Unit 1 - Introducting Google Analytics



 Unit 2 - Google Analytics Interface
Unit 2 - Google Analytics Interface



 Unit 3 - Basic Reports
Unit 3 - Basic Reports





 Unit 4 - Basic Campaign and Conversion Tracking
Unit 4 - Basic Campaign and Conversion Tracking






Tuesday, October 20, 2020
Google Analytics for Beginners (Assessments Dump)
























Monday, October 19, 2020
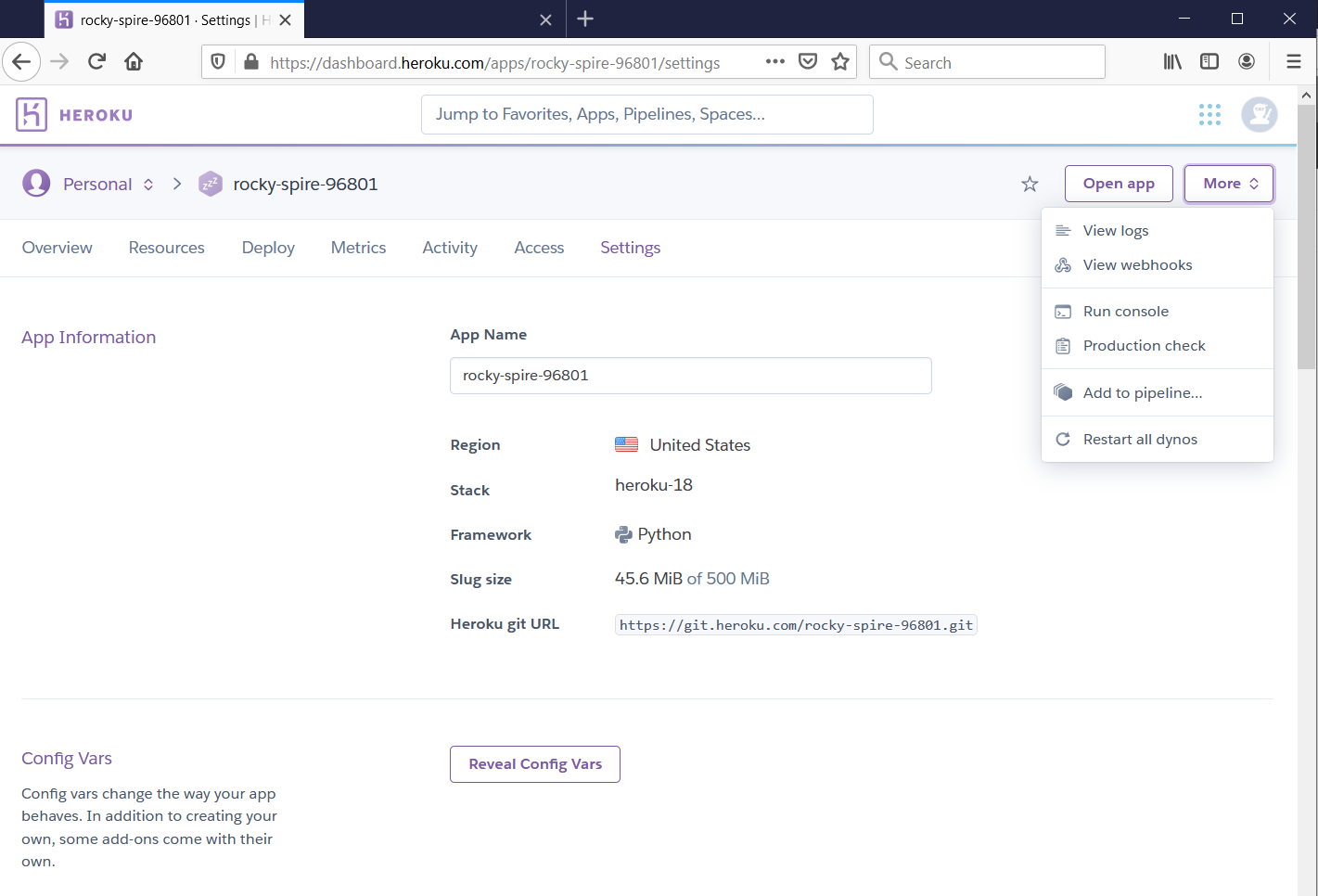
Heroku Dashboard And Settings
Heroku Dashboard URL: https://dashboard.heroku.com/appsWe have two projects hosted on Heroku Cloud: 1. polar-mountain-... 2. rocky-spire-... We would open the settings for "rocky-spire". https://dashboard.heroku.com/apps/rocky-spire-96801/settings Project "Settings"Even if somebody has your project name and 'git.heroku.com' link, the project is safe and protected by a login prompt as shown below:If you want to see additional settings, they appear below on the page such as in these screenshots:Additional Settings to 'Transfer App Ownership', 'Turn on Maintenance Mode' and 'Delete App':'rocky-spire' Resources https://dashboard.heroku.com/apps/rocky-spire-96801/resourcesIf you have an 'Add-On' such as a Postgres Database, it will also show up in 'Resources' Tab:'Deployment' Tab https://dashboard.heroku.com/apps/rocky-spire-96801/deploy/heroku-git'Activity' Tab https://dashboard.heroku.com/apps/rocky-spire-96801/activity'Access' Tab https://dashboard.heroku.com/apps/rocky-spire-96801/access'Overview' Tab https://dashboard.heroku.com/apps/rocky-spire-96801Note: An app hosted on Heroku may not have a 'Homepage' but may show content via an API endpoint. See images below: For URL: https://rocky-spire-96801.herokuapp.com/For URL: https://rocky-spire-96801.herokuapp.com/tracksInteresting Fact: When type "abc..." and hit enter in Visual Studio Code, the VS Code auto-completes this 'abc...' to "<abc class=''></abc>"
















Sunday, October 18, 2020
Data Visualization's Basic Theory
DefinitionWhy should we be interested in visualization? Abelas' Chart Selection Diagram
Abelas' Chart Selection Diagram Some principles of effective visualizations
Some principles of effective visualizations Basic components of every chart
Basic components of every chart Combo-chart: Line plot, Column chart (or Bar graph) combined
Combo-chart: Line plot, Column chart (or Bar graph) combined Comba-chart: Stacked Column Chart
Comba-chart: Stacked Column Chart Heat Maps
Heat Maps Grouped Column Chart and Stacked Column Chart: For doing data comparison
Grouped Column Chart and Stacked Column Chart: For doing data comparison












Thursday, October 15, 2020
BERT is aware of the context of a word in a sentence
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.metrics.pairwise import cosine_similarity
import torch
import transformers as ppb
import warnings
warnings.filterwarnings('ignore')
from joblib import load, dump
import json
import re
print(ppb.__version__)
'3.0.1'
Loading the Pre-trained BERT model
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
# Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
When run first time, the above statements loads a model of 440MB in size.
Word Ambiguities
def get_embedding(in_list):
tokenized = [tokenizer.encode(x, add_special_tokens=True) for x in in_list]
max_len = 0
for i in tokenized:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0]*(max_len-len(i)) for i in tokenized])
attention_mask = np.where(padded != 0, 1, 0)
input_ids = torch.LongTensor(padded)
attention_mask = torch.tensor(attention_mask)
with torch.no_grad():
last_hidden_states = model(input_ids = input_ids, attention_mask = attention_mask)
features = last_hidden_states[0][:,0,:].numpy()
return features
python_strings = [
'I love coding in Python language.',
'Python is more readable than Java.',
'Pythons are famous for their very long body.',
'Python is famous for its very long body.',
'All six continents have a python species.',
'Python is a programming language.',
'Python is a reptile.',
'The python ate a mouse.',
'python ate a mouse'
]
string_embeddings = get_embedding(python_strings)
print(string_embeddings.shape)
(9, 768)
csm = cosine_similarity(X = string_embeddings, Y=None, dense_output=True)
print(csm.round(2))
In the picture below, if we ignore the diagnol (that is similarity of a sentence to itself), we are able to see which sentence is closer to which.
[[1. 0.83 0.8 0.79 0.8 0.84 0.84 0.81 0.81]
[0.83 1. 0.79 0.76 0.8 0.87 0.79 0.8 0.79]
[0.8 0.79 1. 0.96 0.86 0.77 0.88 0.77 0.78]
[0.79 0.76 0.96 1. 0.82 0.77 0.9 0.75 0.77]
[0.8 0.8 0.86 0.82 1. 0.78 0.85 0.8 0.8 ]
[0.84 0.87 0.77 0.77 0.78 1. 0.81 0.76 0.78]
[0.84 0.79 0.88 0.9 0.85 0.81 1. 0.81 0.86]
[0.81 0.8 0.77 0.75 0.8 0.76 0.81 1. 0.9 ]
[0.81 0.79 0.78 0.77 0.8 0.78 0.86 0.9 1. ]]
for i in range(len(csm)):
ord_indx = np.argsort(csm[i])[::-1]
print(python_strings[ord_indx[0]])
print([python_strings[j] for j in ord_indx[1:]])
print()
I love coding in Python language.
['Python is a reptile.', 'Python is a programming language.', 'Python is more readable than Java.', 'python ate a mouse', 'The python ate a mouse.', 'All six continents have a python species.', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.']
Python is more readable than Java.
['Python is a programming language.', 'I love coding in Python language.', 'All six continents have a python species.', 'The python ate a mouse.', 'Python is a reptile.', 'python ate a mouse', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.']
Pythons are famous for their very long body.
['Python is famous for its very long body.', 'Python is a reptile.', 'All six continents have a python species.', 'I love coding in Python language.', 'Python is more readable than Java.', 'python ate a mouse', 'Python is a programming language.', 'The python ate a mouse.']
Python is famous for its very long body.
['Pythons are famous for their very long body.', 'Python is a reptile.', 'All six continents have a python species.', 'I love coding in Python language.', 'python ate a mouse', 'Python is a programming language.', 'Python is more readable than Java.', 'The python ate a mouse.']
All six continents have a python species.
['Pythons are famous for their very long body.', 'Python is a reptile.', 'Python is famous for its very long body.', 'I love coding in Python language.', 'Python is more readable than Java.', 'The python ate a mouse.', 'python ate a mouse', 'Python is a programming language.']
Python is a programming language.
['Python is more readable than Java.', 'I love coding in Python language.', 'Python is a reptile.', 'All six continents have a python species.', 'python ate a mouse', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.', 'The python ate a mouse.']
Python is a reptile.
['Python is famous for its very long body.', 'Pythons are famous for their very long body.', 'python ate a mouse', 'All six continents have a python species.', 'I love coding in Python language.', 'Python is a programming language.', 'The python ate a mouse.', 'Python is more readable than Java.']
The python ate a mouse.
['python ate a mouse', 'I love coding in Python language.', 'Python is a reptile.', 'All six continents have a python species.', 'Python is more readable than Java.', 'Pythons are famous for their very long body.', 'Python is a programming language.', 'Python is famous for its very long body.']
python ate a mouse
['The python ate a mouse.', 'Python is a reptile.', 'I love coding in Python language.', 'All six continents have a python species.', 'Python is more readable than Java.', 'Python is a programming language.', 'Pythons are famous for their very long body.', 'Python is famous for its very long body.']
Few observations
1. "python ate a mouse" is more closer to "Python is a reptile." than "The python ate a mouse."
For closeness of these sentences to "Python is a reptile" shows "python ate a mouse" at number 3 while "The python ate a mouse" appears at number 7.
2. The model we are using is "uncased" so capitalization does not matter.
3. Sentences about Python language are similar to each other, and sentences about Python reptile are similar to each other.
4. Word "python" or "Python" alone is closest to 'I love coding in Python language.' then to 'Python is a reptile.', see code snippet below.
from scipy.spatial import distance
python_embedding = get_embedding('python')
csm = [1 - distance.cosine(u = python_embedding[0], v = i) for i in string_embeddings]
print([python_strings[j] for j in np.argsort(csm)[::-1]])
['I love coding in Python language.',
'Python is a reptile.',
'python ate a mouse',
'The python ate a mouse.',
'All six continents have a python species.',
'Python is a programming language.',
'Python is more readable than Java.',
'Python is famous for its very long body.',
'Pythons are famous for their very long body.']
Wednesday, October 14, 2020
Compare pip and conda installations
1. View all environments. (base) C:\Users\aj>conda env list # conda environments: # base * D:\programfiles\Anaconda3 bert_aas D:\programfiles\Anaconda3\envs\bert_aas e20200909 D:\programfiles\Anaconda3\envs\e20200909 ... tf D:\programfiles\Anaconda3\envs\tf 2. View all Jupyter Kernels. (base) C:\Users\aj>jupyter kernelspec list Available kernels: temp C:\Users\aj\AppData\Roaming\jupyter\kernels\temp tf C:\Users\aj\AppData\Roaming\jupyter\kernels\tf python3 D:\programfiles\Anaconda3\share\jupyter\kernels\python3 py38 C:\ProgramData\jupyter\kernels\py38 (base) C:\Users\aj> ========== 3. A note about updating a package in Conda (from debugging instructions). (base) C:\Users\aj>conda update ipykernel jupyter -c conda-forge Updating ipykernel is constricted by anaconda -> requires ipykernel==5.1.4=py37h39e3cac_0 If you are sure you want an update of your package either try `conda update --all` or install a specific version of the package you want using `conda install [pkg]=[version]` done ==> WARNING: A newer version of conda exists. current version: 4.8.4 latest version: 4.8.5 Please update conda by running $ conda update -n base -c defaults conda In this command, by '-n base' we mean 'base' is the name of the environment. By '-c defaults', we mean download 'conda' from the 'defaults' channel. Note: Following are three commonly used channels for downloading Python packages: 1. pkgs/main 2. defaults 3. conda-forge ========== 4. Installing a new Jupyter kernel. (e20200909) CMD>python -m ipykernel install --user --name e20200909 Installed kernelspec e20200909 in C:\Users\aj\AppData\Roaming\jupyter\kernels\e20200909 ========== 5. Checking installation Differentiating between 'pip' and 'conda' installation. (e20200909) D:\ws\jupyter>pip freeze | findstr /C:"jupyter" /C:"jupyterlab" jupyter-client @ file:///tmp/build/80754af9/jupyter_client_1594826976318/work jupyter-console @ file:///home/conda/feedstock_root/build_artifacts/jupyter_console_1598728807792/work jupyter-core==4.6.3 jupyterlab==2.2.8 jupyterlab-pygments @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_pygments_1601375948261/work jupyterlab-server @ file:///home/conda/feedstock_root/build_artifacts/jupyterlab_server_1593951277307/work (e20200909) C:\Users\aj>pip freeze | findstr /C:"transformers" /C:"tensorflow" /C:"torch" torch @ file:///C:/ci/pytorch_1596373105144/work transformers==3.0.1 Important Note: In the above two outputs, where we see a "@ file" based path in place of package version, that package has been installed via 'conda'. (e20200909) C:\Users\aj>python -c "import torch; print(torch.__version__);" 1.6.0 View only Conda installations (e20200909) CMD>pip freeze | findstr /C:"file" argon2-cffi @ file:///D:/bld/argon2-cffi_1596630042503/work attrs @ file:///home/conda/feedstock_root/build_artifacts/attrs_1599308529326/work bleach @ file:///home/conda/feedstock_root/build_artifacts/bleach_1600454382015/work cffi @ file:///C:/ci/cffi_1598352710791/work ... View only Pip installations (e20200909) CMD>pip freeze | findstr /v /C:"file" async-generator==1.10 backcall==0.2.0 bert-serving-client==1.10.0 bert-serving-server==1.10.0 certifi==2020.6.20 chardet==3.0.4 click==7.1.2 ... (e20200909) CMD>pip list Package Version ------------------- ------------------- argon2-cffi 20.1.0 async-generator 1.10 attrs 20.2.0 backcall 0.2.0 bert-serving-client 1.10.0 bert-serving-server 1.10.0 bleach 3.2.1 certifi 2020.6.20 cffi 1.14.2 chardet 3.0.4 click 7.1.2 ... ========== 6. Conda has more clarity about getting a good match between versions of already installed packages and the new packages that are to be installed: (e20200909) C:\Users\Ashish Jain>conda install tensorflow -c conda-forge Collecting package metadata (repodata.json): done Solving environment: failed with initial frozen solve. Retrying with flexible solve. Solving environment: - Found conflicts! Looking for incompatible packages. This can take several minutes. Press CTRL-C to abort. Examining python=3.8: 50%|███████████████ | 1/2 [00:03<00:03, 3.41s/it]-failed UnsatisfiableError: The following specifications were found to be incompatible with the existing python installation in your environment: Specifications: - tensorflow -> python[version='3.5.*|3.6.*|>=3.5,<3.6.0a0|>=3.6,<3.7.0a0|>=3.7,<3.8.0a0|3.7.*'] Your python: python=3.8 If python is on the left-most side of the chain, that's the version you've asked for. When python appears to the right, that indicates that the thing on the left is somehow not available for the python version you are constrained to. Note that conda will not change your python version to a different minor version unless you explicitly specify that. ========== 7. Getting all the available versions of a package in PyPI: (base) CMD>pip install tensorflow== ERROR: Could not find a version that satisfies the requirement tensorflow== (from versions: 1.13.0rc1, 1.13.0rc2, 1.13.1, 1.13.2, 1.14.0rc0, 1.14.0rc1, 1.14.0, 1.15.0rc0, 1.15.0rc1, 1.15.0rc2, 1.15.0rc3, 1.15.0, 1.15.2, 1.15.3, 1.15.4, 2.0.0a0, 2.0.0b0, 2.0.0b1, 2.0.0rc0, 2.0.0rc1, 2.0.0rc2, 2.0.0, 2.0.1, 2.0.2, 2.0.3, 2.1.0rc0, 2.1.0rc1, 2.1.0rc2, 2.1.0, 2.1.1, 2.1.2, 2.2.0rc0, 2.2.0rc1, 2.2.0rc2, 2.2.0rc3, 2.2.0rc4, 2.2.0, 2.2.1, 2.3.0rc0, 2.3.0rc1, 2.3.0rc2, 2.3.0, 2.3.1) ERROR: No matching distribution found for tensorflow== If Conda does not have a package in one of the mentioned channels such as 'conda-forge' or 'defaults', it raises the below exception: ResolvePackageNotFound: - tensorflow=1.15.4 ========== 8. Checking TensorFlow 1.X installation: (bert_env) CMD>conda list tensorflow # packages in environment at E:\programfiles\Anaconda3\envs\bert_env: # # Name Version Build Channel tensorflow 1.14.0 h1f41ff6_0 conda-forge tensorflow-base 1.14.0 py37hc8dfbb8_0 conda-forge tensorflow-estimator 1.14.0 py37h5ca1d4c_0 conda-forge (bert_env) CMD>python >>> import tensorflow as tf >>> print(tf.__version__) 2.3.0 >>> ~ ~ ~ ~ ~ (bert_env) CMD>pip freeze | find "tensorflow" tensorflow==2.3.0 tensorflow-estimator==2.3.0 (bert_env) CMD>pip freeze | findstr "tensorflow" tensorflow==2.3.0 tensorflow-estimator==2.3.0 (bert_env) CMD>python -c "import tensorflow as tf; print(tf.__version__)" 2.3.0 (bert_env) CMD>pip show tensorflow Name: tensorflow Version: 2.3.0 Summary: TensorFlow is an open source machine learning framework for everyone. Home-page: https://www.tensorflow.org/ Author: Google Inc. Author-email: packages@tensorflow.org License: Apache 2.0 Location: c:\users\aj\appdata\roaming\python\python37\site-packages Requires: wheel, astunparse, numpy, protobuf, wrapt, gast, six, tensorflow-estimator, scipy, grpcio, termcolor, tensorboard, opt-einsum, absl-py, keras-preprocessing, h5py, google-pasta Required-by: ==========
Tuesday, October 13, 2020
Flutter for Android Development (Notes, Oct 2020)
Follow these steps as part of setting up an old project on a new system. Such as in case of taking a project from Ubuntu machine to a Windows machine. 1.1 - Go to SDK Manager1.2 - Install the required Android SDK 2 - Build.grade changes - Removing unnecessary dependencies
2 - Build.grade changes - Removing unnecessary dependencies 3 - Changes in Gradle.properties to use AndroidX and Jetifier
3 - Changes in Gradle.properties to use AndroidX and Jetifier 4 - Flutter Commands To Begin With
4 - Flutter Commands To Begin With






Extracting Information From Search Engines
1. Google A Google Search URL looks like: https://www.google.com/search?q=nifty+50&start=0 In "nifty+50", "+" indicates [SPACE]. Pagination with 10 results per page, can be queried using 'start' parameter starting from 0. For first 10, start = 0 For second 10, start = 10 Notes: Google throws in a Captcha on sensing access through code or robots: Error: About this page Prove that you are not a robot by solving this Captcha... Our systems have detected unusual traffic from your computer network. This page checks to see if it's really you sending the requests, and not a robot. Why did this happen? IP address: 34.93.163.15 Time: 2020-10-09T09:23:07Z URL: https://www.google.com/search?q=VERB+RIK&start=0 Ref 1: Guide to the Google Search Parameters Ref 2: RapidAPI Google Search (Free usage allows 300 requests per month. '300 requests per month' means you better look for other free alternative.) 2. Bing A Bing Search URL looks like: https://www.bing.com/search?q=nifty+50&first=21 In "nifty+50", "+" indicates [SPACE]. Pagination with 10 results per page, can be queried using 'first' parameter starting from 1. For first 10, first = 1 For second 10, first = 11 Notes: 2.1. The search engine ranks home pages, not blogs. 2.2. Forums are often ranked low in the search results. 2.3. Sends back empty pages with no results on sensing access through code or robots. 2.4. RapidAPI offers an API for Bing Search but it has '1000 / month quota Hard Limit' on free usage and this means you better look for other free alternatives of RapidAPI. 3. Yahoo By Oct 2020, Yahoo has dropped to the third spot in terms of market share. Its web portal is still popular, and it is said to be the eleventh most visited site according to Alexa. Notes: 3.1. Unclear labeling of ads make it hard to distinguish between organic and non-organic results 3.2. Boasts other services such as Yahoo Finance, Yahoo mail, Yahoo answers, and several mobile apps. 3.3. Search URL for Yahoo can formed using its "p" argument as in this URL: https://in.search.yahoo.com/search?p=nifty50 3.4. RapidAPI is not available for Yahoo. 4. Contextual Web Search Contextual Web says on its Home-page: Search APIs & Custom Search: Easy to use search APIs. Search through billions of webpages with a simple API call and without breaking the bank. Get started in minutes. [ Ref: contextualweb.io ] 'Contextual Web Search' has URL: usearch The 'Contextual Web Search' are available via RapidAPI site. It is a paid service with a 'free and limited' version allowing '500 / day quota Hard Limit (After which usage will be restricted)'. Code for RapidAPI: import requests from time import time import datetime import os import json url = "https://contextualwebsearch-websearch-v1.p.rapidapi.com/api/Search/WebSearchAPI" querystring = { "pageNumber" : "1", "q" : "nifty50", "autoCorrect" : "false", "pageSize" : "100" } headers = { 'x-rapidapi-host': "contextualwebsearch-websearch-v1.p.rapidapi.com", 'x-rapidapi-key': "..." } response = requests.request("GET", url, headers=headers, params=querystring) with open(os.path.join("output", querystring['q'] + "_" + str(datetime.datetime.now()).replace(":", "_") + ".json"), mode = 'w', encoding = 'utf-8') as f: f.write(json.dumps(response.json(), indent=2, sort_keys=True)) The above code produces output in the form of a JSON file in a folder alongside this script named "output" (this should be created before running the script). References % RapidAPI's All API(s)

Friday, October 9, 2020
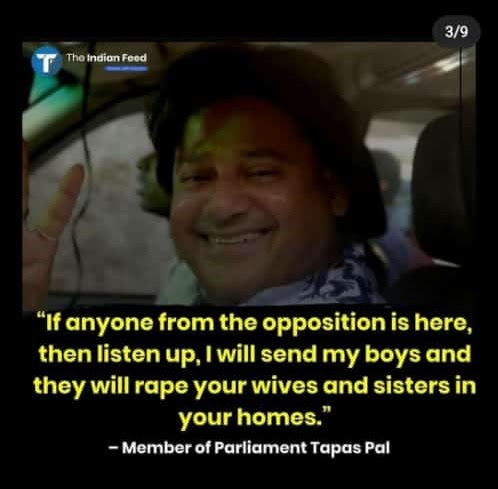
Indian Politicians Supporting Rapist Men
A collation of statements made by Indian politicians from time to time in support of rapists as Uttar Pradesh CM Yogi makes an anti-women comment following Hathras rape case in October, 2020.
















Subscribe to:
Comments (Atom)