Here we will use LSTM layers to develop time series forecasting model for the prediction of Nifty50 index's closing value.
Our environment:
(py383) ashish@ashish-VirtualBox:~/Desktop$ conda list keras
# packages in environment at /home/ashish/anaconda3/envs/py383:
#
# Name Version Build Channel
keras 2.4.3 pypi_0 pypi
keras-preprocessing 1.1.2 pypi_0 pypi
(py383) ashish@ashish-VirtualBox:~/Desktop$ conda list tensorflow
# packages in environment at /home/ashish/anaconda3/envs/py383:
#
# Name Version Build Channel
tensorflow 2.2.0 pypi_0 pypi
tensorflow-estimator 2.2.0 pypi_0 pypi
(py383) ashish@ashish-VirtualBox:~/Desktop$ conda list matplotlib
# packages in environment at /home/ashish/anaconda3/envs/py383:
#
# Name Version Build Channel
matplotlib 3.2.2 0
matplotlib-base 3.2.2 py38hef1b27d_0
(py383) ashish@ashish-VirtualBox:~/Desktop$ conda list scikit-learn
# packages in environment at /home/ashish/anaconda3/envs/py383:
#
# Name Version Build Channel
scikit-learn 0.23.1 py38h423224d_0
(py383) ashish@ashish-VirtualBox:~/Desktop$ conda list seaborn
# packages in environment at /home/ashish/anaconda3/envs/py383:
#
# Name Version Build Channel
seaborn 0.10.1 py_0
Python Code:
from __future__ import print_function
import os
import sys
import pandas as pd
import numpy as np
%matplotlib inline
from matplotlib import pyplot as plt
import seaborn as sns
import datetime
from dateutil.parser import parse
from sklearn.metrics import mean_absolute_error
# Read the dataset
l = []
for i in os.listdir('files_2'):
l.append(pd.read_csv(os.path.join('files_2', i)))
df = pd.concat(l, axis = 0)
We have data that looks like:
 def convert_str_to_date(in_date):
return parse(in_date)
df['Date'] = df['Date'].apply(convert_str_to_date)
df.sort_values(by = ['Date'], axis = 0, ascending = True, inplace = True, na_position = 'last')
df.reset_index(drop=True, inplace=True)
Gradient descent algorithms perform better (for example converge faster) if the variables are wihtin range [-1, 1]. Many sources relax the boundary to even [-3, 3]. The 'close' variable is mixmax scaled to bound the tranformed variable within [0,1].
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
df['scaled_close'] = scaler.fit_transform(np.array(df['Close']).reshape(-1, 1))
Before training the model, the dataset is split in two parts - train set and validation set. The neural network is trained on the train set. This means computation of the loss function, back propagation and weights updated by a gradient descent algorithm is done on the train set. The validation set is used to evaluate the model and to determine the number of epochs in model training. Increasing the number of epochs will further decrease the loss function on the train set but might not neccesarily have the same effect for the validation set due to overfitting on the train set. Hence, the number of epochs is controlled by keeping a tap on the loss function computed for the validation set. We use Keras with Tensorflow backend to define and train the model. All the steps involved in model training and validation is done by calling appropriate functions of the Keras API.
# Let's start by splitting the dataset into train and validation.
split_date = datetime.datetime(year=2020, month=8, day=1, hour=0)
df_train = df.loc[df['Date'] < split_date]
df_val = df.loc[df['Date'] >= split_date]
# Reset the indices of the validation set
df_val.reset_index(drop=True, inplace=True)
Now we need to generate regressors (X) and target variable (y) for train and validation. 2-D array of regressor and 1-D array of target is created from the original 1-D array of columm 'Close' in the DataFrames. For the time series forecasting model, Past seven days of observations are used to predict for the next day. This is equivalent to a AR(7) model. We define a function which takes the original time series and the number of timesteps in regressors as input to generate the arrays of X and y.
The makeXy function is used to generate arrays of regressors and targets-X_train, X_val, y_train and y_val. X_train, and X_val, as generated by the makeXy function, are 2D arrays of shape (number of samples, number of timesteps). However, the input to RNN layers must be of shape (number of samples, number of timesteps, number of features per timestep). In this case, we are dealing with only 'Close', hence number of features per timestep is one. Number of timesteps is seven and number of samples is the same as the number of samples in X_train and X_val, which are reshaped to 3D arrays:
def makeXy(ts, nb_timesteps):
"""
Input:
ts: original time series
nb_timesteps: number of time steps in the regressors
Output:
X: 2-D array of regressors
y: 1-D array of target
"""
X = []
y = []
for i in range(nb_timesteps, ts.shape[0]):
X.append(list(ts.loc[i-nb_timesteps:i-1]))
y.append(ts.loc[i])
X, y = np.array(X), np.array(y)
return X, y
X_train, y_train = makeXy(df_train['scaled_close'], 7)
X_val, y_val = makeXy(df_val['scaled_close'], 7)
#X_train and X_val are reshaped to 3D arrays
X_train, X_val = X_train.reshape((X_train.shape[0], X_train.shape[1], 1)), X_val.reshape((X_val.shape[0], X_val.shape[1], 1))
Now we define the MLP using the Keras Functional API. In this approach a layer can be declared as the input of the following layer at the time of defining the next layer.
from keras.layers import Dense, Input, Dropout
from keras.layers.recurrent import LSTM
from keras.optimizers import SGD
from keras.models import Model
from keras.models import load_model
from keras.callbacks import ModelCheckpoint
#Define input layer which has shape (None, 7) and of type float32. None indicates the number of instances
input_layer = Input(shape=(7,1), dtype='float32')
The LSTM layers are defined for seven timesteps. In this example, two LSTM layers are stacked. The first LSTM returns the output from each all seven timesteps. This output is a sequence and is fed to the second LSTM which returns output only from the last step. The first LSTM has sixty four hidden neurons in each timestep. Hence the sequence returned by the first LSTM has sixty four features.
lstm_layer1 = LSTM(64, input_shape=(7,1), return_sequences=True)(input_layer)
lstm_layer2 = LSTM(32, input_shape=(7,64), return_sequences=False)(lstm_layer1)
dropout_layer = Dropout(0.2)(lstm_layer2)
#Finally the output layer gives prediction.
output_layer = Dense(1, activation='linear')(dropout_layer)
The input, dense and output layers will now be packed inside a Model, which is wrapper class for training and making predictions. In case of presence of outliers, mean absolute error (MAE) is used as absolute deviations suffer less fluctuations compared to squared deviations.
The network's weights are optimized by the Adam algorithm. Adam stands for adaptive moment estimation and has been a popular choice for training deep neural networks. Unlike, stochastic gradient descent, adam uses different learning rates for each weight and separately updates the same as the training progresses. The learning rate of a weight is updated based on exponentially weighted moving averages of the weight's gradients and the squared gradients.
ts_model = Model(inputs=input_layer, outputs=output_layer)
ts_model.compile(loss='mean_absolute_error', optimizer='adam')#SGD(lr=0.001, decay=1e-5))
ts_model.summary()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 7, 1)] 0
_________________________________________________________________
lstm (LSTM) (None, 7, 64) 16896
_________________________________________________________________
lstm_1 (LSTM) (None, 32) 12416
_________________________________________________________________
dropout (Dropout) (None, 32) 0
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 29,345
Trainable params: 29,345
Non-trainable params: 0
_________________________________________________________________
The model is trained by calling the fit function on the model object and passing the X_train and y_train. The training is done for a predefined number of epochs. Additionally, batch_size defines the number of samples of train set to be used for a instance of back propagation.The validation dataset is also passed to evaluate the model after every epoch completes. A ModelCheckpoint object tracks the loss function on the validation set and saves the model for the epoch, at which the loss function has been minimum.
save_weights_at = os.path.join('files_1', 'models', 'p5', 'p5_nifty50_LSTM_weights.{epoch:02d}-{val_loss:.4f}.hdf5')
save_best = ModelCheckpoint(save_weights_at, monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=False, mode='min', period=1)
ts_model.fit(x=X_train, y=y_train, batch_size=16, epochs=30, verbose=1, callbacks=[save_best], validation_data=(X_val, y_val), shuffle=True)
WARNING:tensorflow:`period` argument is deprecated. Please use `save_freq` to specify the frequency in number of batches seen.
Epoch 1/30
381/381 [==============================] - 13s 33ms/step - loss: 0.0181 - val_loss: 0.0258
...
381/381 [==============================] - 10s 25ms/step - loss: 0.0175 - val_loss: 0.0384
[tensorflow.python.keras.callbacks.History at 0x7fed1c0a05b0]
Prediction are made from the best saved model. The model's predictions, which are on the standardized 'Rate', are inverse transformed to get predictions of original 'Rate'.
best_model = load_model(os.path.join('files_1', 'models', 'p5', 'p5_nifty50_LSTM_weights.12-0.0057.hdf5'))
preds = best_model.predict(X_val)
pred = scaler.inverse_transform(preds)
pred = np.squeeze(pred)
mae = mean_absolute_error(df_val['Close'].loc[7:], pred)
print('MAE for the validation set:', round(mae, 4))
MAE for the validation set: 65.7769
#Let's plot the actual and predicted values.
plt.figure(figsize=(5.5, 5.5))
plt.plot(range(len(df_val['Close'].loc[7:])), df_val['Close'].loc[7:], linestyle='-', marker='*', color='r')
plt.plot(range(len(df_val['Close'].loc[7:])), pred[:df_val.shape[0]], linestyle='-', marker='.', color='b')
plt.legend(['Actual','Predicted'], loc=2)
plt.title('Actual vs Predicted')
plt.ylabel('Close')
plt.xlabel('Index')
def convert_str_to_date(in_date):
return parse(in_date)
df['Date'] = df['Date'].apply(convert_str_to_date)
df.sort_values(by = ['Date'], axis = 0, ascending = True, inplace = True, na_position = 'last')
df.reset_index(drop=True, inplace=True)
Gradient descent algorithms perform better (for example converge faster) if the variables are wihtin range [-1, 1]. Many sources relax the boundary to even [-3, 3]. The 'close' variable is mixmax scaled to bound the tranformed variable within [0,1].
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
df['scaled_close'] = scaler.fit_transform(np.array(df['Close']).reshape(-1, 1))
Before training the model, the dataset is split in two parts - train set and validation set. The neural network is trained on the train set. This means computation of the loss function, back propagation and weights updated by a gradient descent algorithm is done on the train set. The validation set is used to evaluate the model and to determine the number of epochs in model training. Increasing the number of epochs will further decrease the loss function on the train set but might not neccesarily have the same effect for the validation set due to overfitting on the train set. Hence, the number of epochs is controlled by keeping a tap on the loss function computed for the validation set. We use Keras with Tensorflow backend to define and train the model. All the steps involved in model training and validation is done by calling appropriate functions of the Keras API.
# Let's start by splitting the dataset into train and validation.
split_date = datetime.datetime(year=2020, month=8, day=1, hour=0)
df_train = df.loc[df['Date'] < split_date]
df_val = df.loc[df['Date'] >= split_date]
# Reset the indices of the validation set
df_val.reset_index(drop=True, inplace=True)
Now we need to generate regressors (X) and target variable (y) for train and validation. 2-D array of regressor and 1-D array of target is created from the original 1-D array of columm 'Close' in the DataFrames. For the time series forecasting model, Past seven days of observations are used to predict for the next day. This is equivalent to a AR(7) model. We define a function which takes the original time series and the number of timesteps in regressors as input to generate the arrays of X and y.
The makeXy function is used to generate arrays of regressors and targets-X_train, X_val, y_train and y_val. X_train, and X_val, as generated by the makeXy function, are 2D arrays of shape (number of samples, number of timesteps). However, the input to RNN layers must be of shape (number of samples, number of timesteps, number of features per timestep). In this case, we are dealing with only 'Close', hence number of features per timestep is one. Number of timesteps is seven and number of samples is the same as the number of samples in X_train and X_val, which are reshaped to 3D arrays:
def makeXy(ts, nb_timesteps):
"""
Input:
ts: original time series
nb_timesteps: number of time steps in the regressors
Output:
X: 2-D array of regressors
y: 1-D array of target
"""
X = []
y = []
for i in range(nb_timesteps, ts.shape[0]):
X.append(list(ts.loc[i-nb_timesteps:i-1]))
y.append(ts.loc[i])
X, y = np.array(X), np.array(y)
return X, y
X_train, y_train = makeXy(df_train['scaled_close'], 7)
X_val, y_val = makeXy(df_val['scaled_close'], 7)
#X_train and X_val are reshaped to 3D arrays
X_train, X_val = X_train.reshape((X_train.shape[0], X_train.shape[1], 1)), X_val.reshape((X_val.shape[0], X_val.shape[1], 1))
Now we define the MLP using the Keras Functional API. In this approach a layer can be declared as the input of the following layer at the time of defining the next layer.
from keras.layers import Dense, Input, Dropout
from keras.layers.recurrent import LSTM
from keras.optimizers import SGD
from keras.models import Model
from keras.models import load_model
from keras.callbacks import ModelCheckpoint
#Define input layer which has shape (None, 7) and of type float32. None indicates the number of instances
input_layer = Input(shape=(7,1), dtype='float32')
The LSTM layers are defined for seven timesteps. In this example, two LSTM layers are stacked. The first LSTM returns the output from each all seven timesteps. This output is a sequence and is fed to the second LSTM which returns output only from the last step. The first LSTM has sixty four hidden neurons in each timestep. Hence the sequence returned by the first LSTM has sixty four features.
lstm_layer1 = LSTM(64, input_shape=(7,1), return_sequences=True)(input_layer)
lstm_layer2 = LSTM(32, input_shape=(7,64), return_sequences=False)(lstm_layer1)
dropout_layer = Dropout(0.2)(lstm_layer2)
#Finally the output layer gives prediction.
output_layer = Dense(1, activation='linear')(dropout_layer)
The input, dense and output layers will now be packed inside a Model, which is wrapper class for training and making predictions. In case of presence of outliers, mean absolute error (MAE) is used as absolute deviations suffer less fluctuations compared to squared deviations.
The network's weights are optimized by the Adam algorithm. Adam stands for adaptive moment estimation and has been a popular choice for training deep neural networks. Unlike, stochastic gradient descent, adam uses different learning rates for each weight and separately updates the same as the training progresses. The learning rate of a weight is updated based on exponentially weighted moving averages of the weight's gradients and the squared gradients.
ts_model = Model(inputs=input_layer, outputs=output_layer)
ts_model.compile(loss='mean_absolute_error', optimizer='adam')#SGD(lr=0.001, decay=1e-5))
ts_model.summary()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 7, 1)] 0
_________________________________________________________________
lstm (LSTM) (None, 7, 64) 16896
_________________________________________________________________
lstm_1 (LSTM) (None, 32) 12416
_________________________________________________________________
dropout (Dropout) (None, 32) 0
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 29,345
Trainable params: 29,345
Non-trainable params: 0
_________________________________________________________________
The model is trained by calling the fit function on the model object and passing the X_train and y_train. The training is done for a predefined number of epochs. Additionally, batch_size defines the number of samples of train set to be used for a instance of back propagation.The validation dataset is also passed to evaluate the model after every epoch completes. A ModelCheckpoint object tracks the loss function on the validation set and saves the model for the epoch, at which the loss function has been minimum.
save_weights_at = os.path.join('files_1', 'models', 'p5', 'p5_nifty50_LSTM_weights.{epoch:02d}-{val_loss:.4f}.hdf5')
save_best = ModelCheckpoint(save_weights_at, monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=False, mode='min', period=1)
ts_model.fit(x=X_train, y=y_train, batch_size=16, epochs=30, verbose=1, callbacks=[save_best], validation_data=(X_val, y_val), shuffle=True)
WARNING:tensorflow:`period` argument is deprecated. Please use `save_freq` to specify the frequency in number of batches seen.
Epoch 1/30
381/381 [==============================] - 13s 33ms/step - loss: 0.0181 - val_loss: 0.0258
...
381/381 [==============================] - 10s 25ms/step - loss: 0.0175 - val_loss: 0.0384
[tensorflow.python.keras.callbacks.History at 0x7fed1c0a05b0]
Prediction are made from the best saved model. The model's predictions, which are on the standardized 'Rate', are inverse transformed to get predictions of original 'Rate'.
best_model = load_model(os.path.join('files_1', 'models', 'p5', 'p5_nifty50_LSTM_weights.12-0.0057.hdf5'))
preds = best_model.predict(X_val)
pred = scaler.inverse_transform(preds)
pred = np.squeeze(pred)
mae = mean_absolute_error(df_val['Close'].loc[7:], pred)
print('MAE for the validation set:', round(mae, 4))
MAE for the validation set: 65.7769
#Let's plot the actual and predicted values.
plt.figure(figsize=(5.5, 5.5))
plt.plot(range(len(df_val['Close'].loc[7:])), df_val['Close'].loc[7:], linestyle='-', marker='*', color='r')
plt.plot(range(len(df_val['Close'].loc[7:])), pred[:df_val.shape[0]], linestyle='-', marker='.', color='b')
plt.legend(['Actual','Predicted'], loc=2)
plt.title('Actual vs Predicted')
plt.ylabel('Close')
plt.xlabel('Index')
 from sklearn.metrics import r2_score
r2 = r2_score(df_val['Close'].loc[7:], pred)
print('R-squared for the validation set:', round(r2,4))
R-squared for the validation set: 0.3702
from sklearn.metrics import r2_score
r2 = r2_score(df_val['Close'].loc[7:], pred)
print('R-squared for the validation set:', round(r2,4))
R-squared for the validation set: 0.3702
Saturday, September 5, 2020
Prediction of Nifty50 index using LSTM based model


Friday, September 4, 2020
Logging in Python
When to use logging Logging provides a set of convenience functions for simple logging usage. These are debug(), info(), warning(), error() and critical(). To determine when to use logging, see the table below, which states, for each of a set of common tasks, the best tool to use for it.The logging functions are named after the level or severity of the events they are used to track. The standard levels and their applicability are described below (in increasing order of severity):The default level is WARNING, which means that only events of this level and above will be tracked, unless the logging package is configured to do otherwise. Events that are tracked can be handled in different ways. The simplest way of handling tracked events is to print them to the console. Another common way is to write them to a disk file. Advanced Logging Tutorial The logging library takes a modular approach and offers several categories of components: loggers, handlers, filters, and formatters. % Loggers expose the interface that application code directly uses. % Handlers send the log records (created by loggers) to the appropriate destination. % Filters provide a finer grained facility for determining which log records to output. % Formatters specify the layout of log records in the final output. Log event information is passed between loggers, handlers, filters and formatters in a LogRecord instance. Logging is performed by calling methods on instances of the Logger class (hereafter called loggers). Each instance has a name, and they are conceptually arranged in a namespace hierarchy using dots (periods) as separators. For example, a logger named ‘scan’ is the parent of loggers ‘scan.text’, ‘scan.html’ and ‘scan.pdf’. Logger names can be anything you want, and indicate the area of an application in which a logged message originates. A good convention to use when naming loggers is to use a module-level logger, in each module which uses logging, named as follows: logger = logging.getLogger(__name__) This means that logger names track the package/module hierarchy, and it’s intuitively obvious where events are logged just from the logger name. The root of the hierarchy of loggers is called the root logger. That’s the logger used by the functions debug(), info(), warning(), error() and critical(), which just call the same-named method of the root logger. The functions and the methods have the same signatures. The root logger’s name is printed as ‘root’ in the logged output. It is, of course, possible to log messages to different destinations. Support is included in the package for writing log messages to files, HTTP GET/POST locations, email via SMTP, generic sockets, queues, or OS-specific logging mechanisms such as syslog or the Windows NT event log. Destinations are served by handler classes. You can create your own log destination class if you have special requirements not met by any of the built-in handler classes. By default, no destination is set for any logging messages. You can specify a destination (such as console or file) by using basicConfig() as in the tutorial examples. If you call the functions debug(), info(), warning(), error() and critical(), they will check to see if no destination is set; and if one is not set, they will set a destination of the console (sys.stderr) and a default format for the displayed message before delegating to the root logger to do the actual message output. The default format set by basicConfig() for messages is: severity:logger name:message You can change this by passing a format string to basicConfig() with the format keyword argument. For all options regarding how a format string is constructed, see Formatter Objects. Logging Flow The flow of log event information in loggers and handlers is illustrated in the following diagram.Loggers Logger objects have a threefold job. First, they expose several methods to application code so that applications can log messages at runtime. Second, logger objects determine which log messages to act upon based upon severity (the default filtering facility) or filter objects. Third, logger objects pass along relevant log messages to all interested log handlers. The most widely used methods on logger objects fall into two categories: configuration and message sending. These are the most common configuration methods: % Logger.setLevel() specifies the lowest-severity log message a logger will handle, where debug is the lowest built-in severity level and critical is the highest built-in severity. For example, if the severity level is INFO, the logger will handle only INFO, WARNING, ERROR, and CRITICAL messages and will ignore DEBUG messages. % Logger.addHandler() and Logger.removeHandler() add and remove handler objects from the logger object. Handlers are covered in more detail in Handlers. % Logger.addFilter() and Logger.removeFilter() add and remove filter objects from the logger object. Filters are covered in more detail in Filter Objects. You don’t need to always call these methods on every logger you create. See the last two paragraphs in this section. With the logger object configured, the following methods create log messages: % Logger.debug(), Logger.info(), Logger.warning(), Logger.error(), and Logger.critical() all create log records with a message and a level that corresponds to their respective method names. The message is actually a format string, which may contain the standard string substitution syntax of %s, %d, %f, and so on. The rest of their arguments is a list of objects that correspond with the substitution fields in the message. With regard to **kwargs, the logging methods care only about a keyword of exc_info and use it to determine whether to log exception information. % Logger.exception() creates a log message similar to Logger.error(). The difference is that Logger.exception() dumps a stack trace along with it. Call this method only from an exception handler. % Logger.log() takes a log level as an explicit argument. This is a little more verbose for logging messages than using the log level convenience methods listed above, but this is how to log at custom log levels. getLogger() returns a reference to a logger instance with the specified name if it is provided, or root if not. The names are period-separated hierarchical structures. Multiple calls to getLogger() with the same name will return a reference to the same logger object. Loggers that are further down in the hierarchical list are children of loggers higher up in the list. For example, given a logger with a name of foo, loggers with names of foo.bar, foo.bar.baz, and foo.bam are all descendants of foo. Loggers have a concept of effective level. If a level is not explicitly set on a logger, the level of its parent is used instead as its effective level. If the parent has no explicit level set, its parent is examined, and so on - all ancestors are searched until an explicitly set level is found. The root logger always has an explicit level set (WARNING by default). When deciding whether to process an event, the effective level of the logger is used to determine whether the event is passed to the logger’s handlers. Child loggers propagate messages up to the handlers associated with their ancestor loggers. Because of this, it is unnecessary to define and configure handlers for all the loggers an application uses. It is sufficient to configure handlers for a top-level logger and create child loggers as needed. (You can, however, turn off propagation by setting the propagate attribute of a logger to False.) Ref: docs.python.org/3/howto Logging Levels The numeric values of logging levels are given in the following table. These are primarily of interest if you want to define your own levels, and need them to have specific values relative to the predefined levels. If you define a level with the same numeric value, it overwrites the predefined value; the predefined name is lost.Ref 1: docs.python.org/3/library/logging Ref 2: docs.python.org/3/howto/logging Using logging in multiple modules Multiple calls to logging.getLogger('someLogger') return a reference to the same logger object. This is true not only within the same module, but also across modules as long as it is in the same Python interpreter process. It is true for references to the same object; additionally, application code can define and configure a parent logger in one module and create (but not configure) a child logger in a separate module, and all logger calls to the child will pass up to the parent. Here is a main module: import logging import auxiliary_module # create logger with 'spam_application' logger = logging.getLogger('spam_application') logger.setLevel(logging.DEBUG) # create file handler which logs even debug messages fh = logging.FileHandler('spam.log') fh.setLevel(logging.DEBUG) # create console handler with a higher log level ch = logging.StreamHandler() ch.setLevel(logging.ERROR) # create formatter and add it to the handlers formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') fh.setFormatter(formatter) ch.setFormatter(formatter) # add the handlers to the logger logger.addHandler(fh) logger.addHandler(ch) logger.info('creating an instance of auxiliary_module.Auxiliary') a = auxiliary_module.Auxiliary() logger.info('created an instance of auxiliary_module.Auxiliary') logger.info('calling auxiliary_module.Auxiliary.do_something') a.do_something() logger.info('finished auxiliary_module.Auxiliary.do_something') logger.info('calling auxiliary_module.some_function()') auxiliary_module.some_function() logger.info('done with auxiliary_module.some_function()') Here is the auxiliary module: import logging # create logger module_logger = logging.getLogger('spam_application.auxiliary') class Auxiliary: def __init__(self): self.logger = logging.getLogger('spam_application.auxiliary.Auxiliary') self.logger.info('creating an instance of Auxiliary') def do_something(self): self.logger.info('doing something') a = 1 + 1 self.logger.info('done doing something') def some_function(): module_logger.info('received a call to "some_function"') The output looks like this: 2005-03-23 23:47:11,663 - spam_application - INFO - creating an instance of auxiliary_module.Auxiliary 2005-03-23 23:47:11,665 - spam_application.auxiliary.Auxiliary - INFO - creating an instance of Auxiliary 2005-03-23 23:47:11,665 - spam_application - INFO - created an instance of auxiliary_module.Auxiliary 2005-03-23 23:47:11,668 - spam_application - INFO - calling auxiliary_module.Auxiliary.do_something 2005-03-23 23:47:11,668 - spam_application.auxiliary.Auxiliary - INFO - doing something 2005-03-23 23:47:11,669 - spam_application.auxiliary.Auxiliary - INFO - done doing something 2005-03-23 23:47:11,670 - spam_application - INFO - finished auxiliary_module.Auxiliary.do_something 2005-03-23 23:47:11,671 - spam_application - INFO - calling auxiliary_module.some_function() 2005-03-23 23:47:11,672 - spam_application.auxiliary - INFO - received a call to 'some_function' 2005-03-23 23:47:11,673 - spam_application - INFO - done with auxiliary_module.some_function() When we ran it: PS C:\Users\Ashish Jain> cd .\OneDrive\Desktop\code\ PS C:\Users\Ashish Jain\OneDrive\Desktop\code> ls Directory: C:\Users\Ashish Jain\OneDrive\Desktop\code Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 9/4/2020 11:30 PM 1126 app.py -a---- 9/4/2020 11:32 PM 518 auxiliary_module.py PS C:\Users\Ashish Jain\OneDrive\Desktop\code> python app.py PS C:\Users\Ashish Jain\OneDrive\Desktop\code> PS C:\Users\Ashish Jain\OneDrive\Desktop\code> ls Directory: C:\Users\Ashish Jain\OneDrive\Desktop\code Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 9/4/2020 11:36 PM __pycache__ -a---- 9/4/2020 11:30 PM 1126 app.py -a---- 9/4/2020 11:32 PM 518 auxiliary_module.py -a---- 9/4/2020 11:36 PM 988 spam.log Contents of spam.log: 2020-09-04 23:36:37,281 - spam_application - INFO - creating an instance of auxiliary_module.Auxiliary 2020-09-04 23:36:37,281 - spam_application.auxiliary.Auxiliary - INFO - creating an instance of Auxiliary 2020-09-04 23:36:37,281 - spam_application - INFO - created an instance of auxiliary_module.Auxiliary 2020-09-04 23:36:37,281 - spam_application - INFO - calling auxiliary_module.Auxiliary.do_something 2020-09-04 23:36:37,281 - spam_application.auxiliary.Auxiliary - INFO - doing something 2020-09-04 23:36:37,281 - spam_application.auxiliary.Auxiliary - INFO - done doing something 2020-09-04 23:36:37,281 - spam_application - INFO - finished auxiliary_module.Auxiliary.do_something 2020-09-04 23:36:37,281 - spam_application - INFO - calling auxiliary_module.some_function() 2020-09-04 23:36:37,281 - spam_application.auxiliary - INFO - received a call to "some_function" 2020-09-04 23:36:37,281 - spam_application - INFO - done with auxiliary_module.some_function() Ref for above example: howto/logging-cookbook A second example: PS C:\Users\Ashish Jain> cd .\OneDrive\Desktop\code2\ PS C:\Users\Ashish Jain\OneDrive\Desktop\code2> ls Directory: C:\Users\Ashish Jain\OneDrive\Desktop\code2 Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 9/4/2020 11:49 PM 1072 app.py -a---- 9/4/2020 11:49 PM 325 submodule.py File "app.py": # app.py (runs when application starts) import logging import logging.config # This is required. Otherwise, you get error: AttributeError: module 'logging' has no attribute 'config' import os.path import submodule as sm def main(): logging_config = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': '%(asctime)s [%(levelname)s] %(name)s: %(message)s' }, }, 'handlers': { 'default_handler': { 'class': 'logging.FileHandler', 'level': 'DEBUG', 'formatter': 'standard', #'filename': os.path.join('logs', 'application.log'), 'filename': 'application.log', 'encoding': 'utf8' }, }, 'loggers': { '': { 'handlers': ['default_handler'], 'level': 'DEBUG', 'propagate': False } } } logging.config.dictConfig(logging_config) logger = logging.getLogger(__name__) logger.info("Application started.") sm.do_something() if __name__ == '__main__': main() File "submodule.py" has code: import logging # define top level module logger logger = logging.getLogger(__name__) def do_something(): logger.info('Something happended.') try: logger.info("In 'try'.") except Exception as e: logger.exception(e) logger.exception('Something broke.') Run... PS C:\Users\Ashish Jain\OneDrive\Desktop\code2> python .\app.py PS C:\Users\Ashish Jain\OneDrive\Desktop\code2> ls Directory: C:\Users\Ashish Jain\OneDrive\Desktop\code2 Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 9/4/2020 11:50 PM __pycache__ -a---- 9/4/2020 11:52 PM 1259 app.py -a---- 9/4/2020 11:52 PM 180 application.log -a---- 9/4/2020 11:49 PM 325 submodule.py PS C:\Users\Ashish Jain\OneDrive\Desktop\code2> Logs in file "application.log": 2020-09-04 23:52:00,208 [INFO] __main__: Application started. 2020-09-04 23:52:00,208 [INFO] submodule: Something happended. 2020-09-04 23:52:00,208 [INFO] submodule: In 'try'. Ref for second example: stackoverflow References % realpython.com/python-logging % Python/2 Logging % Toptal - Python Logging % docs.python-guide.org/writing/logging % machinelearningplus % zetcode % tutorialspoint




Requests.get method, cleaning html and writing output to text file
Setup (base) C:\Users\Ashish Jain>conda env list # conda environments: # base * E:\programfiles\Anaconda3 env_py_36 E:\programfiles\Anaconda3\envs\env_py_36 temp E:\programfiles\Anaconda3\envs\temp tf E:\programfiles\Anaconda3\envs\tf (base) C:\Users\Ashish Jain>conda create -n temp202009 python=3.8 Collecting package metadata (repodata.json): done Solving environment: done ## Package Plan ## environment location: E:\programfiles\Anaconda3\envs\temp202009 added / updated specs: - python=3.8 The following packages will be downloaded: package | build ---------------------------|----------------- ca-certificates-2020.7.22 | 0 164 KB python-3.8.5 | h5fd99cc_1 18.7 MB sqlite-3.33.0 | h2a8f88b_0 1.3 MB wheel-0.35.1 | py_0 36 KB ------------------------------------------------------------ Total: 20.2 MB The following NEW packages will be INSTALLED: ca-certificates pkgs/main/win-64::ca-certificates-2020.7.22-0 certifi pkgs/main/win-64::certifi-2020.6.20-py38_0 openssl pkgs/main/win-64::openssl-1.1.1g-he774522_1 pip pkgs/main/win-64::pip-20.2.2-py38_0 python pkgs/main/win-64::python-3.8.5-h5fd99cc_1 setuptools pkgs/main/win-64::setuptools-49.6.0-py38_0 sqlite pkgs/main/win-64::sqlite-3.33.0-h2a8f88b_0 vc pkgs/main/win-64::vc-14.1-h0510ff6_4 vs2015_runtime pkgs/main/win-64::vs2015_runtime-14.16.27012-hf0eaf9b_3 wheel pkgs/main/noarch::wheel-0.35.1-py_0 wincertstore pkgs/main/win-64::wincertstore-0.2-py38_0 zlib pkgs/main/win-64::zlib-1.2.11-h62dcd97_4 Proceed ([y]/n)? y Downloading and Extracting Packages wheel-0.35.1 | 36 KB | ##################################### | 100% sqlite-3.33.0 | 1.3 MB | ##################################### | 100% ca-certificates-2020 | 164 KB | ##################################### | 100% python-3.8.5 | 18.7 MB | ##################################### | 100% Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use # # $ conda activate temp202009 # # To deactivate an active environment, use # # $ conda deactivate (base) C:\Users\Ashish Jain>conda activate temp202009 (temp202009) C:\Users\Ashish Jain>pip install ipykernel jupyter jupyterlab Collecting ipykernel Collecting jupyter Collecting jupyterlab ... Building wheels for collected packages: pandocfilters, pyrsistent Building wheel for pandocfilters (setup.py) ... done Created wheel for pandocfilters: filename=pandocfilters-1.4.2-py3-none-any.whl size=7861 sha256=eaf50b551ad8291621c8a87234dca80f07b0e9b1603ec8ad7179740f988b4dec Stored in directory: c:\users\ashish jain\appdata\local\pip\cache\wheels\f6\08\65\e4636b703d0e870cd62692dafd6b47db27287fe80cea433722 Building wheel for pyrsistent (setup.py) ... done Created wheel for pyrsistent: filename=pyrsistent-0.16.0-cp38-cp38-win_amd64.whl size=71143 sha256=1f0233569beedcff74c358bd0666684c2a0f2d74b56fbdea893711c2f1a761f8 Stored in directory: c:\users\ashish jain\appdata\local\pip\cache\wheels\17\be\0f\727fb20889ada6aaaaba861f5f0eb21663533915429ad43f28 Successfully built pandocfilters pyrsistent Installing collected packages: tornado, ipython-genutils, traitlets, pyzmq, six, python-dateutil, pywin32, jupyter-core, jupyter-client, colorama, parso, jedi, pygments, backcall, wcwidth, prompt-toolkit, decorator, pickleshare, ipython, ipykernel, jupyter-console, qtpy, qtconsole, MarkupSafe, jinja2, attrs, pyrsistent, jsonschema, nbformat, mistune, pyparsing, packaging, webencodings, bleach, pandocfilters, entrypoints, testpath, defusedxml, nbconvert, pywinpty, terminado, prometheus-client, Send2Trash, pycparser, cffi, argon2-cffi, notebook, widgetsnbextension, ipywidgets, jupyter, json5, urllib3, chardet, idna, requests, jupyterlab-server, jupyterlab Successfully installed MarkupSafe-1.1.1 Send2Trash-1.5.0 argon2-cffi-20.1.0 attrs-20.1.0 backcall-0.2.0 bleach-3.1.5 cffi-1.14.2 chardet-3.0.4 colorama-0.4.3 decorator-4.4.2 defusedxml-0.6.0 entrypoints-0.3 idna-2.10 ipykernel-5.3.4 ipython-7.18.1 ipython-genutils-0.2.0 ipywidgets-7.5.1 jedi-0.17.2 jinja2-2.11.2 json5-0.9.5 jsonschema-3.2.0 jupyter-1.0.0 jupyter-client-6.1.7 jupyter-console-6.2.0 jupyter-core-4.6.3 jupyterlab-2.2.6 jupyterlab-server-1.2.0 mistune-0.8.4 nbconvert-5.6.1 nbformat-5.0.7 notebook-6.1.3 packaging-20.4 pandocfilters-1.4.2 parso-0.7.1 pickleshare-0.7.5 prometheus-client-0.8.0 prompt-toolkit-3.0.7 pycparser-2.20 pygments-2.6.1 pyparsing-2.4.7 pyrsistent-0.16.0 python-dateutil-2.8.1 pywin32-228 pywinpty-0.5.7 pyzmq-19.0.2 qtconsole-4.7.7 qtpy-1.9.0 requests-2.24.0 six-1.15.0 terminado-0.8.3 testpath-0.4.4 tornado-6.0.4 traitlets-5.0.3 urllib3-1.25.10 wcwidth-0.2.5 webencodings-0.5.1 widgetsnbextension-3.5.1 (temp202009) C:\Users\Ashish Jain>python -m ipykernel install --user --name temp202009 Installed kernelspec temp202009 in C:\Users\Ashish Jain\AppData\Roaming\jupyter\kernels\temp202009 === === === === ERROR: ImportError: DLL load failed while importing win32api: The specified module could not be found. (temp202009) E:\>conda install pywin32 === === === === (temp202009) E:\>pip install htmllaundry (temp202009) E:\>pip install html-sanitizer Collecting html-sanitizer Collecting beautifulsoup4 Collecting soupsieve>1.2 Downloading soupsieve-2.0.1-py3-none-any.whl (32 kB) Installing collected packages: soupsieve, beautifulsoup4, html-sanitizer Successfully installed beautifulsoup4-4.9.1 html-sanitizer-1.9.1 soupsieve-2.0.1 Issues faced with pulling an article using "newsapi" and "newspaper" packages. #1 Exception occurred for: [newspaper.article.Article object at 0x00000248F12896D8] and 2020-08-08T16:55:21Z Article `download()` failed with 503 Server Error: Service Unavailable for url: https://www.marketwatch.com/story/profit-up-87-at-buffetts-berkshire-but-coronavirus-slows-businesses-2020-08-08 on URL https://www.marketwatch.com/story/profit-up-87-at-buffetts-berkshire-but-coronavirus-slows-businesses-2020-08-08 #2 Exception occurred for: [newspaper.article.Article object at 0x00000248F1297B70] and 2020-08-11T22:59:42Z Article `download()` failed with 403 Client Error: Forbidden for url: https://seekingalpha.com/article/4367745-greatest-disconnect-stocks-and-economy-continues on URL https://seekingalpha.com/article/4367745-greatest-disconnect-stocks-and-economy-continues #3 Exception occurred for: [newspaper.article.Article object at 0x00000248F12AC550] and 2020-08-11T16:17:55Z Article `download()` failed with HTTPSConnectionPool(host='www.freerepublic.com', port=443): Max retries exceeded with url: /focus/f-news/3873373/posts (Caused by SSLError(SSLError("bad handshake: Error([('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')])"))) on URL https://www.freerepublic.com/focus/f-news/3873373/posts Trying a fix using Python shell (base) C:\Users\Ashish Jain>python Python 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)] :: Anaconda, Inc. on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import requests >>> requests.get('https://seekingalpha.com/article/4367745-greatest-disconnect-stocks-and-economy-continues') [Response [200]] >>> requests.get('https://seekingalpha.com/article/4367745-greatest-disconnect-stocks-and-economy-continues').text '<!DOCTYPE html><html itemscope="" itemtype="https://schema.org/WebPage" lang="en">... >>> with open('html.txt', 'w') as f: ... f.write(requests.get('https://seekingalpha.com/article/4367745-greatest-disconnect-stocks-and-economy-continues').text) ... Traceback (most recent call last): File "[stdin]", line 2, in [module] File "E:\programfiles\Anaconda3\lib\encodings\cp1252.py", line 19, in encode return codecs.charmap_encode(input,self.errors,encoding_table)[0] UnicodeEncodeError: 'charmap' codec can't encode character '\ufeff' in position 13665: character maps to [undefined] >>> with open('html.txt', 'w', encoding="utf-8") as f: ... f.write(requests.get('https://seekingalpha.com/article/4367745-greatest-disconnect-stocks-and-economy-continues').text) ... 636685 Now we have the HTML. Next we clean it to remove HTML tags. Using htmllaundry from htmllaundry import sanitize !pip show htmllaundry Name: htmllaundry Version: 2.2 Summary: Simple HTML cleanup utilities Home-page: UNKNOWN Author: Wichert Akkerman Author-email: wichert@wiggy.net License: BSD Location: e:\programfiles\anaconda3\envs\temp202009\lib\site-packages Requires: lxml, six Required-by: sanitize(r.text) '<p>\n\n\n \n \n Access to this page has been denied.\n \n \n \n\n\n\n \n \n To continue, please prove you are not a robot\n \n \n \n \n \n \n </p><p>\n To ensure this doesn’t happen in the future, please enable Javascript and cookies in your browser.<br/>\n Is this happening to you frequently? Please <a href="https://seekingalpha.userecho.com?source=captcha" rel="nofollow">report it on our feedback forum</a>.\n </p>\n <p>\n If you have an ad-blocker enabled you may be blocked from proceeding. Please disable your ad-blocker and refresh.\n </p>\n <p>Reference ID: </p>\n \n \n \n\n\n\n\n\n\n\n' from htmllaundry import strip_markup cleantext = strip_markup(sanitize(r.text)).strip() cleantext = re.sub(r"(\n)+", " ", cleantext) cleantext = re.sub(r"\s+", " ", cleantext) print(cleantext) 'Access to this page has been denied. To continue, please prove you are not a robot To ensure this doesn’t happen in the future, please enable Javascript and cookies in your browser. Is this happening to you frequently? Please report it on our feedback forum. If you have an ad-blocker enabled you may be blocked from proceeding. Please disable your ad-blocker and refresh. Reference ID:' Using html_sanitizer from html_sanitizer import Sanitizer !pip show html_sanitizer Name: html-sanitizer Version: 1.9.1 Summary: HTML sanitizer Home-page: https://github.com/matthiask/html-sanitizer/ Author: Matthias Kestenholz Author-email: mk@feinheit.ch License: BSD License Location: e:\programfiles\anaconda3\envs\temp202009\lib\site-packages Requires: beautifulsoup4, lxml Required-by: sanitizer = Sanitizer() cleantext = sanitizer.sanitize(r.text).strip() cleantext = re.sub(r"(\n)+", " ", cleantext) cleantext = re.sub(r"\s+", " ", cleantext) print(cleantext) 'Access to this page has been denied. <h1>To continue, please prove you are not a robot</h1> <p> To ensure this doesn’t happen in the future, please enable Javascript and cookies in your browser.<br> Is this happening to you frequently? Please <a href="https://seekingalpha.userecho.com?source=captcha">report it on our feedback forum</a>. </p> <p> If you have an ad-blocker enabled you may be blocked from proceeding. Please disable your ad-blocker and refresh. </p> <p>Reference ID: </p>' Using beautifulsoup4 import re from bs4 import BeautifulSoup cleantext = BeautifulSoup(r.text, "lxml").text cleantext = re.sub(r"(\n)+", " ", cleantext) cleantext = re.sub(r"\s+", " ", cleantext) cleantext.strip() 'Access to this page has been denied. To continue, please prove you are not a robot To ensure this doesn’t happen in the future, please enable Javascript and cookies in your browser. Is this happening to you frequently? Please report it on our feedback forum. If you have an ad-blocker enabled you may be blocked from proceeding. Please disable your ad-blocker and refresh. Reference ID:'

Thursday, September 3, 2020
Working with base 64 encoding using Windows CMD
We have a zip file "input1.zip" that we will turn into "output1.txt" using base-64 encoding: C:\Users\Ashish\Desktop\e5>certutil -encode input1.zip output1.txt Input Length = 202 Output Length = 338 CertUtil: -encode command completed successfully. Notes about "output1.txt": 1. This is the output file from 'certutil'. 2. This has character encoding base64. 3. The file encoding is utf-8. 4. Maximum length of a line is 64. 5. Base64 encoding usually has last few characters as "=". "=" represents padding. 6. The first line in encoded file is: -----BEGIN CERTIFICATE----- 7. Last line in encoded file is: -----END CERTIFICATE----- C:\Users\Ashish\Desktop\e5>certutil -decode output1.txt input2.zip Input Length = 338 Output Length = 202 CertUtil: -decode command completed successfully. Contents of "output1.txt" with header and footer: -----BEGIN CERTIFICATE----- UEsDBBQAAAAAAEy8IVE3rlRbAgAAAAIAAAAGAAAAdDEudHh0dDFQSwMEFAAAAAAA TrwhUY3/XcICAAAAAgAAAAYAAAB0Mi50eHR0MlBLAQIUABQAAAAAAEy8IVE3rlRb AgAAAAIAAAAGAAAAAAAAAAEAIAAAAAAAAAB0MS50eHRQSwECFAAUAAAAAABOvCFR jf9dwgIAAAACAAAABgAAAAAAAAABACAAAAAmAAAAdDIudHh0UEsFBgAAAAACAAIA aAAAAEwAAAAAAA== -----END CERTIFICATE----- Contents of "output1.txt" without header and footer: C:\Users\Ashish\Desktop\e5>type output1.txt | find /V "-----BEGIN CERTIFICATE-----" | find /V "-----END CERTIFICATE-----" UEsDBBQAAAAAAEy8IVE3rlRbAgAAAAIAAAAGAAAAdDEudHh0dDFQSwMEFAAAAAAA TrwhUY3/XcICAAAAAgAAAAYAAAB0Mi50eHR0MlBLAQIUABQAAAAAAEy8IVE3rlRb AgAAAAIAAAAGAAAAAAAAAAEAIAAAAAAAAAB0MS50eHRQSwECFAAUAAAAAABOvCFR jf9dwgIAAAACAAAABgAAAAAAAAABACAAAAAmAAAAdDIudHh0UEsFBgAAAAACAAIA aAAAAEwAAAAAAA== Encoding input file without header and footer: C:\Users\Ashish\Desktop\e5>certutil -encodehex -f input1.zip output2.txt 0x40000001 Input Length = 202 Output Length = 272 CertUtil: -encodehex command completed successfully. Contents of output2.txt: UEsDBBQAAAAAAEy8IVE3rlRbAgAAAAIAAAAGAAAAdDEudHh0dDFQSwMEFAAAAAAATrwhUY3/XcICAAAAAgAAAAYAAAB0Mi50eHR0MlBLAQIUABQAAAAAAEy8IVE3rlRbAgAAAAIAAAAGAAAAAAAAAAEAIAAAAAAAAAB0MS50eHRQSwECFAAUAAAAAABOvCFRjf9dwgIAAAACAAAABgAAAAAAAAABACAAAAAmAAAAdDIudHh0UEsFBgAAAAACAAIAaAAAAEwAAAAAAA== The limitation of size of input file while encoding using certutil:Interesting stats about encoding found in webpages:


Friday, August 28, 2020
Elbow Method for identifying k in kMeans (clustering) and kNN (classification)
Elbow method (clustering)
In cluster analysis, the elbow method is a heuristic used in determining the number of clusters in a data set. The method consists of plotting the explained variation as a function of the number of clusters, and picking the elbow of the curve as the number of clusters to use. The same method can be used to choose the number of parameters in other data-driven models, such as the number of principal components to describe a data set. Intuition Using the "elbow" or "knee of a curve" as a cutoff point is a common heuristic in mathematical optimization to choose a point where diminishing returns are no longer worth the additional cost. In clustering, this means one should choose a number of clusters so that adding another cluster doesn't give much better modeling of the data. The intuition is that increasing the number of clusters will naturally improve the fit (explain more of the variation), since there are more parameters (more clusters) to use, but that at some point this is over-fitting, and the elbow reflects this. For example, given data that actually consist of k labeled groups – for example, k points sampled with noise – clustering with more than k clusters will "explain" more of the variation (since it can use smaller, tighter clusters), but this is over-fitting, since it is subdividing the labeled groups into multiple clusters. The idea is that the first clusters will add much information (explain a lot of variation), since the data actually consist of that many groups (so these clusters are necessary), but once the number of clusters exceeds the actual number of groups in the data, the added information will drop sharply, because it is just subdividing the actual groups. Assuming this happens, there will be a sharp elbow in the graph of explained variation versus clusters: increasing rapidly up to k (under-fitting region), and then increasing slowly after k (over-fitting region). In practice there may not be a sharp elbow, and as a heuristic method, such an "elbow" cannot always be unambiguously identified. Measures of variation There are various measures of "explained variation" used in the elbow method. Most commonly, variation is quantified by variance, and the ratio used is the ratio of between-group variance to the total variance. Alternatively, one uses the ratio of between-group variance to within-group variance, which is the one-way ANOVA F-test statistic.Explained variance. The "elbow" is indicated by the red circle. The number of clusters chosen should therefore be 4. Related Concepts ANOVA Analysis of variance (ANOVA) is a collection of statistical models and their associated estimation procedures (such as the "variation" among and between groups) used to analyze the differences among group means in a sample. ANOVA was developed by the statistician Ronald Fisher. The ANOVA is based on the law of total variance, where the observed variance in a particular variable is partitioned into components attributable to different sources of variation. In its simplest form, ANOVA provides a statistical test of whether two or more population means are equal, and therefore generalizes the t-test beyond two means. Principal component analysis (PCA) Principal component analysis (PCA) is the process of computing the principal components and using them to perform a change of basis on the data, sometimes only using the first few principal components and ignoring the rest. PCA is used in exploratory data analysis and for making predictive models. It is commonly used for dimensionality reduction by projecting each data point onto only the first few principal components to obtain lower-dimensional data while preserving as much of the data's variation as possible. The first principal component can equivalently be defined as a direction that maximizes the variance of the projected data. The i(th) principal component can be taken as a direction orthogonal to the first (i-1) principal components that maximizes the variance of the projected data. Python based Software/source code % Matplotlib – Python library have a PCA package in the .mlab module. % Scikit-learn – Python library for machine learning which contains PCA, Probabilistic PCA, Kernel PCA, Sparse PCA and other techniques in the decomposition module. Reiterating... Determining the number of clusters in a data set Determining the number of clusters in a data set, a quantity often labelled k as in the k-means algorithm, is a frequent problem in data clustering, and is a distinct issue from the process of actually solving the clustering problem. For a certain class of clustering algorithms (in particular k-means, k-medoids and expectation–maximization algorithm), there is a parameter commonly referred to as k that specifies the number of clusters to detect. Other algorithms such as DBSCAN and OPTICS algorithm do not require the specification of this parameter; hierarchical clustering avoids the problem altogether. The correct choice of k is often ambiguous, with interpretations depending on the shape and scale of the distribution of points in a data set and the desired clustering resolution of the user. In addition, increasing k without penalty will always reduce the amount of error in the resulting clustering, to the extreme case of zero error if each data point is considered its own cluster (i.e., when k equals the number of data points, n). Intuitively then, the optimal choice of k will strike a balance between maximum compression of the data using a single cluster, and maximum accuracy by assigning each data point to its own cluster. If an appropriate value of k is not apparent from prior knowledge of the properties of the data set, it must be chosen somehow. There are several categories of methods for making this decision. The elbow method for clustering The elbow method looks at the percentage of variance explained as a function of the number of clusters: One should choose a number of clusters so that adding another cluster doesn't give much better modeling of the data. More precisely, if one plots the percentage of variance explained by the clusters against the number of clusters, the first clusters will add much information (explain a lot of variance), but at some point the marginal gain will drop, giving an angle in the graph. The number of clusters is chosen at this point, hence the "elbow criterion". This "elbow" cannot always be unambiguously identified, making this method very subjective and unreliable. Percentage of variance explained is the ratio of the between-group variance to the total variance, also known as an F-test. A slight variation of this method plots the curvature of the within group variance. The silhouette method (for clustering) The average silhouette of the data is another useful criterion for assessing the natural number of clusters. The silhouette of a data instance is a measure of how closely it is matched to data within its cluster and how loosely it is matched to data of the neighbouring cluster, i.e. the cluster whose average distance from the datum is lowest. A silhouette close to 1 implies the datum is in an appropriate cluster, while a silhouette close to −1 implies the datum is in the wrong cluster. Optimization techniques such as genetic algorithms are useful in determining the number of clusters that gives rise to the largest silhouette. It is also possible to re-scale the data in such a way that the silhouette is more likely to be maximised at the correct number of clusters. Silhouette coefficient The Silhouette Coefficient is calculated using the mean intra-cluster distance (a) and the mean nearest-cluster distance (b) for each sample. The Silhouette Coefficient for a sample is (b - a) / max(a, b). To clarify, b is the distance between a sample and the nearest cluster that the sample is not a part of. We can compute the mean Silhouette Coefficient over all samples and use this as a metric to judge the number of clusters. Ref 1: Elbow method (clustering) Ref 2: F-test Ref 3: Analysis of variance Ref 4: Principal component analysis Ref 5: Determining the number of clusters in a data set Elbow Method for optimal value of k in KMeans (using 'Distortion' and 'Inertia' and not with explainable variance) A fundamental step for any unsupervised algorithm is to determine the optimal number of clusters into which the data may be clustered. The Elbow Method is one of the most popular methods to determine this optimal value of k. We now define the following: Distortion: It is calculated as the average of the squared distances from the cluster centers of the respective clusters. Typically, the Euclidean distance metric is used.Inertia: It is the sum of squared distances of samples to their closest cluster center.Ref 6: Determining the optimal number of clusters Ref 7: Choosing the number of clusters (Coursera) In code from sklearn.cluster import KMeans from sklearn import metrics from scipy.spatial.distance import cdist import numpy as np import matplotlib.pyplot as plt %matplotlib inline #Creating the data x1 = np.array([3, 1, 1, 2, 1, 6, 6, 6, 5, 6, 7, 8, 9, 8, 9, 9, 8]) x2 = np.array([5, 4, 5, 6, 5, 8, 6, 7, 6, 7, 1, 2, 1, 2, 3, 2, 3]) X = np.array(list(zip(x1, x2))).reshape(len(x1), 2) #Visualizing the data plt.plot() plt.xlim([0, 10]) plt.ylim([0, 10]) plt.title('Dataset') plt.scatter(x1, x2) plt.show()distortions = [] inertias = [] mapping1 = {} mapping2 = {} K = range(1,10) for k in K: #Building and fitting the model kmeanModel = KMeans(n_clusters=k).fit(X) kmeanModel.fit(X) distortions.append(sum(np.min(cdist(X, kmeanModel.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0]) inertias.append(kmeanModel.inertia_) mapping1[k] = sum(np.min(cdist(X, kmeanModel.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0] mapping2[k] = kmeanModel.inertia_ for key, val in mapping1.items(): print(str(key), ': ', str(val)) plt.plot(K, distortions, 'bx-') plt.xlabel('Values of K') plt.ylabel('Distortion') plt.title('The Elbow Method using Distortion') plt.show()for key, val in mapping2.items(): print(str(key), ': ', str(val)) plt.plot(K, inertias, 'bx-') plt.xlabel('Values of K') plt.ylabel('Inertia') plt.title('The Elbow Method using Inertia') plt.show()A note about np.array(), np.min() and "from scipy.spatial.distance import cdist"Elbow Method for kNN (classification problem)
How to select the optimal K value (representing the number of Nearest Neighbors)? - Initialize a random K value and start computing. - Choosing a small value of K leads to unstable decision boundaries. - The substantial K value is better for classification as it leads to smoothening the decision boundaries. - Derive a plot between error rate and K denoting values in a defined range. Then choose the K value as having a minimum error rate. - Instead of "error", one could also plot for 'accuracy' against 'K'. With error, the curve is decreasing with K. With accuracy, the curve is increasing with K.









Wednesday, August 26, 2020
Deploying Flask based 'Hello World' REST API on Heroku Cloud
Getting Started on Heroku with Python Basic requirement: - a free Heroku account - Python version 3.7 installed locally - see the installation guides for OS X, Windows, and Linux. - Heroku CLI requires Git You can Git from here: git-scm - For first time Git setup:Getting-Started-First-Time-Git-Setup Heroku CLI is avaiable for macOS, Windows and Linux. You use the Heroku CLI to manage and scale your applications, provision add-ons, view your application logs, and run your application locally. Once installed, you can use the heroku command from your command shell. On Windows, start the Command Prompt (cmd.exe) or Powershell to access the command shell. Use the heroku login command to log in to the Heroku CLI: (base) C:\Users\Ashish Jain>heroku login heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/cli/browser/716***J1k heroku: Waiting for login... -(base) C:\Users\Ashish Jain>heroku login heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/cli/browser/716***J1k Logging in... done Logged in as a***@gmail.comCreate the app
Create an app on Heroku, which prepares Heroku to receive your source code: When you create an app, a git remote (called heroku) is also created and associated with your local git repository. Heroku generates a random name (in this case serene-caverns-82714) for your app, or you can pass a parameter to specify your own app name. (base) C:\Users\Ashish Jain\OneDrive\Desktop>cd myapp (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp>dir Directory of C:\Users\Ashish Jain\OneDrive\Desktop\myapp 0 File(s) 0 bytes (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp>heroku create Creating app... done, ⬢ rocky-spire-96801 https://rocky-spire-96801.herokuapp.com/ | https://git.heroku.com/rocky-spire-96801.git (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp>git clone https://git.heroku.com/rocky-spire-96801.git Cloning into 'rocky-spire-96801'... warning: You appear to have cloned an empty repository.Writing a Python Script file
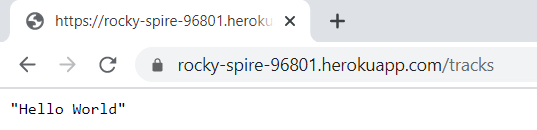
We are at: C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801 We create a Python script: MyRESTAPIUsingPythonScript.py It has following code: from flask import Flask, request from flask_restful import Resource, Api import os app = Flask(__name__) api = Api(app) class Tracks(Resource): def get(self): result = "Hello World" return result api.add_resource(Tracks, '/tracks') # URL Route if __name__ == '__main__': port = int(os.environ.get('PORT', 5000)) app.run(host='0.0.0.0', port=port) In the code above: Heroku dynamically assigns your app a port, so we cannot set the port to a fixed number. Heroku adds the port to the env, so we pull it from there. Wrong Code 1 if __name__ == '__main__': app.run(port='5002') Error Logs: 2020-08-26T16:20:58.493306+00:00 app[web.1]: * Running on http://127.0.0.1:5002/ (Press CTRL+C to quit) ... 2020-08-26T16:23:01.745361+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:23:01.782641+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:23:01.914043+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:23:01.987508+00:00 heroku[web.1]: State changed from starting to crashed Wrong Code 2 if __name__ == '__main__': app.run() Error logs: (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logs ... 2020-08-26T16:27:43.161519+00:00 app[web.1]: * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) 2020-08-26T16:27:45.000000+00:00 app[api]: Build succeeded 2020-08-26T16:28:40.527069+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:28:40.548232+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:28:40.611066+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:28:40.655930+00:00 heroku[web.1]: State changed from starting to crashed Wrong Code 3 if __name__ == '__main__': app.run(host='0.0.0.0') (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logs ... 2020-08-26T16:35:36.792884+00:00 heroku[web.1]: Starting process with command `python MyRESTAPIUsingPythonScript.py` 2020-08-26T16:35:40.000000+00:00 app[api]: Build succeeded 2020-08-26T16:35:40.100687+00:00 app[web.1]: * Serving Flask app "MyRESTAPIUsingPythonScript" (lazy loading) 2020-08-26T16:35:40.100727+00:00 app[web.1]: * Environment: production 2020-08-26T16:35:40.100730+00:00 app[web.1]: WARNING: This is a development server. Do not use it in a production deployment. 2020-08-26T16:35:40.100738+00:00 app[web.1]: Use a production WSGI server instead. 2020-08-26T16:35:40.100767+00:00 app[web.1]: * Debug mode: off 2020-08-26T16:35:40.103621+00:00 app[web.1]: * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) 2020-08-26T16:37:41.234182+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:37:41.260167+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:37:41.377892+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:37:41.426917+00:00 heroku[web.1]: State changed from starting to crashed About "git commit" logs Every time we do changes and commit, Heroku knows which release this is. See below, it says "Released v6": (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git add . (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git commit -m "1012" [master a4975c0] 1012 1 file changed, 3 insertions(+), 1 deletion(-) (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push Enumerating objects: 5, done. Counting objects: 100% (5/5), done. Delta compression using up to 4 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (3/3), 423 bytes | 423.00 KiB/s, done. Total 3 (delta 1), reused 0 (delta 0), pack-reused 0 remote: Compressing source files... done. remote: Building source: remote: remote: -----> Python app detected remote: -----> No change in requirements detected, installing from cache remote: -----> Installing pip 20.1.1, setuptools 47.1.1 and wheel 0.34.2 remote: -----> Installing SQLite3 remote: -----> Installing requirements with pip remote: -----> Discovering process types remote: Procfile declares types -> web remote: remote: -----> Compressing... remote: Done: 45.6M remote: -----> Launching... remote: Released v6 remote: https://rocky-spire-96801.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/rocky-spire-96801.git 0391d70..a4975c0 master -> masterDefine a Procfile
We create a file "Procfile" at: C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801 Based on our code (which is a Python script to run a simple Flask based REST API), we write in Procfile: web: python MyRESTAPIUsingPythonScript.py Procfile naming and location The Procfile is always a simple text file that is named Procfile without a file extension. For example, Procfile.txt is not valid. The Procfile must live in your app’s root directory. It does not function if placed anywhere else. Procfile format A Procfile declares its process types on individual lines, each with the following format: [process type]: [command] [process type] is an alphanumeric name for your command, such as web, worker, urgentworker, clock, and so on. [command] indicates the command that every dyno of the process type should execute on startup, such as rake jobs:work. The "web" process type A Heroku app’s web process type is special: it’s the only process type that can receive external HTTP traffic from Heroku’s routers. If your app includes a web server, you should declare it as your app’s web process. For example, the Procfile for a Rails web app might include the following process type: web: bundle exec rails server -p $PORT In this case, every web dyno executes bundle exec rails server -p $PORT, which starts up a web server. A Clojure app’s web process type might look like this: web: lein run -m demo.web $PORT You can refer to your app’s config vars, most usefully $PORT, in the commands you specify. This might be the web process type for an executable Java JAR file, such as when using Spring Boot: web: java -jar target/myapp-1.0.0.jar More on Procfile here: devcenter.heroku Deploying to Heroku A Procfile is not technically required to deploy simple apps written in most Heroku-supported languages—the platform automatically detects the language and creates a default web process type to boot the application server. However, creating an explicit Procfile is recommended for greater control and flexibility over your app. For Heroku to use your Procfile, add the Procfile to the root directory of your application, then push to Heroku: (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>dir Directory of C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801 08/26/2020 09:47 PM [DIR] . 08/26/2020 09:47 PM [DIR] .. 08/26/2020 09:40 PM 326 MyRESTAPIUsingPythonScript.py 08/26/2020 09:42 PM 41 Procfile 08/26/2020 09:33 PM 22 requirements.txt 3 File(s) 389 bytes 2 Dir(s) 65,828,458,496 bytes free (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git add . (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git commit -m "first commit" [master (root-commit) ff73728] first commit 3 files changed, 18 insertions(+) create mode 100644 MyRESTAPIUsingPythonScript.py create mode 100644 Procfile create mode 100644 requirements.txt As opposed to what appears on the Heroku documentation, we simply have to do "git push" now. Otherwise we see following errors: (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push heroku master fatal: 'heroku' does not appear to be a git repository fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists. (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push master fatal: 'master' does not appear to be a git repository fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists. (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>git push Enumerating objects: 5, done. Counting objects: 100% (5/5), done. Delta compression using up to 4 threads Compressing objects: 100% (3/3), done. Writing objects: 100% (5/5), 585 bytes | 292.00 KiB/s, done. Total 5 (delta 0), reused 0 (delta 0), pack-reused 0 remote: Compressing source files... done. remote: Building source: remote: remote: -----> Python app detected remote: -----> Installing python-3.6.12 remote: -----> Installing pip 20.1.1, setuptools 47.1.1 and wheel 0.34.2 remote: -----> Installing SQLite3 remote: -----> Installing requirements with pip remote: Collecting flask remote: Downloading Flask-1.1.2-py2.py3-none-any.whl (94 kB) remote: Collecting flask_restful remote: Downloading Flask_RESTful-0.3.8-py2.py3-none-any.whl (25 kB) remote: Collecting click>=5.1 remote: Downloading click-7.1.2-py2.py3-none-any.whl (82 kB) remote: Collecting Jinja2>=2.10.1 remote: Downloading Jinja2-2.11.2-py2.py3-none-any.whl (125 kB) remote: Collecting Werkzeug>=0.15 remote: Downloading Werkzeug-1.0.1-py2.py3-none-any.whl (298 kB) remote: Collecting itsdangerous>=0.24 remote: Downloading itsdangerous-1.1.0-py2.py3-none-any.whl (16 kB) remote: Collecting pytz remote: Downloading pytz-2020.1-py2.py3-none-any.whl (510 kB) remote: Collecting aniso8601>=0.82 remote: Downloading aniso8601-8.0.0-py2.py3-none-any.whl (43 kB) remote: Collecting six>=1.3.0 remote: Downloading six-1.15.0-py2.py3-none-any.whl (10 kB) remote: Collecting MarkupSafe>=0.23 remote: Downloading MarkupSafe-1.1.1-cp36-cp36m-manylinux1_x86_64.whl (27 kB) remote: Installing collected packages: click, MarkupSafe, Jinja2, Werkzeug, itsdangerous, flask, pytz, aniso8601, six, flask-restful remote: Successfully installed Jinja2-2.11.2 MarkupSafe-1.1.1 Werkzeug-1.0.1 aniso8601-8.0.0 click-7.1.2 flask-1.1.2 flask-restful-0.3.8 itsdangerous-1.1.0 pytz-2020.1 six-1.15.0 remote: -----> Discovering process types remote: Procfile declares types -> web remote: remote: -----> Compressing... remote: Done: 45.6M remote: -----> Launching... remote: Released v3 remote: https://rocky-spire-96801.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/rocky-spire-96801.git * [new branch] master -> master Checking Heroku process status (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku ps Free dyno hours quota remaining this month: 550h 0m (100%) Free dyno usage for this app: 0h 0m (0%) For more information on dyno sleeping and how to upgrade, see: https://devcenter.heroku.com/articles/dyno-sleeping === web (Free): python MyRESTAPIUsingPythonScript.py (1) web.1: restarting 2020/08/26 21:51:56 +0530 (~ 41s ago) (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku ps Free dyno hours quota remaining this month: 550h 0m (100%) Free dyno usage for this app: 0h 0m (0%) For more information on dyno sleeping and how to upgrade, see: https://devcenter.heroku.com/articles/dyno-sleeping === web (Free): python MyRESTAPIUsingPythonScript.py (1) web.1: up 2020/08/26 22:28:06 +0530 (~ 12m ago) Check Logs (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logs 2020-08-26T15:55:49.855840+00:00 app[api]: Initial release by user a***@gmail.com 2020-08-26T15:55:49.855840+00:00 app[api]: Release v1 created by user a***@gmail.com 2020-08-26T15:55:49.992678+00:00 app[api]: Enable Logplex by user a***@gmail.com 2020-08-26T15:55:49.992678+00:00 app[api]: Release v2 created by user a***@gmail.com 2020-08-26T16:20:26.000000+00:00 app[api]: Build started by user a***@gmail.com 2020-08-26T16:20:51.873133+00:00 app[api]: Release v3 created by user a***@gmail.com 2020-08-26T16:20:51.873133+00:00 app[api]: Deploy ff73728d by user a***@gmail.com 2020-08-26T16:20:51.891792+00:00 app[api]: Scaled to web@1:Free by user a***@gmail.com 2020-08-26T16:20:55.659055+00:00 heroku[web.1]: Starting process with command `python MyRESTAPIUsingPythonScript.py` 2020-08-26T16:20:58.489161+00:00 app[web.1]: * Serving Flask app "MyRESTAPIUsingPythonScript" (lazy loading) 2020-08-26T16:20:58.489192+00:00 app[web.1]: * Environment: production 2020-08-26T16:20:58.489257+00:00 app[web.1]: WARNING: This is a development server. Do not use it in a production deployment. 2020-08-26T16:20:58.489350+00:00 app[web.1]: Use a production WSGI server instead. 2020-08-26T16:20:58.489393+00:00 app[web.1]: * Debug mode: off 2020-08-26T16:20:58.493306+00:00 app[web.1]: * Running on http://127.0.0.1:5002/ (Press CTRL+C to quit) 2020-08-26T16:21:00.000000+00:00 app[api]: Build succeeded 2020-08-26T16:28:40.527069+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch 2020-08-26T16:28:40.548232+00:00 heroku[web.1]: Stopping process with SIGKILL 2020-08-26T16:28:40.611066+00:00 heroku[web.1]: Process exited with status 137 2020-08-26T16:28:40.655930+00:00 heroku[web.1]: State changed from starting to crashed ... 2020-08-26T16:43:04.803725+00:00 heroku[web.1]: State changed from crashed to starting 2020-08-26T16:43:07.586143+00:00 heroku[web.1]: Starting process with command `python MyRESTAPIUsingPythonScript.py` 2020-08-26T16:43:09.742529+00:00 app[web.1]: * Serving Flask app "MyRESTAPIUsingPythonScript" (lazy loading) 2020-08-26T16:43:09.742547+00:00 app[web.1]: * Environment: production 2020-08-26T16:43:09.742586+00:00 app[web.1]: WARNING: This is a development server. Do not use it in a production deployment. 2020-08-26T16:43:09.742625+00:00 app[web.1]: Use a production WSGI server instead. 2020-08-26T16:43:09.742662+00:00 app[web.1]: * Debug mode: off 2020-08-26T16:43:09.745322+00:00 app[web.1]: * Running on http://0.0.0.0:32410/ (Press CTRL+C to quit) 2020-08-26T16:43:09.847177+00:00 heroku[web.1]: State changed from starting to up 2020-08-26T16:43:12.000000+00:00 app[api]: Build succeeded (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku open In Firefox browser with URL: https://rocky-spire-96801.herokuapp.com/ Not Found The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again. In Firefox at URL: https://rocky-spire-96801.herokuapp.com/tracksIn Chrome at URL: https://rocky-spire-96801.herokuapp.com/tracksLogout (base) C:\Users\Ashish Jain\OneDrive\Desktop\myapp\rocky-spire-96801>heroku logout Logging out... done



Tuesday, August 25, 2020
Working with 'dir' command on Windows CMD prompt
# Finding a file/folder with a string in its name.Note: /s Lists every occurrence of the specified file name within the specified directory and all subdirectories. Exploring "dir" documentation C:\Users\Ashish Jain>help dir Displays a list of files and subdirectories in a directory. DIR [drive:][path][filename] [/A[[:]attributes]] [/B] [/C] [/D] [/L] [/N] [/O[[:]sortorder]] [/P] [/Q] [/R] [/S] [/T[[:]timefield]] [/W] [/X] [/4] [drive:][path][filename] Specifies drive, directory, and/or files to list. /A Displays files with specified attributes. attributes D Directories R Read-only files H Hidden files A Files ready for archiving S System files I Not content indexed files L Reparse Points - Prefix meaning not /B Uses bare format (no heading information or summary). /C Display the thousand separator in file sizes. This is the default. Use /-C to disable display of separator. /D Same as wide but files are list sorted by column. /L Uses lowercase. /N New long list format where filenames are on the far right. /O List by files in sorted order. sortorder N By name (alphabetic) S By size (smallest first) E By extension (alphabetic) D By date/time (oldest first) G Group directories first - Prefix to reverse order /P Pauses after each screenful of information. /Q Display the owner of the file. /R Display alternate data streams of the file. /S Displays files in specified directory and all subdirectories. /T Controls which time field displayed or used for sorting timefield C Creation A Last Access W Last Written /W Uses wide list format. /X This displays the short names generated for non-8dot3 file names. The format is that of /N with the short name inserted before the long name. If no short name is present, blanks are displayed in its place. /4 Displays four-digit years Switches may be preset in the DIRCMD environment variable. Override preset switches by prefixing any switch with - (hyphen)--for example, /-W. --- --- --- --- --- # You can include files in the current or named directory plus all of its accessible subdirectories by using the /S option. This example displays all of the .WKS and .WK1 files in the D:\DATA directory and each of its subdirectories: dir /s d:\data\*.wks;*.wk1 --- --- --- --- --- # Look for text files in D: drive containing the letter 'ACC' in the case-insensitive manner. dir /s D:\*ACC*.txt OUTPUT: Directory of D:\Downloads\rw\jakarta-tomcat-8.0.35\logs 30-Dec-16 02:05 PM 61,549 localhost_access_log.2016-10-06.txt ... Directory of D:\Work Space\rw_new\temp\iTAP\licenses 27-Jan-16 07:46 PM 1,536 javacc-license.txt 1 File(s) 1,536 bytes --- --- --- --- --- We have following directory structure in a "test" folder: C:\Users\Ashish Jain\OneDrive\Desktop\test>tree /f Folder PATH listing for volume Windows Volume serial number is 8139-90C0 C:. │ 3.txt │ ├───1 │ └───a │ file.txt │ └───2 file_2.txt 1. List everything in this directory: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s/b C:\Users\Ashish Jain\OneDrive\Desktop\test\1 C:\Users\Ashish Jain\OneDrive\Desktop\test\2 C:\Users\Ashish Jain\OneDrive\Desktop\test\3.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a\file.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\2\file_2.txt 2. List subdirectories of this directory: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s/b /A:D C:\Users\Ashish Jain\OneDrive\Desktop\test\1 C:\Users\Ashish Jain\OneDrive\Desktop\test\2 C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a 3. List files in this directory and subdirectories: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s/b /A:-D C:\Users\Ashish Jain\OneDrive\Desktop\test\3.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a\file.txt C:\Users\Ashish Jain\OneDrive\Desktop\test\2\file_2.txt Explanation for ‘dir /A:D’: D:\>dir /? Displays a list of files and subdirectories in a directory. DIR [drive:][path][filename] [/A[[:]attributes]] [/B] [/C] [/D] [/L] [/N] [/O[[:]sortorder]] [/P] [/Q] [/R] [/S] [/T[[:]timefield]] [/W] [/X] [/4] [drive:][path][filename] Specifies drive, directory, and/or files to list. /A Displays files with specified attributes. attributes D Directories R Read-only files H Hidden files A Files ready for archiving S System files I Not content indexed files L Reparse Points - Prefix meaning not Another way of listing only subdirectories: C:\Users\Ashish Jain\OneDrive\Desktop\test>dir /s | find "\" Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test\1 Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test\1\a Directory of C:\Users\Ashish Jain\OneDrive\Desktop\test\2

Subscribe to:
Comments (Atom)