted to values between 0 to 10 as specified in MinMaxScaler definition.
But A in test data gets converted to range: -6.3 to 15.26.
Result: A and B are still in different ranges on test data.
Fix
We should be able to anticipate the range we are going to observe in test data or in real time situation / production.
Next, we define a MinMaxScaler of our own.
For A, we set expected minimum to -500 and for B, we set expected minimum to 0. (Similarly for maximums.)
r_min = 0
r_max = 10
def getMinMax(cell, amin, amax):
a = cell - amin
x_std = a / (amax - amin)
x_scaled = x_std * (r_max - r_min) + r_min
return x_scaled
test_df['a_gmm'] = test_df['A'].apply(lambda x: getMinMax(x, -500, train_df_minmax_a.amax))
test_df['b_gmm'] = test_df['B'].apply(lambda x: getMinMax(x, 800, train_df_minmax_b.amax))
print(test_df)
Output:
A B a_skl b_skl a_gmm b_gmm
0 -200 1000 -6.31 0.00 0.88 0.50
1 -100 1050 -5.78 0.13 1.17 0.62
2 0 1100 -5.26 0.26 1.47 0.75
...
39 3700 4600 14.21 9.47 12.35 9.50
40 3800 4700 14.73 9.73 12.64 9.75
41 3900 4800 15.26 10.0 12.94 10.0
The way we have adjusted expected minimum value in test data, similarly we have to do for expected maximum to bring the scaled values in the same range.
Issue fixed.
References
% https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html
% https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.minmax_scale.html
% https://scikit-learn.org/stable/auto_examples/preprocessing/plot_all_scaling.html
% https://scikit-learn.org/stable/modules/preprocessing.html
% https://benalexkeen.com/feature-scaling-with-scikit-learn/
Sunday, June 21, 2020
Working with skLearn's MinMax scaler and defining our own
Saturday, June 20, 2020
An exercise in visualization (plotting line plot and multicolored histogram with -ve and +ve values)
This post is an exercise in visualization (plotting line plot and multicolored histogram with -ve and +ve values). We will be using Pandas and Matplotlib libraries.
We are going to do plotting for a week of Nifty50 data from Aug 2017.
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
%matplotlib inline
from dateutil import parser
df = pd.read_csv("files_1/201708.csv", encoding='utf8')
df['Change'] = 0
prev_close = 10114.65
def gen_change(row):
global prev_close
if row.Date == '01-Aug-2017':
rtn_val = 0
else:
rtn_val = round(((row.Close - prev_close) / prev_close) * 100, 2)
prev_close = row.Close
return rtn_val
df.Change = df.apply(gen_change, axis = 1)
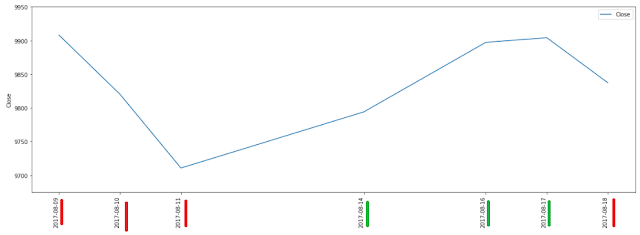
We will plot for only a few dates of Aug 2017:
Line plot:
subset_df = df[6:13]
plt.figure()
ax = subset_df[['Date', 'Close']].plot(figsize=(20,7))
ax.set_xticks(subset_df.index)
ax.set_ylim([9675, 9950])
ticklabels = plt.xticks(rotation=90)
plt.ylabel('Close')
plt.show()
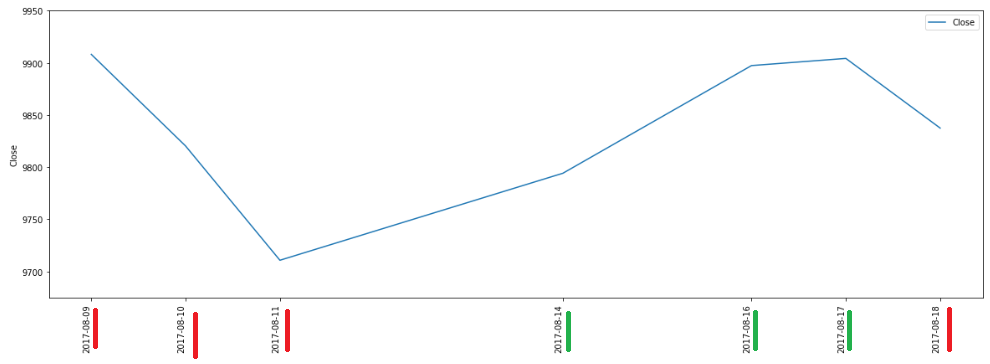
Multicolored Histogram for Negative and Positive values
negative_data = [x if x < 0 else 0 for x in list(subset_df.Change.values)]
positive_data = [x if x > 0 else 0 for x in list(subset_df.Change.values)]
fig = plt.figure()
ax = plt.subplot(111)
ax.bar(subset_df.Date.values, negative_data, width=1, color='r')
ax.bar(subset_df.Date.values, positive_data, width=1, color='g')
ticklabels = plt.xticks(rotation=90)
plt.xlabel('Date')
plt.ylabel('% Change')
plt.show()
 Link to data file: Google Drive
Link to data file: Google Drive

Thursday, June 18, 2020
Importance of posing right question for machine learning, data analysis and data preprocessing
We are going to demonstrate in this post the importance of posing the right question (presenting the ML use case, the ML problem correctly) and the importance of understanding data and presenting it to the ML model in the correct form.
The problem we are considering is of classification of data based on two columns, viz, alphabet and number.
+--------+------+------+
|alphabet|number|animal|
+--------+------+------+
| A| 1| Cat|
| A| 3| Cat|
| A| 5| Cat|
| A| 7| Cat|
| A| 9| Cat|
| A| 0| Dog|
| A| 2| Dog|
| A| 4| Dog|
| A| 6| Dog|
| A| 8| Dog|
| B| 1| Dog|
| B| 3| Dog|
| B| 5| Dog|
| B| 7| Dog|
| B| 9| Dog|
| B| 0| Cat|
| B| 2| Cat|
| B| 4| Cat|
| B| 6| Cat|
| B| 8| Cat|
+--------+------+------+
We have to tell if the "animal" is 'Cat' or 'Dog' based on 'alphabet' and 'number'.
Rules are as follows:
If alphabet is A and number is odd, animal is cat.
If alphabet is A and number is even, animal is dog.
If alphabet is B and number is odd, animal is dog.
If alphabet is B and number is even, animal is cat.
We have written following "DecisionTreeClassifier" code for this task and we are going to see how the data preprocessing aids for this problem.
from pyspark import SparkContext
from pyspark.sql import SQLContext # Main entry point for DataFrame and SQL functionality.
from pyspark.ml import Pipeline
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer, VectorIndexer, OneHotEncoder
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
sc = SparkContext.getOrCreate()
sqlCtx = SQLContext(sc)
a = list()
for i in range(0, 100000, 2):
a.append(('A', i+1, 'Cat'))
b = list()
for i in range(0, 100000, 2):
a.append(('A', i, 'Dog'))
c = list()
for i in range(0, 100000, 2):
c.append(('B', i+1, 'Dog'))
d = list()
for i in range(0, 100000, 2):
d.append(('B', i, 'Cat'))
l = a + b + c + d
df = sqlCtx.createDataFrame(l, ['alphabet', 'number', 'animal'])
alphabetIndexer = StringIndexer(inputCol="alphabet", outputCol="indexedAlphabet").fit(df)
df = alphabetIndexer.transform(df)
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=["indexedAlphabet", "number"], outputCol="features")
# VectorAssembler does not have a "fit" method.
# VectorAssembler would not work on "alphabet" column directly. Throws the error: "IllegalArgumentException: Data type string of column alphabet is not supported". It would work on "indexedAlphabet".
df = assembler.transform(df)
# Index labels, adding metadata to the label column.
# Fit on whole dataset to include all labels in index.
labelIndexer = StringIndexer(inputCol="animal", outputCol="label").fit(df)
df = labelIndexer.transform(df)
dt = DecisionTreeClassifier(labelCol="label", featuresCol="features")
# Chain indexers and tree in a Pipeline
# pipeline = Pipeline(stages=[labelIndexer, featureIndexer, dt])
pipeline = Pipeline(stages=[dt])
# Split the data into training and test sets (30% held out for testing)
(trainingData, testData) = df.randomSplit([0.95, 0.05])
# Train model. This also runs the indexers.
model = pipeline.fit(trainingData)
# Make predictions.
predictions = model.transform(testData)
# Select example rows to display.
# predictions.select("prediction", "label", "features").show()
# Select (prediction, true label) and compute test error
evaluator = MulticlassClassificationEvaluator(
labelCol="label", predictionCol="prediction") # 'precision' and 'recall' for 'metricName' arg are invalid.
accuracy = evaluator.evaluate(predictions)
#print("Test Error = %g" % (1.0 - accuracy))
print(df.count())
print("Accuracy = %g" % (accuracy))
treeModel = model.stages[0]
print(treeModel) # summary only
With this code, we observe the following results:
df.count(): 20000
Accuracy = 0.439774
df.count(): 200000
Accuracy = 0.471752
df.count(): 2000000
Accuracy = 0.490135
What went wrong?
We posed a simple classification problem to DecisionTreeClassifier, but we did not simplify the data to turn numbers into 'odd or even' indicator. This makes the learning so hard for model that with even 2 million data points, the classification accuracy stood at 49%.
~ ~ ~
Code changes to produce simplified data:
Change 1: replacing 'number' with 'odd or even' indicator.
Change 2: reducing number of data points.
a = list()
for i in range(0, 1000, 2):
a.append(('A', (i+1) % 2, 'Cat'))
b = list()
for i in range(0, 1000, 2):
a.append(('A', i%2, 'Dog'))
c = list()
for i in range(0, 1000, 2):
c.append(('B', (i+1) % 2, 'Dog'))
d = list()
for i in range(0, 1000, 2):
d.append(('B', i%2, 'Cat'))
Result:
df.count(): 200
Accuracy = 0.228571
df.count(): 2000
Accuracy = 1
Wednesday, June 17, 2020
Technology Listing related to Deep Learning (Jun 2020)
1. BIOS BIOS (pronounced: /ˈbaɪɒs/, BY-oss; an acronym for Basic Input/Output System and also known as the System BIOS, ROM BIOS or PC BIOS) is firmware used to perform hardware initialization during the booting process (power-on startup), and to provide runtime services for operating systems and programs. The BIOS firmware comes pre-installed on a personal computer's system board, and it is the first software to run when powered on. The name originates from the Basic Input/Output System used in the CP/M operating system in 1975. The BIOS originally proprietary to the IBM PC has been reverse engineered by companies looking to create compatible systems. The interface of that original system serves as a de facto standard. The BIOS in modern PCs initializes and tests the system hardware components, and loads a boot loader from a mass memory device which then initializes an operating system. In the era of DOS, the BIOS provided a hardware abstraction layer for the keyboard, display, and other input/output (I/O) devices that standardized an interface to application programs and the operating system. More recent operating systems do not use the BIOS after loading, instead accessing the hardware components directly. Most BIOS implementations are specifically designed to work with a particular computer or motherboard model, by interfacing with various devices that make up the complementary system chipset. Originally, BIOS firmware was stored in a ROM chip on the PC motherboard. In modern computer systems, the BIOS contents are stored on flash memory so it can be rewritten without removing the chip from the motherboard. This allows easy, end-user updates to the BIOS firmware so new features can be added or bugs can be fixed, but it also creates a possibility for the computer to become infected with BIOS rootkits. Furthermore, a BIOS upgrade that fails can brick the motherboard permanently, unless the system includes some form of backup for this case. Unified Extensible Firmware Interface (UEFI) is a successor to the legacy PC BIOS, aiming to address its technical shortcomings.Ref: BIOS 2. Unified Extensible Firmware Interface (UEFI) The Unified Extensible Firmware Interface (UEFI) is a specification that defines a software interface between an operating system and platform firmware. UEFI replaces the legacy Basic Input/Output System (BIOS) firmware interface originally present in all IBM PC-compatible personal computers, with most UEFI firmware implementations providing support for legacy BIOS services. UEFI can support remote diagnostics and repair of computers, even with no operating system installed. Intel developed the original Extensible Firmware Interface (EFI) specifications. Some of the EFI's practices and data formats mirror those of Microsoft Windows. In 2005, UEFI deprecated EFI 1.10 (the final release of EFI). The Unified EFI Forum is the industry body that manages the UEFI specifications throughout. EFI's position in the software stack:History The original motivation for EFI came during early development of the first Intel–HP Itanium systems in the mid-1990s. BIOS limitations (such as 16-bit processor mode, 1 MB addressable space and PC AT hardware) had become too restrictive for the larger server platforms Itanium was targeting. The effort to address these concerns began in 1998 and was initially called Intel Boot Initiative. It was later renamed to Extensible Firmware Interface (EFI). In July 2005, Intel ceased its development of the EFI specification at version 1.10, and contributed it to the Unified EFI Forum, which has developed the specification as the Unified Extensible Firmware Interface (UEFI). The original EFI specification remains owned by Intel, which exclusively provides licenses for EFI-based products, but the UEFI specification is owned by the UEFI Forum. Version 2.0 of the UEFI specification was released on 31 January 2006. It added cryptography and "secure boot". Version 2.1 of the UEFI specification was released on 7 January 2007. It added network authentication and the user interface architecture ('Human Interface Infrastructure' in UEFI). The latest UEFI specification, version 2.8, was approved in March 2019. Tiano was the first open source UEFI implementation and was released by Intel in 2004. Tiano has since then been superseded by EDK and EDK2 and is now maintained by the TianoCore community. In December 2018, Microsoft announced Project Mu, a fork of TianoCore EDK2 used in Microsoft Surface and Hyper-V products. The project promotes the idea of Firmware as a Service. Advantages The interface defined by the EFI specification includes data tables that contain platform information, and boot and runtime services that are available to the OS loader and OS. UEFI firmware provides several technical advantages over a traditional BIOS system: 1. Ability to use large disks partitions (over 2 TB) with a GUID Partition Table (GPT) 2. CPU-independent architecture 3. CPU-independent drivers 4. Flexible pre-OS environment, including network capability 5. Modular design 6. Backward and forward compatibility Ref: UEFI 3. Serial ATA Serial ATA (SATA, abbreviated from Serial AT Attachment) is a computer bus interface that connects host bus adapters to mass storage devices such as hard disk drives, optical drives, and solid-state drives. Serial ATA succeeded the earlier Parallel ATA (PATA) standard to become the predominant interface for storage devices. Serial ATA industry compatibility specifications originate from the Serial ATA International Organization (SATA-IO) which are then promulgated by the INCITS Technical Committee T13, AT Attachment (INCITS T13). History SATA was announced in 2000 in order to provide several advantages over the earlier PATA interface such as reduced cable size and cost (seven conductors instead of 40 or 80), native hot swapping, faster data transfer through higher signaling rates, and more efficient transfer through an (optional) I/O queuing protocol. Serial ATA industry compatibility specifications originate from the Serial ATA International Organization (SATA-IO). The SATA-IO group collaboratively creates, reviews, ratifies, and publishes the interoperability specifications, the test cases and plugfests. As with many other industry compatibility standards, the SATA content ownership is transferred to other industry bodies: primarily INCITS T13 and an INCITS T10 subcommittee (SCSI), a subgroup of T10 responsible for Serial Attached SCSI (SAS). The remainder of this article strives to use the SATA-IO terminology and specifications. Before SATA's introduction in 2000, PATA was simply known as ATA. The "AT Attachment" (ATA) name originated after the 1984 release of the IBM Personal Computer AT, more commonly known as the IBM AT. The IBM AT's controller interface became a de facto industry interface for the inclusion of hard disks. "AT" was IBM's abbreviation for "Advanced Technology"; thus, many companies and organizations indicate SATA is an abbreviation of "Serial Advanced Technology Attachment". However, the ATA specifications simply use the name "AT Attachment", to avoid possible trademark issues with IBM. SATA host adapters and devices communicate via a high-speed serial cable over two pairs of conductors. In contrast, parallel ATA (the redesignation for the legacy ATA specifications) uses a 16-bit wide data bus with many additional support and control signals, all operating at a much lower frequency. To ensure backward compatibility with legacy ATA software and applications, SATA uses the same basic ATA and ATAPI command sets as legacy ATA devices. SATA has replaced parallel ATA in consumer desktop and laptop computers; SATA's market share in the desktop PC market was 99% in 2008. PATA has mostly been replaced by SATA for any use; with PATA in declining use in industrial and embedded applications that use CompactFlash (CF) storage, which was designed around the legacy PATA standard. A 2008 standard, CFast to replace CompactFlash is based on SATA. Features 1. Hot plug 2. Advanced Host Controller Interface Ref: Serial ATA 4. Hard disk drive interface Hard disk drives are accessed over one of a number of bus types, including parallel ATA (PATA, also called IDE or EIDE; described before the introduction of SATA as ATA), Serial ATA (SATA), SCSI, Serial Attached SCSI (SAS), and Fibre Channel. Bridge circuitry is sometimes used to connect hard disk drives to buses with which they cannot communicate natively, such as IEEE 1394, USB, SCSI and Thunderbolt. Ref: HDD Interface 5. Solid-state drive A solid-state drive (SSD) is a solid-state storage device that uses integrated circuit assemblies to store data persistently, typically using flash memory, and functioning as secondary storage in the hierarchy of computer storage. It is also sometimes called a solid-state device or a solid-state disk, even though SSDs lack the physical spinning disks and movable read–write heads used in hard drives ("HDD") or floppy disks. % While the price of SSDs has continued to decline over time, SSDs are (as of 2020) still more expensive per unit of storage than HDDs and are expected to remain so into the next decade. % SSDs based on NAND Flash will slowly leak charge over time if left for long periods without power. This causes worn-out drives (that have exceeded their endurance rating) to start losing data typically after one year (if stored at 30 °C) to two years (at 25 °C) in storage; for new drives it takes longer. Therefore, SSDs are not suitable for archival storage. 3D XPoint is a possible exception to this rule, however it is a relatively new technology with unknown long-term data-retention characteristics. Improvement of SSD characteristics over time Parameter Started with (1991) Developed to (2018) Improvement Capacity 20 megabytes 100 terabytes (Nimbus Data DC100) 5-million-to-one Price US$50 per megabyte US$0.372 per gigabyte (Samsung PM1643) 134,408-to-one Ref: Solid-state drive 6. CUDA CUDA (Compute Unified Device Architecture) is a parallel computing platform and application programming interface (API) model created by Nvidia. It allows software developers and software engineers to use a CUDA-enabled graphics processing unit (GPU) for general purpose processing – an approach termed GPGPU (General-Purpose computing on Graphics Processing Units). The CUDA platform is a software layer that gives direct access to the GPU's virtual instruction set and parallel computational elements, for the execution of compute kernels. The CUDA platform is designed to work with programming languages such as C, C++, and Fortran. This accessibility makes it easier for specialists in parallel programming to use GPU resources, in contrast to prior APIs like Direct3D and OpenGL, which required advanced skills in graphics programming. CUDA-powered GPUs also support programming frameworks such as OpenACC and OpenCL; and HIP by compiling such code to CUDA. When CUDA was first introduced by Nvidia, the name was an acronym for Compute Unified Device Architecture, but Nvidia subsequently dropped the common use of the acronym. Ref: CUDA 7. Graphics Processing Unit A graphics processing unit (GPU) is a specialized electronic circuit designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display device. GPUs are used in embedded systems, mobile phones, personal computers, workstations, and game consoles. Modern GPUs are very efficient at manipulating computer graphics and image processing. Their highly parallel structure makes them more efficient than general-purpose central processing units (CPUs) for algorithms that process large blocks of data in parallel. In a personal computer, a GPU can be present on a video card or embedded on the motherboard. In certain CPUs, they are embedded on the CPU die. The term "GPU" was coined by Sony in reference to the PlayStation console's Toshiba-designed Sony GPU in 1994. The term was popularized by Nvidia in 1999, who marketed the GeForce 256 as "the world's first GPU". It was presented as a "single-chip processor with integrated transform, lighting, triangle setup/clipping, and rendering engines". Rival ATI Technologies coined the term "visual processing unit" or VPU with the release of the Radeon 9700 in 2002. GPU companies Many companies have produced GPUs under a number of brand names. In 2009, Intel, Nvidia and AMD/ATI were the market share leaders, with 49.4%, 27.8% and 20.6% market share respectively. However, those numbers include Intel's integrated graphics solutions as GPUs. Not counting those, Nvidia and AMD control nearly 100% of the market as of 2018. Their respective market shares are 66% and 33%. In addition, S3 Graphics and Matrox produce GPUs. Modern smartphones also use mostly Adreno GPUs from Qualcomm, PowerVR GPUs from Imagination Technologies and Mali GPUs from ARM. ~ ~ ~ % Modern GPUs use most of their transistors to do calculations related to 3D computer graphics. In addition to the 3D hardware, today's GPUs include basic 2D acceleration and framebuffer capabilities (usually with a VGA compatibility mode). Newer cards such as AMD/ATI HD5000-HD7000 even lack 2D acceleration; it has to be emulated by 3D hardware. GPUs were initially used to accelerate the memory-intensive work of texture mapping and rendering polygons, later adding units to accelerate geometric calculations such as the rotation and translation of vertices into different coordinate systems. Recent developments in GPUs include support for programmable shaders which can manipulate vertices and textures with many of the same operations supported by CPUs, oversampling and interpolation techniques to reduce aliasing, and very high-precision color spaces. Because most of these computations involve matrix and vector operations, engineers and scientists have increasingly studied the use of GPUs for non-graphical calculations; they are especially suited to other embarrassingly parallel problems. % With the emergence of deep learning, the importance of GPUs has increased. In research done by Indigo, it was found that while training deep learning neural networks, GPUs can be 250 times faster than CPUs. The explosive growth of Deep Learning in recent years has been attributed to the emergence of general purpose GPUs. There has been some level of competition in this area with ASICs, most prominently the Tensor Processing Unit (TPU) made by Google. However, ASICs require changes to existing code and GPUs are still very popular. Ref: GPU 8. Tensor processing unit A tensor processing unit (TPU) is an AI accelerator application-specific integrated circuit (ASIC) developed by Google specifically for neural network machine learning, particularly using Google's own TensorFlow software. Google began using TPUs internally in 2015, and in 2018 made them available for third party use, both as part of its cloud infrastructure and by offering a smaller version of the chip for sale. Edge TPU This article's use of external links may not follow Wikipedia's policies or guidelines. Please improve this article by removing excessive or inappropriate external links, and converting useful links where appropriate into footnote references. (March 2020) (Learn how and when to remove this template message) In July 2018, Google announced the Edge TPU. The Edge TPU is Google's purpose-built ASIC chip designed to run machine learning (ML) models for edge computing, meaning it is much smaller and consumes far less power compared to the TPUs hosted in Google datacenters (also known as Cloud TPUs). In January 2019, Google made the Edge TPU available to developers with a line of products under the Coral brand. The Edge TPU is capable of 4 trillion operations per second while using 2W. The product offerings include a single board computer (SBC), a system on module (SoM), a USB accessory, a mini PCI-e card, and an M.2 card. The SBC Coral Dev Board and Coral SoM both run Mendel Linux OS – a derivative of Debian. The USB, PCI-e, and M.2 products function as add-ons to existing computer systems, and support Debian-based Linux systems on x86-64 and ARM64 hosts (including Raspberry Pi). The machine learning runtime used to execute models on the Edge TPU is based on TensorFlow Lite. The Edge TPU is only capable of accelerating forward-pass operations, which means it's primarily useful for performing inferences (although it is possible to perform lightweight transfer learning on the Edge TPU). The Edge TPU also only supports 8-bit math, meaning that for a network to be compatible with the Edge TPU, it needs to be trained using TensorFlow quantization-aware training technique. On November 12, 2019, Asus announced a pair of single-board computer (SBCs) featuring the Edge TPU. The Asus Tinker Edge T and Tinker Edge R Board designed for IoT and edge AI. The SBCs support Android and Debian operating systems. ASUS has also demoed a mini PC called Asus PN60T featuring the Edge TPU. On January 2, 2020, Google announced the Coral Accelerator Module and Coral Dev Board Mini, to be demoed at CES 2020 later the same month. The Coral Accelerator Module is a multi-chip module featuring the Edge TPU, PCIe and USB interfaces for easier integration. The Coral Dev Board Mini is a smaller SBC featuring the Coral Accelerator Module and MediaTek 8167s SoC. Ref: TPU 9. PyTorch PyTorch is an open source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing, primarily developed by Facebook's AI Research lab (FAIR). It is free and open-source software released under the Modified BSD license. Although the Python interface is more polished and the primary focus of development, PyTorch also has a C++ interface. A number of pieces of Deep Learning software are built on top of PyTorch, including Tesla, Uber's Pyro, HuggingFace's Transformers, and Catalyst. PyTorch provides two high-level features: # Tensor computing (like NumPy) with strong acceleration via graphics processing units (GPU) # Deep neural networks built on a tape-based automatic differentiation system PyTorch tensors: PyTorch defines a class called Tensor (torch.Tensor) to store and operate on homogeneous multidimensional rectangular arrays of numbers. PyTorch Tensors are similar to NumPy Arrays, but can also be operated on a CUDA-capable Nvidia GPU. PyTorch supports various sub-types of Tensors. History: Facebook operates both PyTorch and Convolutional Architecture for Fast Feature Embedding (Caffe2), but models defined by the two frameworks were mutually incompatible. The Open Neural Network Exchange (ONNX) project was created by Facebook and Microsoft in September 2017 for converting models between frameworks. Caffe2 was merged into PyTorch at the end of March 2018. Ref: PyTorch 10. TensorFlow TensorFlow is a free and open-source software library for dataflow and differentiable programming across a range of tasks. It is a symbolic math library, and is also used for machine learning applications such as neural networks. It is used for both research and production at Google. TensorFlow was developed by the Google Brain team for internal Google use. It was released under the Apache License 2.0 on November 9, 2015. ~ ~ ~ TensorFlow is Google Brain's second-generation system. Version 1.0.0 was released on February 11, 2017. While the reference implementation runs on single devices, TensorFlow can run on multiple CPUs and GPUs (with optional CUDA and SYCL extensions for general-purpose computing on graphics processing units). TensorFlow is available on 64-bit Linux, macOS, Windows, and mobile computing platforms including Android and iOS. Its flexible architecture allows for the easy deployment of computation across a variety of platforms (CPUs, GPUs, TPUs), and from desktops to clusters of servers to mobile and edge devices. TensorFlow computations are expressed as stateful dataflow graphs. The name TensorFlow derives from the operations that such neural networks perform on multidimensional data arrays, which are referred to as tensors. During the Google I/O Conference in June 2016, Jeff Dean stated that 1,500 repositories on GitHub mentioned TensorFlow, of which only 5 were from Google. In December 2017, developers from Google, Cisco, RedHat, CoreOS, and CaiCloud introduced Kubeflow at a conference. Kubeflow allows operation and deployment of TensorFlow on Kubernetes. In March 2018, Google announced TensorFlow.js version 1.0 for machine learning in JavaScript. In Jan 2019, Google announced TensorFlow 2.0. It became officially available in Sep 2019. In May 2019, Google announced TensorFlow Graphics for deep learning in computer graphics. Ref: TensorFlow 11. Theano (software) Theano is a Python library and optimizing compiler for manipulating and evaluating mathematical expressions, especially matrix-valued ones. In Theano, computations are expressed using a NumPy-esque syntax and compiled to run efficiently on either CPU or GPU architectures. Theano is an open source project primarily developed by a Montreal Institute for Learning Algorithms (MILA) at the Université de Montréal. The name of the software references the ancient philosopher Theano, long associated with the development of the golden mean. On 28 September 2017, Pascal Lamblin posted a message from Yoshua Bengio, Head of MILA: major development would cease after the 1.0 release due to competing offerings by strong industrial players. Theano 1.0.0 was then released on 15 November 2017. On 17 May 2018, Chris Fonnesbeck wrote on behalf of the PyMC development team that the PyMC developers will officially assume control of Theano maintenance once they step down. Ref: Theano


Sunday, June 14, 2020
Creating an OLAP Star Schema using Materialized View (Oracle DB 10g)
Database used for this demo is: Oracle 10g Before we begin, we need to understand a few things: 1. Materialized View Log In an Oracle database, a materialized view log is a table associated with the master table of a materialized view. When master table data undergoes DML changes (such as INSERT, UPDATE, or DELETE), the Oracle database stores rows describing those changes in the materialized view log. A materialized view log is similar to an AUDIT table and is the mechanism used to capture changes made to its related master table. Rows are automatically added to the Materialized View Log table when the master table changes. The Oracle database uses the materialized view log to refresh materialized views based on the master table. This process is called fast refresh and improves performance in the source database. Ref: Materialized View Log (Oracle Docs) Table 1: "SS_TIME" CREATE TABLE "SS_TIME" ("ROW_IDENTIFIER" VARCHAR2(500), "TIME_LEVEL" VARCHAR2(500), "END_DATE" DATE, "TIME_SPAN_IN_DAYS" NUMBER); We are going to populate this table using a PL/SQL script. DECLARE start_year number; end_year number; no_of_days_in_year number; date_temp date; BEGIN start_year := 1996; end_year := 1997; no_of_days_in_year := 365; /* Inserting rows with level 'year' */ /* FOR i IN start_year .. end_year LOOP no_of_days_in_year := MOD(i, 4); IF no_of_days_in_year = 0 THEN no_of_days_in_year := 366; ELSE no_of_days_in_year := 365; END IF; insert into ss_time values(i, 'YEAR', add_months(to_date(start_year || '-JAN-01', 'YYYY-MON-DD'), 12) - 1, no_of_days_in_year); END LOOP; */ /* Inserting rows with level 'MONTH' */ FOR i IN start_year .. end_year LOOP FOR j in 0..11 LOOP date_temp := add_months(to_date(i || '-JAN-01', 'YYYY-MON-DD'), j) - 1; INSERT INTO ss_time VALUES(to_char(date_temp, 'MON') || i, 'MONTH', date_temp, extract(day from last_day(date_temp))); END LOOP; END LOOP; END; Once we run the above script, we get a data as shown below:Next, we have following tables: -- CustomerID CustomerName ContactName Address City PostalCode Country create table ss_customers (customerid number primary key, customername varchar2(1000), contactname varchar2(1000), address varchar2(1000), city varchar2(1000), postalcode varchar2(1000), country varchar2(1000)); -- OrderID CustomerID EmployeeID OrderDate ShipperID create table ss_orders (orderid number primary key, customerid number, employeeid number, orderdate date, shipperid number); -- ProductID ProductName SupplierID CategoryID Unit Price create table ss_products (productid number primary key, productname varchar2(1000), supplierid number, categoryid number, unit varchar2(1000), price number); -- CategoryID CategoryName Description create table ss_categories (categoryid number primary key, categoryname varchar2(1000), description varchar2(1000)); -- OrderDetailID OrderID ProductID Quantity create table ss_orderdetails (orderdetailid number, orderid number, productid number, quantity number); Next, we run insert statements for 'SS_CUSTOMERS' using an SQL file. The file is "Insert Statements for ss_customers.sql", and has contents: SET DEFINE OFF; insert into ss_customers values(1, 'Alfreds Futterkiste', 'Maria Anders', 'Obere Str. 57', 'Berlin', '12209', 'Germany'); insert into ss_customers values (2,'Ana Trujillo Emparedados y helados','Ana Trujillo','Avda. de la Constitucion 2222','Mexico D.F.','05021','Mexico'); insert into ss_customers values (3,'Antonio Moreno Taqueria','Antonio Moreno','Mataderos 2312','Mexico D.F.','05023','Mexico'); ... commmit; This file is ran from Command Prompt as shown below:You can view the contents of the table in 'SQL Developer' or 'Oracle 10g Apex Application':Similarly for "ss_orders":Similarly for 'ss_products':Similarly for "ss_categories":Similarly for "ss_orderdetails":Testing: select * from ss_orders; --GIVES THE NUMBER OF SALES select * from ss_customers; --GIVES THE COUNTRY WHERE SALES WERE MADE select * from ss_products; select * from ss_categories; select * from ss_time; select * from ss_orderdetails; select decode(sum(customerid),null,0,sum(customerid)) as cust_count from ss_customers where city='Delhi'; Our OLAP Star Schema will have: THREE DIMENSIONS: TIME, PRODUCT CATEGORIES (SINGLE VALUED DIMENSION), COUNTRY (SINGLE VALUED DIMENSION) AND ONE MEASURE: NUMBER OF ORDERS Query: select tim.row_identifier as time_interval, cust.country, cat.categoryname, count(ord.orderid) from ss_time tim, ss_customers cust, ss_categories cat, ss_orders ord, ss_orderdetails odd, ss_products prd where ord.customerid = cust.customerid and odd.productid = prd.productid and prd.categoryid = cat.categoryid and tim.end_date >= ord.orderdate and (tim.end_date - tim.time_span_in_days + 1) <= ord.orderdate group by tim.row_identifier, cust.country, cat.categoryname; OUTPUT:Another Test Query: select tim.row_identifier as time_interval, ord.orderid from ss_time tim, ss_orders ord where tim.end_date >= ord.orderdate and (tim.end_date - tim.time_span_in_days + 1) <= ord.orderdate; Next, we create "Materialized View Log(s)": CREATE MATERIALIZED VIEW LOG ON SS_PRODUCTS WITH PRIMARY KEY, ROWID (categoryid) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW LOG ON SS_ORDERDETAILS WITH ROWID (productid) INCLUDING NEW VALUES; /* The CREATE MATERIALIZED VIEW LOG command was issued with the WITH PRIMARY KEY option and the master table did not contain a primary key constraint or the constraint was disabled. Reissue the command using only the WITH ROWID option, create a primary key constraint on the master table, or enable an existing primary key constraint. */ CREATE MATERIALIZED VIEW LOG ON SS_ORDERS WITH PRIMARY KEY, ROWID (customerid, orderdate) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW LOG ON SS_CATEGORIES WITH PRIMARY KEY, ROWID (categoryname) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW LOG ON SS_CUSTOMERS WITH PRIMARY KEY, ROWID (country) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW LOG ON SS_TIME WITH ROWID (row_identifier, end_date, time_span_in_days) INCLUDING NEW VALUES; -- DROP MATERIALIZED VIEW LOG ON ss_time; Next, we create the 'Materialized View': CREATE MATERIALIZED VIEW ss_mv_total_sales_fact_table BUILD IMMEDIATE REFRESH FAST ON COMMIT ENABLE QUERY REWRITE AS SELECT tim.row_identifier AS time_interval, cust.country, cat.categoryname, count(ord.orderid) as count_orders FROM ss_time tim, ss_customers cust, ss_categories cat, ss_orders ord, ss_orderdetails odd, ss_products prd WHERE ord.customerid = cust.customerid AND odd.productid = prd.productid AND prd.categoryid = cat.categoryid AND tim.end_date >= ord.orderdate AND (tim.end_date - tim.time_span_in_days + 1) <= ord.orderdate GROUP BY tim.row_identifier, cust.country, cat.categoryname; Testing: SELECT * FROM ss_mv_total_sales_fact_table;SELECT * FROM ss_mv_total_sales_fact_table where country = 'Germany' order by categoryname;SELECT * FROM ss_mv_total_sales_fact_table where country = 'Germany' and time_interval = '1996'; -- No data found. SELECT * FROM ss_mv_total_sales_fact_table where country = 'Germany' and time_interval like '%1996%' order by categoryname;All code files are here: Google Drive










Taking table data from Excel to SQL based database
It is a common usecase when we have receive data in Excel sheet (a .XLS or .XLSX file) and we have to take it to an RDBMS such as Oracle Database or PostGRE SQL database. One way to do this transfer of data is: we first convert table data into SQL queries and then run those queries in the SQL interface of the database. This is what our Excel sheet looks like:In the cell [Row 2, Column 7], we insert the following function call to "CONCATENATE": =CONCATENATE("insert into employees values(",RC[-6],",'",RC[-5],"','",RC[-4],"',to_date('",RC[-3],"','MM/DD/YYYY'),'",RC[-2],"','",RC[-1],"');") This fills our cell [Row 2, Column 7] with an 'INSERT' SQL statement. insert into employees values(1 ,'Davolio ','Nancy ',to_date('12/8/1968 ','MM/DD/YYYY'),'EmpID1.pic ','Education includes a BA in psychology from Colorado State University. She also completed (The Art of the Cold Call). Nancy is a member of 'Toastmasters International'. '); Copying this in the entire 'column 7' produces the SQL statements we want. Before running the INSERT statements, we need to have the table "employees" in our database. The 'CREATE TABLE' statement for the "employees" table is: create table employees (EmployeeID number(5) primary key, LastName varchar2(80), FirstName varchar2(80), BirthDate date, Photo varchar2(80), Notes varchar2(4000)); Writing this 'CREATE TABLE' statement requires that we know the datatypes we want for our columns. Now we can populate our RDBMS database using the generated 'INSERT' statements. The Excel file used for this demo can be found here: Google Drive

Monday, June 1, 2020
India and China, destined for what? (Jun 2020)
There is a terminology called ‘Thucydides trap’ that is mentioned in the book called ‘Destined for War’, written by Graham Allison, which tracked the evolution of countries and presented how countries [may] find themselves eventually in the situation of war. The book is however oriented on the conditions of USA, however, we would like to have some liberties in the name of expression and free thinking. Last week we saw armies of two nations, most populous, oldest civilisations of the world, both nuclear powers, with two largest standing armies in the world, both aim to be the superpowers, and the soldiers were pelting stones at each other. Ironic. Question is, what is it that brings India and China at tussle with each other? Why this conflict at this time? What are several theories behind the tussle, reported in the array of media reports? And most importantly, where is this heading? Destiny has a very interesting way of presenting itself, depends if you believe on it. India and China are two of the oldest civilisations, with ancient cultural links. The sea voyages of Rajaraja Chola are well known in the India and ancient China relations. However, pinnacle of relations between both civilization was when Hiuen Tsang, who was a Chinese traveller visited India to research about Buddhism and exported Buddhism in China about 1400 years ago from today [2020]. Hiuen Tsang was born in Xiang, which is the birthplace of current Chinese President Xi Jinping. While Hiuen Tsang was travelling all of the India, the last place he visited in India was Vadnagar, which is birthplace of our current Prime Minister Narendra Modi. Narendra Modi also happens to be the first and only Chief Minister of any Indian state to have received State welcome from China, in 2013. If his visits to China, since he was Chief Minister of Gujarat is considered, then he is the only political leader in India to have visited China, ever. And yet, both of the leaders of two old civilisations, who also happen to be proud of their heritage, are in front of each other, in confrontation. This phenomenon is explained by the Thucydides Trap, which we will explain as soon as we cover very brief history of India and China. China, after a long and bloody civil war, emerged as a unified (depends how you look at Taiwan) country in 1948. It adopted the Communist regime, and cut away itself from all the cultural and religious heritage. But as it is said about China, ‘’China has habit of changing its ruler rather than being changed by it’’, the Chinese economy and its culture opened in 1978, when Deng Xiaoping called for liberalization and globalization in China. China divorced itself from so-called socialist policies, both economically and culturally, and became a capitalist economy (in practical sense). The growth of China happened so fast that, “we didn’t even get the time to be astonished”, as put forward by the President of Czech Republic. Now let’s look at India. India got independence in 1947, adopted socialist policies like China. Only difference is that China opened and globalized its economy in 1978, India did it in 1991, when India had got almost bankrupt. In these 14 years, China had surpassed India by 50 years, even with the smallest estimations. After 1991, however, India ran with rapid speed. Continuous FDI in India, rise of Indian IT sector, Nuclear test in 1999, rapid infrastructure development, continuously alleviating people from poverty. Suddenly India was seen as a rising power in Asia, which can counter Chinese rise, and that’s where Thucydides Trap comes into play. According to this theory, every powerful country ends up in a war with the country which is rising and seen as the replacement of the powerful country. Harvard University did a research on Thucydides trap, in which it was found that 12 times, in the history, countries end up fighting with each other over the question of who will be the power centre. And every time, neither the powerful country and rising country initiated the war, but it was initiated by someone else and both ended up in war. If we look at the similarities in the current leaders of China and India, there are too many similarities. Both enjoy unparalleled devotion in their respective parties, both are politically stable, both are ambitious, both are target oriented, both are clear about what they want, both seem to be interested in acquiring the central position in the international affairs. Even Xi Jinping had stated it that China will be No. 1 country in 2049, when they will complete 100th anniversary of Chinese revolution. You can not believe that something similar will not be there in Narendra Modi’s mind, Afterall he is brought up in an organization which has seen the dream of making India a “Vishwa guru”. A game of Chess The rise of both the countries can be traced on a game of chess. Chess game has three components – opening, middle game and endgame. Both countries have made their openings. Both have declared their intentions. Both have made progress in that direction as well. China has an advantage, as it made few moves earlier than India. However, the game has matured now. Now both countries are in the middle game. And like all the middle games of Chess, this game is too all about securing most suitable and strategic positions. In the middle game, every player wants to place his pieces on a place from where he can launch an attack most efficiently in the end game. China wanted to have an infrastructure at Doklam, which was quickly halted by the Indian interventions. India, after scrapping Article 370, incorporating whole Ladakh in Indian map, presenting forecasts of whole of the Ladakh, and then ramping up the infrastructure along LAC has conveyed clear messages, at least as far as the Chinese perception is concerned. Therefore, China at all cost wants to halt all those developments by India, which can secure strategic locations for India. Be it Ladakh or be it Kalapani issue raised by Nepal on the instigation of China. How the Endgame will turn out to be? This is something no one knows. At least not when world is facing, all of a sudden, unprecedented uncertainty. All we can wish that both countries end up with a draw in this match and co-exist together, like all great civilizations do. The rest will be shaped by the destiny. As I said it earlier in the article, destiny has a very strange way of presenting itself. Credits: Shubham Rajput
Sunday, May 24, 2020
Since the Hon’bles mentioned the merit (A look into the selection process of Indian judges, May 2020)
While we were cussing the lockdown, making speculation about the extent of the virus, and discussing the 20 lakh crore (INR) package, something remarkable happened in the country. The Supreme Court of India came out with its judgement on the petition submitted before the three-judge bench, regarding the NEET medical test and Minority status of the Educational Institutes.
The medical colleges came up with a petition that since they have got the minority educational institutes under Article 30 and Article 19 of the Constitution, they enjoy the right to administer their own colleges as per their convenience and do not need NEET. No doubt the petition was disposed of, but in between something interesting happened.
The Hon'ble Supreme Court came up with the notion of “merit”. And for a normal person who is not born in a family, which is surrounded by influential people, it is the idea of merit which secures opportunity for her. Also, it is the merit of the people governing such important positions, which let us believe in the working of the organization and earns the organization its credibility. Therefore, it is important that there should be a concept of merit in all those institutions which are of utmost importance, which includes the judiciary as well. Shouldn't the judiciary, too, be cautious about the procedure of merit?
Judiciary in today's democracy
Today, the functions of the judiciary are not limited merely to the pronouncements of the judgements but it has expanded to more fields of governance. The judiciary is not only defending the law but it is also making the law and also directing the authorities to implement the law. In simple political science language, democracy rests on the principle of the 'separation of power', where there is no institution that is all-powerful and has the authority of almost doing everything.
All democracies try to practice it. We have the ministers (the executive) who direct the authorities to implement decisions, we have legislature (parliament) to make laws and we have judiciary to see if the law is constitutional or not. But sometimes all three organs interfere in each other's business, and sometimes there are instances of excessive interference.
Remember the BCCI Case?
In the BCCI Case, the Supreme Court felt that the administration of the BCCI is not running as it should be. Then what did it do? It asked retired Chief Justice of India, Justice Lodha, to draft new rules as to how BCCI should be run. During this whole development of events, the Supreme Court made laws (which is generally done by the Parliament) and made appointments (which is done by the Government). The Supreme Court, in this case, assumed the all-powerful status and exercised all the powers which democracy offers by itself. And these decisions did not have any responsibility towards the people.
While making these decisions, not a single time it was considered that what if the decisions go wrong? Who will be responsible? Certainly, those who made these laws were and are not responsible to us. We hold the elected government responsible and also we can throw them out of power after five years if their decision stands uncorrected. What responsibility the Supreme Court and its Hon'ble Judges hold when they make a decision? Isn't it true that whatever decisions were made in the context of the BCCI case, all of them have backfired?
The logic which was used and still used in such instances is that it is the failure of the government that people come to us (the Supreme Court) to implement changes in the existing system. Fair enough. Point taken. But then comes an important aspect of the whole exercise - what is the merit of the people who are exercising this enormous amount of power through which they can make laws, have them implemented and also validate?
Why merit is questioned?
It is correct that the Supreme Court judges are far more knowledgeable and intellectually superior than a common man, but what is their status among their peers? Why this question is asked, because there is no clear mechanism as who will be appointed as the judge of the high court and what will be the requirements for that? Practising senior lawyers can be appointed as High Court judge if it is found that they are talented enough to hold the position of the judge. A sessions court judge too can be appointed as the supreme court judge, if she is considered to be meritorious enough.
But the question is, what stands for merit? What is the definition of merit? Under what circumstances one person is chosen and the other is not? There are no guidelines throughout the country. The decision is left into the hands of the judges themselves.
This situation must be considered attentively. A person who is going to exercise huge power is unknown to the common people of the country. His merits are unknown, why he was promoted on the first place is unknown, all the decisions he is going to make, do not come under any popular responsibility. So can we leave this important institution in a state where there is no transparency?
In 2019 we saw a case (the NJAC) in which the Supreme Court of India filed a petition in the Supreme Court. Yes, you read it correctly, the Supreme Court of India filed a petition in the Supreme Court of India against the Union Government. The petitioner was the Supreme Court, and the Supreme Court was going to pronounce judgement. Now consider if such a situation may arise again in future, will the decisions of Supreme Court shall be trusted if there will be no transparency in the judicial appointments? How do we know that the person sitting on the chair will be the best possible legal luminary of the country at that point of time? (Ref)
Therefore, when the Supreme Court is prescribing the conditions for merit in educational institutes, it is also necessary that the Supreme Court must come up with a mechanism that provides a transparent procedure for the appointment of judges in the judiciary, both in High Courts and in the Supreme Court. This will only strengthen the confidence of "We, the people of India".
Credits: Shubham Rajput
Friday, May 22, 2020
Most appropriate time for departure from the Gujaral’s doctrine (May 2020)
Inder Kumar Gujaral was a person who was woken up by his colleagues in the midnight, and was told, “get up, you have to sworn in as the Prime Minister of the country”. Such was the level of fortune associated with him. This happened in 1997-98, when Congress decided to remove H. D. Devegowda as the Prime Minister of the country, after his 9-month run. In those 9 months, one such event happened which changed the dynamics of the Indian diplomacy. That was the famous, “Gujral Doctrine”. Inder Kumar Gujaral was the Foreign Minister of India, in Devegowda’s cabinet, and being a Foreign Minister, he came up with an idea as how to deal with neighbours. These ideas came to be known as the ‘Gujaral Doctrine’. One of the many ideas in the doctrine was to extend unconditional support to the five neighbouring countries – Pakistan, Nepal, Bhutan, Afghanistan and Myanmar. No other nation than Nepal, made full use of the doctrine. Using the stance of the Indian Foreign Minister, Nepal was successful in asserting its claims on Kalapani District, which has currently resulted in the escalations of Indo-Nepal tensions. To understand is happening today, we need to understand what happened before. In 1824, a battle was fought between East India Company and Nepal, which came to be known as the Anglo-Nepal war. The war ended with the ‘’treaty of Sagauli’’. In the treaty, it was decided that the Kali river will be the boundary between the East India Company territories and Nepalese territories. The East India territories were inherited by the British Government, and from them, Indian government. Therefore, the Kali river became and remained the boundary between India and Nepal. The turn in the stance came only when I. K. Gujaral, in the capacity of the Foreign Minister of India went to Nepal and extended his doctrine. Which fool would ignore such offer? Therefore, Nepal grasped the opportunity from both hands. Nepal claimed that the Kalapani district belongs to Nepal and not to India, for which he stated some geographical misinterpretations. And surprisingly, the Foreign Minister, without any due consultations accepted the Nepalese claims. How the Gujaral Doctrine worked out since then? Simply put, pretty bad. India did not cease to follow the Gujaral doctrine, even after I. K. Gujaral cease to be the Foreign Minister and then the Prime Minister (both combined is equal to 1 and half years). Successive governments in the Centre continued to follow the doctrine, and this was not confined to only five countries but was extended to Maldives and few other countries. Due to this doctrine, Indian position was and is being taken for granted. What’s wrong with Nepal here? Currently, Nepal is going through lot of political instability. The incumbent Prime Minister K. P. Oli’s position is bit shaky. His inclination towards China, followed by smuggling of girls from Nepal to China, hacking activities by the Chinese hackers in the Nepalese database, mishandling of the Covid-19 outbreak has earned him fury of his people. Speculations are being made in favour of Pushpa Kamal Dahal, who is considered to be more leaned towards India than China. In the midst of all the tragedies taking place under Oli’s leadership, anti-India rhetoric, sponsored by China seems to be only way out. Not that Nepal enjoys such position through which it can change the status quo and can take control of what it claims its own. But all this gimmickry can do is to divert attention from the present crisis and turn it towards the so called ‘’arm twisting exercise of India’’. No one seems to be happier than China in this case, as this whole development lowers the credibility of India as a regional power centre. And this is the reason, why India should now throw the Gujaral doctrine into the garbage bin. As long as Indian position will be taken for granted, every country will continue to create such rhetoric which will lower down India’s credibility. India has the opportunity to show everyone of its neighbouring countries that goodwill is not a free food. If you wish to have it from India, you need to replicate it as well. As long as there is reciprocity in the relations, there is no need for diplomatic goodwill. Probably India can achieve it through trade and economy, the nerve centre of the diplomatic relations today. The tactics adopted in the Maldivian crisis, in which a President (anti India) is replaced by a President (anti-China and pro India) wont simply work here. Credits: Shubham Rajput
Thursday, May 21, 2020
Indian finance minister’s proposals for the defense sector show bright days ahead (May 2020)
If only, the finance minister’s economic stimulus package will be remembered in future, then it will be remembered for her defence sector reform announcements she made in the capacity of not the 'defense minister' but the 'finance minister'. In her announcements, she freed the Indian forces from the clutches of the Babus sitting in the air-conditioned room planning for the defence equipment purchases for those who will be fighting at the battlefront using the equipment. Agatha Christie had written in her book, ‘ABC Murders’: “What you do not see and what I do not see, stands a volume between that”. In the course of this long-form article, we are going to rewrite this quote and represent it in the context of today’s Indian Defence conditions. But first, let’s go through a few stories, the real ones. December 9th, 1971, three Indian ships, all of them were Interceptors were sent to intercept the advance of Pakistani Submarine Ghanghor. One such Indian ship was, INS Khukhri, commanded by Capt. Mahendra Nath Mulla. When INS Khukhri went into the Arabian Sea to find out the location of the Pakistani Submarine and to intercept it, the SONAR (the device which is responsible for finding the submarine) of the INS Khukhri was not working. The INS Khukhri was hit by the torpedo, fired by Ghanghor. Despite the ship being hit by the torpedo, Capt. Mahendra Nath Mulla decided not to leave the ship. Instead, he stayed in the ship to make sure that all his naval soldiers leave the ship safely. He took the ‘Jal Samadhi’, only to get immortal. May 26th, 1999. Flight Lieutenant Nachiketa was flying MIG-25 in Kargil region. The MIG-25, requires a high supply of oxygen from the surroundings to continue the fire rounds of bullets. In the Himalayas, this much amount of oxygen was not possible. As a result, engine crashed and he landed up in Rawalpindi, Pakistan. After diplomatic pressure, Flight Lieutenant Nachiketa was returned to India after 8 days. February 27th, 2019. Wing Commander Abhinandan was intercepting a 5th Generation fighter jet plane, F-16, with his 2nd generation MIG-21 Bison. What happened, we all know. Question is, what is the common denominator in all of the above-mentioned events? It was the obsolete quality of the Indian fighting equipment against far more superior equipment. These were only three such incidences. Otherwise, in almost all such interactions, it was the skills of Indian army men, which not only saved them but won India wars. But how long will we keep risking our men’s lives? Who is responsible for the risks they face today? The answer is - the procurement policy of the Indian Government. Now you might think that the quality standards of the Indian procurement of defence equipment are low, but it is just the opposite. In fact, the quality standards are that high that the Defence Minister, Manohar Parriker had once remarked that the Indian Defence procurement requirements are similar to Marvel Comics. If we rewrite the Agatha Christie’s quote in the context of the Defence Procurement Policy of the Government, then it can be written as: “what can be delivered and what you desire, a volume is missed in between”. The high-quality standards which are set by the Indian officers for the procurements of the defence equipment, are neither feasible to the Indian manufacturers of defence equipment (all of which are government-owned companies) nor they can be easily fulfilled by the foreign defence manufacturing companies. What is then done is, the Government of India, invites bids from the foreign manufacturers for the defence equipment needs of the Indian armed forces. The round of bureaucratic process continues to delay the delivery of the equipment. The most recent example is of Rafale fighter jets, whose procurement policy was kicked off in the year 2003, and not one of the fighter jet has landed in India yet. During this time, one of our very dear neighbours had developed almost 6 new squadrons of its air force, many of which were composed of only 5th generation fighter jets. If somebody asks the question that, ‘how many 5th generation jets do we have? not the squadron but the jets? The answer would have been zero, as of May 2020. Therefore, it was absolutely necessary to ease and relax the quality requirements for the defence procurements, to at least start the procurement. At the present juncture, it is sad to say, but is correct that our army is not well equipped to deal with strategic situations if ever the situation commanded to be so. How the policy announcements can bring a paradigm change in the defence procurement policy is the question. First of all, it should not be seen as a stand-alone policy decision. In the line of reforms, several policy decisions were announced in the last few years. One such was taken in December last year, when the Indian Air Force decided to dismantle one of its MIG squadrons, which will be replaced by a new squadron with newer fighter jets. One might be amazed that these jets were operational in India since 1970s. No other country in the world, yes, no other country in the world use this much old fighter jets for its army. And we, the country aims to be a superpower, are using these. Another important decision taken by the Government was the creation of the Department of Military Affairs, which was not headed by a Civil Servant, but by Chief of Defence Staff, who shall be responsible for the procurements related policies. This was a paradigm shift. The government shifted the decision-making calls from the civilian bureaucracy to the military personnel, who are much better equipped to make decisions on such issues. Not that the IAS Officers were incompetent, but they feared, and still fear 4Cs – Courts, CVC, CAG and CBI, while they are making any decision. Their policy decisions may be practical to the current requirements, but if those decisions are not in conformity with the pre-decided government protocols and procedures (which most of them are rudimentary and deserve to be placed in the dustbin) the officers are always subjected to the litigation process. The fear they share is genuine, therefore it was necessary that the Quality Requirements, which were set by the government, need to relaxed and should be readjusted keeping in mind current requirements and practical situations. A boy walking barefoot never has the luxury to choose what kind of shoe he wants to wear. Such is the situation of the Indian defence forces. We cannot afford to be choosy when we don't have anything to serve our present-day purposes. Otherwise, our defence manufacturing industries will continue to manufacture only that equipment which were approved by the Government in 1960s. It is important that we understand today that we don’t need to be the best to start, but to be the best, we need to start. The policy changes in the defence sector are encouraging signs, and only these changes can attract the much needed FDI in the defence sector, which we desire at the moment. Already, establishment of two Defence Corridors has been announced, one in Uttar Pradesh and another in Tamil Nadu, it will be worth to see how far can we march in this direction. Credits: Shubham Rajput
Subscribe to:
Comments (Atom)