Here, we focus on only one natural language, English and only one programming language, Python.The Way We Understand Language and How Machines See it is Quite Different
Natural languages have an additional “decoding” challenge (apart from the ‘Information Extraction’ from it) that is even harder to solve. Speakers and writers of natural languages assume that a human is the one doing the processing (listening or reading), not a machine. So when I say “good morning”, I assume that you have some knowledge about what makes up a morning, including not only that mornings come before noons and afternoons and evenings but also after midnights. And you need to know they can represent times of day as well as general experiences of a period of time. The interpreter is assumed to know that “good morning” is a common greeting that doesn’t contain much information at all about the morning. Rather it reflects the state of mind of the speaker and her readiness to speak with others. TIP: The “r” before the quote specifies a raw string, not a regular expression. With a Python raw string, you can send backslashes directly to the regular expression compiler without having to double-backslash ("\\") all the special regular expression characters such as spaces ("\\ ") and curly braces or handlebars("\\{ \\}").
TIP: The “r” before the quote specifies a raw string, not a regular expression. With a Python raw string, you can send backslashes directly to the regular expression compiler without having to double-backslash ("\\") all the special regular expression characters such as spaces ("\\ ") and curly braces or handlebars("\\{ \\}").

Architecture of a Chatbot
A chatbot requires four kinds of processing as well as a database to maintain a memory of past statements and responses. Each of the four processing stages can contain one or more processing algorithms working in parallel or in series (see figure 1.3): 1. Parse—Extract features, structured numerical data, from natural language text. 2. Analyze—Generate and combine features by scoring text for sentiment, grammaticality, and semantics. 3. Generate—Compose possible responses using templates, search, or language models. 4. Execute—Plan statements based on conversation history and objectives, and select the next response.


The Way Rasa Identifies a Greeting or Good-bye


How does Rasa understand your greetings?
An image taken from “rasa interactive” command output of our conversation.

IQ of some Natural Language Processing systems
We see that bots working at depth in this image are: Domain Specific Bots.
For the fundamental building blocks of NLP, there are equivalents in a computer language compiler
# tokenizer -- scanner, lexer, lexical analyzer # vocabulary -- lexicon # parser -- compiler # token, term, word, or n-gram -- token, symbol, or terminal symbolAn quick-and-dirty example of ‘Tokenizer’ using the str.split()
>>> import numpy as np >>> token_sequence = str.split(sentence) >>> vocab = sorted(set(token_sequence)) >>> ', '.join(vocab) '26., Jefferson, Monticello, Thomas, age, at, began, building, of, the' >>> num_tokens = len(token_sequence) >>> vocab_size = len(vocab) >>> onehot_vectors = np.zeros((num_tokens, ... vocab_size), int) >>> for i, word in enumerate(token_sequence): ... onehot_vectors[i, vocab.index(word)] = 1 >>> ' '.join(vocab) '26. Jefferson Monticello Thomas age at began building of the' >>> onehot_vectors

One-Hot Vectors and Memory Requirement
Let’s run through the math to give you an appreciation for just how big and unwieldy these “player piano paper rolls” are. In most cases, the vocabulary of tokens you’ll use in an NLP pipeline will be much more than 10,000 or 20,000 tokens. Sometimes it can be hundreds of thousands or even millions of tokens. Let’s assume you have a million tokens in your NLP pipeline vocabulary. And let’s say you have a meager 3,000 books with 3,500 sentences each and 15 words per sentence—reasonable averages for short books. That’s a whole lot of big tables (matrices): The example below is assuming that we have a million tokens (words in our vocabulary):
Document-Term Matrix
The One-Hot Vector Based Representation of Sentences in the previous slide is a concept very similar to “Document-Term” matrix.
For Tokenization: Use NLTK (Natural Language Toolkit)
You can use the NLTK function RegexpTokenizer to replicate your simple tokenizer example like this:An even better tokenizer is the Treebank Word Tokenizer from the NLTK package. It incorporates a variety of common rules for English word tokenization. For example, it separates phrase-terminating punctuation (?!.;,) from adjacent tokens and retains decimal numbers containing a period as a single token. In addition it contains rules for English contractions. For example “don’t” is tokenized as ["do", "n’t"]. This tokenization will help with subsequent steps in the NLP pipeline, such as stemming.

Stemming and lemmatization
For grammatical reasons, documents are going to use different forms of a word, such as organize, organizes, and organizing. Additionally, there are families of derivationally related words with similar meanings, such as democracy, democratic, and democratization. In many situations, it seems as if it would be useful for a search for one of these words to return documents that contain another word in the set. The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. For instance:The result of this mapping of text will be something like: However, the two words differ in their flavor. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun. The two may also differ in that stemming most commonly collapses derivationally related words, whereas lemmatization commonly only collapses the different inflectional forms of a lemma. Linguistic processing for stemming or lemmatization is often done by an additional plug-in component to the indexing process, and a number of such components exist, both commercial and open-source. Ref: nlp.stanford.edu
However, the two words differ in their flavor. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma. If confronted with the token saw, stemming might return just s, whereas lemmatization would attempt to return either see or saw depending on whether the use of the token was as a verb or a noun. The two may also differ in that stemming most commonly collapses derivationally related words, whereas lemmatization commonly only collapses the different inflectional forms of a lemma. Linguistic processing for stemming or lemmatization is often done by an additional plug-in component to the indexing process, and a number of such components exist, both commercial and open-source. Ref: nlp.stanford.edu
CONTRACTIONS
You might wonder why you would split the contraction wasn’t into was and n’t. For some applications, like grammar-based NLP models that use syntax trees, it’s important to separate the words was and not to allow the syntax tree parser to have a consistent, predictable set of tokens with known grammar rules as its input. There are a variety of standard and nonstandard ways to contract words. By reducing contractions to their constituent words, a dependency tree parser or syntax parser only need be programmed to anticipate the various spellings of individual words rather than all possible contractions.Tokenize informal text from social networks such as Twitter and Facebook
The NLTK library includes a tokenizer—casual_tokenize—that was built to deal with short, informal, emoticon-laced texts from social networks where grammar and spelling conventions vary widely. The casual_tokenize function allows you to strip usernames and reduce the number of repeated characters within a token: >>> from nltk.tokenize.casual import casual_tokenize >>> message = """RT @TJMonticello Best day everrrrrrr at Monticello.\ ... Awesommmmmmeeeeeeee day :*)""" >>> casual_tokenize(message) ['RT', '@TJMonticello’, 'Best', 'day','everrrrrrr', 'at', 'Monticello', '.’, 'Awesommmmmmeeeeeeee', 'day', ':*)’] >>> casual_tokenize(message, reduce_len=True, strip_handles=True) ['RT’, 'Best', 'day', 'everrr', 'at', 'Monticello', '.’, 'Awesommmeee', 'day', ':*)']n-gram tokenizer from nltk in action
You might be able to sense a problem here. Looking at your earlier example, you can imagine that the token “Thomas Jefferson” will occur across quite a few documents. However the 2-grams “of 26” or even “Jefferson began” will likely be extremely rare. If tokens or n-grams are extremely rare, they don’t carry any correlation with other words that you can use to help identify topics or themes that connect documents or classes of documents. So rare n-grams won’t be helpful for classification problems. You can imagine that most 2-grams are pretty rare—even more so for 3- and 4-grams.
Problem of rare n-grams
Because word combinations are rarer than individual words, your vocabulary size is exponentially approaching the number of n-grams in all the documents in your corpus. If your feature vector dimensionality exceeds the length of all your documents, your feature extraction step is counterproductive. It’ll be virtually impossible to avoid overfitting a machine learning model to your vectors; your vectors have more dimensions than there are documents in your corpus. In chapter 3, you’ll use document frequency statistics to identify n-grams so rare that they are not useful for machine learning. Typically, n-grams are filtered out that occur too infrequently (for example, in three or fewer different documents). This scenario is represented by the “rare token” filter in the coin-sorting machine of chapter 1.Problem of common n-grams
Now consider the opposite problem. Consider the 2-gram “at the” in the previous phrase. That’s probably not a rare combination of words. In fact it might be so common, spread among most of your documents, that it loses its utility for discriminating between the meanings of your documents. It has little predictive power. Just like words and other tokens, n-grams are usually filtered out if they occur too often. For example, if a token or n-gram occurs in more than 25% of all the documents in your corpus, you usually ignore it. This is equivalent to the “stop words” filter in the coin-sorting machine of chapter 1. These filters are as useful for n-grams as they are for individual tokens. In fact, they’re even more useful.
STOP WORDS
Stop words are common words in any language that occur with a high frequency but carry much less substantive information about the meaning of a phrase. Examples of some common stop words include: a, an the, this and, or of, on A more comprehensive list of stop words for various languages can be found in NLTK’s corpora ( stopwords.zip ). Historically, stop words have been excluded from NLP pipelines in order to reduce the computational effort to extract information from a text. Even though the words themselves carry little information, the stop words can provide important relational information as part of an n-gram. Consider these two examples: Mark reported to the CEO Suzanne reported as the CEO to the board Also, some stop words lists also contain the word ‘not’, which means “feeling cold” and “not feeling cold” would both be reduced to “feeling cold” by a stop words filter. Ref: stop words removal using nltk, spacy and gensimStop Words Removal
Designing a filter for stop words depends on your application. Vocabulary size will drive the computational complexity and memory requirements of all subsequent steps in the NLP pipeline. But stop words are only a small portion of your total vocabulary size. A typical stop word list has only 100 or so frequent and unimportant words listed in it. But a vocabulary size of 20,000 words would be required to keep track of 95% of the words seen in a large corpus of tweets, blog posts, and news articles.9 And that’s just for 1-grams or single-word tokens. A 2-gram vocabulary designed to catch 95% of the 2-grams in a large English corpus will generally have more than 1 million unique 2-gram tokens in it. You may be worried that vocabulary size drives the required size of any training set you must acquire to avoid overfitting to any particular word or combination of words. And you know that the size of your training set drives the amount of processing required to process it all. However, getting rid of 100 stop words out of 20,000 isn’t going to significantly speed up your work. And for a 2-gram vocabulary, the savings you’d achieve by removing stop words is minuscule. In addition, for 2-grams you lose a lot more information when you get rid of stop words arbitrarily, without checking for the frequency of the 2-grams that use those stop words in your text. For example, you might miss mentions of “The Shining” as a unique title and instead treat texts about that violent, disturbing movie the same as you treat documents that mention “Shining Light” or “shoe shining.” So if you have sufficient memory and processing bandwidth to run all the NLP steps in your pipeline on the larger vocabulary, you probably don’t want to worry about ignoring a few unimportant words here and there. And if you’re worried about overfitting a small training set with a large vocabulary, there are better ways to select your vocabulary or reduce your dimensionality than ignoring stop words. Including stop words in your vocabulary allows the document frequency filters (discussed in chapter 3) to more accurately identify and ignore the words and n-grams with the least information content within your particular domain.Stop Words in Code
>>> stop_words = ['a', 'an', 'the', 'on', 'of', 'off', 'this', 'is'] >>> tokens = ['the', 'house', 'is', 'on', 'fire'] >>> tokens_without_stopwords = [x for x in tokens if x not in stop_words] >>> print(tokens_without_stopwords) ['house', 'fire’]Stop Words From NLTK and Scikit-Learn
Code for “Stop Words From NLTK and Scikit-Learn”: >>> import nltk >>> nltk.download('stopwords') >>> stop_words = nltk.corpus.stopwords.words('english’) >>> len(stop_words) 179 >>> from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS as sklearn_stop_words >>> len(sklearn_stop_words) 318 >>> len(stop_words.union(sklearn_stop_words)) 378 >>> len(stop_words.intersection(sklearn_stop_words)) 119
Tuesday, July 20, 2021
Session 1 on ‘Understanding, Analyzing and Generating Text'






















Saturday, July 17, 2021
Improvements over OLS (Forward Stepwise, Ridge, Lasso and LARS forms of Regression)
1) When the targets are real numbers, the problem is called a “regression problem”. 2) “Linear regression” implies using a linear method to solve a “regression problem”.1. What Are Penalized Regression Methods?
Penalized linear regression is a derivative of ordinary least squares (OLS) regression— a method developed by Gauss and Legendre roughly 200 years ago. Penalized linear regression methods were designed to overcome some basic limitations of OLS regression. The basic problem with OLS is that sometimes it overfits the problem. Think of OLS as fitting a line through a group of points. This is a simple prediction problem: predicting y, the target value given a single attribute x. For example, the problem might be to predict men's salaries using only their heights. Height is slightly predictive of salaries for men (but not for women).Suppose that the data set had only two points in it. Imagine that there's a population of points, like the ones in Figure 1-1, but that you do not get to see all the points. Maybe they are too expensive to generate, like genetic data. There are enough humans available to isolate the gene that is the culprit; the problem is that you do not have gene sequences for many of them because of cost. To simulate this in the simple example, imagine that instead of six points you're given only two of the six points. How would that change the nature of the line fit to those points? It would depend on which two points you happened to get. To see how much effect that would have, pick any two points from Figure 1-1 and imagine a line through them. Figure 1-2 shows some of the possible lines through pairs of points from Figure 1-1. Notice how much the lines vary depending on the choice of points. The problem with having only two points to fit a line is that there is not enough data for the number of degrees of freedom. A line has two degrees of freedom. Having two degrees of freedom means that there are two independent parameters that uniquely determine a line. You can imagine grabbing hold of a line in the plane and sliding it up and down in the plane or twisting it to change its slope. So, vertical position and slope are independent. They can be changed separately, and together they completely specify a line. The degrees of freedom of a line can be expressed in several equivalent ways (where it intercepts the y‐axis and its slope, two points that are on the line, and so on). All of these representations of a line require two parameters to specify. When the number of degrees of freedom is equal to the number of points, the predictions are not very good. The lines hit the points used to draw them, but there is a lot of variation among lines drawn with different pairs of points. You cannot place much faith in a prediction that has as many degrees of freedom as the number of points in your data set. Solution: Penalized linear regression provides a way to systematically reduce degrees of freedom to match the amount of data available and the complexity of the underlying phenomena. These methods have become very popular for problems with very many degrees of freedom. They are a favorite for genetic problems where the number of degrees of freedom (that is, the number of genes) can be several tens of thousands and for problems like text classification where the number of degrees of freedom can be more than a million.
The problem with having only two points to fit a line is that there is not enough data for the number of degrees of freedom. A line has two degrees of freedom. Having two degrees of freedom means that there are two independent parameters that uniquely determine a line. You can imagine grabbing hold of a line in the plane and sliding it up and down in the plane or twisting it to change its slope. So, vertical position and slope are independent. They can be changed separately, and together they completely specify a line. The degrees of freedom of a line can be expressed in several equivalent ways (where it intercepts the y‐axis and its slope, two points that are on the line, and so on). All of these representations of a line require two parameters to specify. When the number of degrees of freedom is equal to the number of points, the predictions are not very good. The lines hit the points used to draw them, but there is a lot of variation among lines drawn with different pairs of points. You cannot place much faith in a prediction that has as many degrees of freedom as the number of points in your data set. Solution: Penalized linear regression provides a way to systematically reduce degrees of freedom to match the amount of data available and the complexity of the underlying phenomena. These methods have become very popular for problems with very many degrees of freedom. They are a favorite for genetic problems where the number of degrees of freedom (that is, the number of genes) can be several tens of thousands and for problems like text classification where the number of degrees of freedom can be more than a million.
2. What’s in a name?
Attributes and labels go by a variety of names, and new machine learners can get tripped up by the name switching from one author to another or even one paragraph to another from a single author. Attributes (the variables being used to make predictions) are also known as the following: ■ Predictors ■ Features ■ Independent variables ■ Inputs Labels are also known as the following: ■ Outcomes ■ Targets ■ Dependent variables ■ Responses3. Linear Regression in Mathematical Equations
Following is an m-by-n matrix.





4. Forward Stepwise Regression to Control Overfitting
# ‘Forward stepwise regression’ is an improvement over “best subset selection regression”. Initialize: ColumnList = NULL Out-of-sample-error = NULL Break X and Y into test and training sets For number of column in X: For each trialColumn (column not in ColumnList): Build submatrix of X using ColumnList + trialColumn Train OLS on submatrix and store RSS Error on test data ColumnList.append(trialColumn that minimizes RSS Error) Out-of-sample-error.append(minimum RSS Error) RSS: Residual sum of squares.
5. Control Overfitting by Penalizing Regression Coefficients—Ridge Regression
 The expression argmin means the “values of b0 and b that minimize the expression.” The resulting coefficients b0, b-star are the ordinary least squares solution. Best subset regression and forward stepwise regression throttle back ordinary regression by limiting the number of attributes used. That’s equivalent to imposing a constraint that some of the entries in the vector be equal to zero. Another approach is called coefficient penalized regression. Coefficient penalized regression accomplishes the same thing by making all the coefficients smaller instead of making some of them zero. One version of coefficient penalized linear regression is called ridge regression. Equation 3-15 shows the problem formulation for ridge regression.
The expression argmin means the “values of b0 and b that minimize the expression.” The resulting coefficients b0, b-star are the ordinary least squares solution. Best subset regression and forward stepwise regression throttle back ordinary regression by limiting the number of attributes used. That’s equivalent to imposing a constraint that some of the entries in the vector be equal to zero. Another approach is called coefficient penalized regression. Coefficient penalized regression accomplishes the same thing by making all the coefficients smaller instead of making some of them zero. One version of coefficient penalized linear regression is called ridge regression. Equation 3-15 shows the problem formulation for ridge regression.
 Ridge regression is available in scikit-learn.
Ridge regression is available in scikit-learn.
6. Why Penalized Linear Regression Methods Are So Useful
Several properties make penalized linear regression methods outstandingly useful, including the following: ■ Extremely fast model training ■ Variable importance information ■ Extremely fast evaluation when deployed ■ Reliable performance on a wide variety of problems—particularly on attribute matrices that are not very tall compared to their width or that are sparse. Sparse solutions (that is, a more parsimonious model) ■ May require linear model7. OLS and Lasso Regression in Using Equations





8. Forward Stepwise Regression Algorithm (for computing β)
■ Initialize all the β’s equal to zero. At each step ■ Find residuals (errors) after using variables already chosen. ■ Determine which unused variable best explains residuals and add it to the mix. ~ ~ ~ The LARS algorithm is very similar. The main difference with LARS is that instead of unreservedly incorporating each new attribute, it only partially incorporates them.9. Least Angle Regression Algorithm (for computing β)
■ Initialize all β’s to zero. At Each Step ■ Determine which attribute has the largest correlation with the residuals. ■ Increment that variable’s coefficient by a small amount if the correlation is positive or decrement by a small amount if negative.

10. Practice Question
Ques: Tickets are being raised in a software such as Service Now. You have some tickets already logged and marked as 'VDI' or 'Others'. Now, for any incoming ticket, predict if it is VDI related or not using Linear Regression. Ans. We would convert our target column (VDI (Yes/No)) into two columns VDI-Y and VDI-N using One-hot encoding. Value for VDI column: yes or no VDI-yes , VDI-no Y 1 0 N 0 1 Over here we know that VDI-Y can be infered as 1 if VDI-N is 0 and vice-versa. When you would run regression for one of these two columns as target columns, we would get a value between 0 and 1. For making prediction, we set a threshold, if my vdi-yes value is greater 0.5, I would assume it is a yes and predict that the incoming ticket in ServiceNow is about VDI. DO NOT USE REGRESSION ALGORITHMS FOR CLASSIFICATION PROBLEM.
















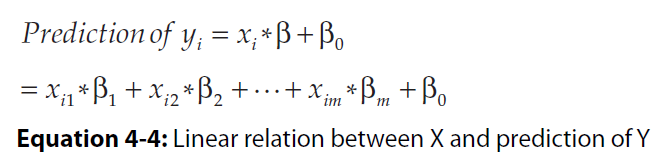



Wednesday, July 14, 2021
Linear Regression (Theory)
1. PREFACE TO LINEAR REGRESSION
Linear regression falls under a class of Machine Learning problems generally referred to as “function approximation”. Function approximation is a subset of problems that are called supervised learning problems. Linear regression also has a classifier cousin called logistic regression.2. Ordinary least squares (OLS) regression
Think of OLS as fitting a line through a group of points, as in Figure 1-1. This is a simple prediction problem: predicting y, the target value given a single attribute x. For example, the problem might be to predict men's salaries using only their heights. Height is slightly predictive of salaries for men (but not for women).
3. DEGREES OF FREEDOM
The points represent men's salaries versus their heights. The line in Figure 1-1 represents the OLS solution to this prediction problem. In some sense, the line is the best predictive model for men's salaries given their heights. The data set has six points in it. Suppose that the data set had only two points in it. Imagine that there's a population of points, like the ones in Figure 1-1, but that you do not get to see all the points. Maybe they are too expensive to generate. To simulate this in the simple example, imagine that instead of six points you're given only two of the six points. How would that change the nature of the line fit to those points? It would depend on which two points you happened to get. To see how much effect that would have, pick any two points from Figure 1-1 and imagine a line through them. Figure 1-2 shows some of the possible lines through pairs of points from Figure 1-1. Notice how much the lines vary depending on the choice of points.The problem with having only two points to fit a line is that there is not enough data for the number of degrees of freedom. A line has two degrees of freedom. Having two degrees of freedom means that there are two independent parameters that uniquely determine a line. You can imagine grabbing hold of a line in the plane and sliding it up and down in the plane or twisting it to change its slope. So, vertical position and slope are independent. They can be changed separately, and together they completely specify a line. The degrees of freedom of a line can be expressed in several equivalent ways (where it intercepts the y‐axis and its slope, two points that are on the line, and so on). All of these representations of a line require two parameters to specify. When the number of degrees of freedom is equal to the number of points, the predictions are not very good. The lines hit the points used to draw them, but there is a lot of variation among lines drawn with different pairs of points. You cannot place much faith in a prediction that has as many degrees of freedom as the number of points in your data set. The plot in Figure 1-1 had six points and fit a line (two degrees of freedom) through them. That is six points and two degrees of freedom.
4. REGRESSION:
Regression is the task of learning a target function ‘f’ that maps each attribute set x into a continuous-valued output y.5. ERROR FUNCTION:
Individual Error Term:Mapping errors on the graphThe goal of regression is to find a target function that can fit the input data with minimum error. The error function for a regression task can be expressed in terms of the sum of absolute or squared error:
 We are only showing d(E)/d(w0) here: Let “a” is equal to: yi – (w1).xi E = sum((a – w0)^2) E = sum(a^2 + (w0)^2 – 2(a)(w0)) d(E)/d(w0) = sum(0 + 2(w0) – 2a) RHS = sum(-2 . (a - w0)) Putting back the values of ‘a’: RHS = sum(-2 . (yi – (w1).xi – w0))
We are only showing d(E)/d(w0) here: Let “a” is equal to: yi – (w1).xi E = sum((a – w0)^2) E = sum(a^2 + (w0)^2 – 2(a)(w0)) d(E)/d(w0) = sum(0 + 2(w0) – 2a) RHS = sum(-2 . (a - w0)) Putting back the values of ‘a’: RHS = sum(-2 . (yi – (w1).xi – w0))



8. SCATTER PLOT FOR OUR DATA

9. SOLVING THE PROBLEM


10. LINER – CONDITIONS THAT SHOULD BE MET BY THE DATASET BEFORE WE USE LINEAR REGRESSION ON IT
Ref: Khan Academy11. LINER (From Transcript)
L: Linear The condition is that the actual relationship in the population between your x and y variables actually is a linear relationship. Now, in a lot of cases you might just have to assume that this is going to be the case when you see it on an exam, like an AP exam, for example. They might say, hey assume this condition is met. Oftentimes, it'll say assume of these conditions are met. They just want you to maybe know about these conditions. But this is something to think about. If the underlying relationship is nonlinear, well, then maybe some of your inferences might not be as robust. I: Independence Now, the next one is one we have seen before when we're talking about general conditions for inference, and this is the independence, independence condition And there's a couple of ways to think about it. Either individual observations are independent of each other. So you could be sampling with replacement. Or you could be thinking about your 10% rule. The size of our sample is no more than 10% of the size of the population. Similar to independence condition for proportions and for means. N: Normal Condition Arithmetic MeanStandard DeviationNormal DistributionNow, the next one is the normal condition. Although it means something a little bit more sophisticated when we're dealing with a regression. The normal condition, and, once again many times people just say assume it's been met. But let me actually draw a regression line, but do it with a little perspective, and I'm gonna add a third dimension. Let's say that's the x-axis, and let's say this is the y-axis. And the true population regression line looks like this. And so the normal condition tells us that for any given x in the true population, the distribution of y's that you would expect is normal, is normal So let me see if I can draw a normal distribution for the y's given that x. So that would be that normal distribution there. And then let's say for this x right over here, you would expect a normal distribution as well so just like, just like this. So if we're given x, the distribution of y's should be normal. Once again many times you'll just be told to assume that that has been met because it might, at least in an introductory statistics class be a little bit hard to figure this out on your own. E: Equal Variance And that's just saying that each of these normal distributions (for y) should have the same spread for a given x. And so you could say equal variance or you could even think about them having the equal standard deviation. So, for example, if, for a given x, let's say for this x, all of sudden you had a much lower variance, made it look like this, then you would no longer meet your conditions for inference. R: Random Condition This condition is that the data comes from a well-designed random sample or some type of randomized experiment And this condition we have seen in every type of condition for inference that we have looked at so far. So I'll leave you there. It's good to know It will show up on some exams. But many times, when it comes to problem solving, in an introductory statistics class, they will tell you, hey just assume the conditions for inference have been met. Or what are the conditions for inference? But they're not going to actually make you prove, for example the normal or the equal variance condition. That might be a bit much for an introductory statistics class.12. Practice Question
Ques 1: Can we solve this "y = (x^m)c" equation with linear regression? Ans 1: Equation of line: y = mx + c Log(y) = log((x^m)c) Log(y) = log(x^m) + log(c) Log(y) = m.log(x) + log(c) Y = log(y) X = log(x) C = log(c) Y = mX + C So answer is 'yes'. Ques 2: What does the term “Linear” mean in phrase “Linear Regression”? Ans 2: The model we are going to use is “Linear” in nature and we are assuming a linear relationship between dependent attributes and independent attributes. And, regression analysis is a set of statistical processes for estimating the relationships between a dependent variable and one or more real-valued independent variables. Ques 3: What is 'y-intercept'? Ans 3:















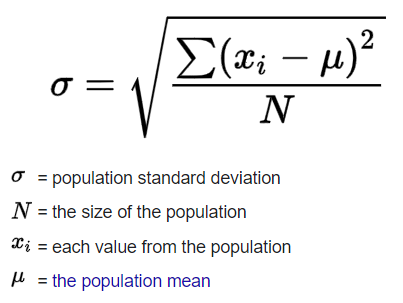


Alprax 0.25 (Alprazolam for Anxiety and Panic Disorder)
Alprax 0.25 Tablet Prescription: Required Manufacturer: Torrent Pharmaceuticals Ltd SALT COMPOSITION: Alprazolam (0.25mg) Storage: Store below 30°C Introduction Alprax 0.25 Tablet belongs to a class of medicines known as benzodiazepines. It is used to treat anxiety. It alters brain activity, calms it, and provides relief from panic attacks by relaxing the nerves. Alprax 0.25 Tablet may be taken with or without food. However, it is advised to take it at the same time each day as this helps to maintain a consistent level of medicine in the body. Take this medicine in the dose and duration as advised by your doctor as it has a high potential of habit-forming. If you have missed a dose, take it as soon as you remember it and finish the full course of treatment even if you feel better. This medication mustn't be stopped suddenly without talking to the doctor as it may cause nausea and anxiety. The most common side effect of this medicine is lightheadedness. It may cause dizziness and sleepiness, so do not drive or do anything that requires mental focus until you know how this medicine affects you. It may also cause weight gain or weight loss as it can vary from person to person. To prevent weight gain you can eat a healthy balanced diet, avoid snacking with high-calorie foods, and exercise regularly. Weight loss can be managed by increasing food portions and consulting a dietitian. If you have been taking this medicine for a long time then regular monitoring of blood and liver functions may be required. Uses of Alprax Tablet - Anxiety - Panic disorderBenefits of Alprax Tablet
In Anxiety Alprax 0.25 Tablet reduces the symptoms of excessive anxiety and worry. It can also reduce feelings of restlessness, tiredness, difficulty concentrating, and feeling irritable. It will therefore help you go about your daily activities more easily and be more productive. Keep taking this medicine even if you feel well. Stopping it suddenly can cause serious problems. So, do not stop taking it without discussing it with your doctor. In Panic disorder Alprax 0.25 Tablet can help relieve symptoms of many panic disorders including panic attacks. It can help you feel calmer and improve your ability to deal with problems. Do not stop taking it, even when you feel better unless your doctor advises you to. Side effects of Alprax Tablet Most side effects do not require any medical attention and disappear as your body adjusts to the medicine. Consult your doctor if they persist or if you’re worried about them. Common side effects of Alprax: 1. Lightheadedness 2. Drowsiness How Alprax Tablet works Alprax 0.25 Tablet is a benzodiazepine. It works by increasing the action of a chemical messenger (GABA) which suppresses the abnormal and excessive activity of the nerve cells in the brain. Quick tips 1. The addiction / habit-forming potential of this medicine is very high. Take it only as per the dose and duration advised by your doctor. 2. It may cause dizziness. Do not drive or do anything that requires mental focus until you know how this medicine affects you. 3. Avoid consuming alcohol as it may increase dizziness and drowsiness. 4. Inform your doctor if you are pregnant, planning to conceive or breastfeeding. 5. Do not stop taking medication suddenly without talking to your doctor as that may lead to nausea, anxiety, agitation, flu-like symptoms, sweating, tremor, and confusion. Fact Box Chemical Class: Benzodiazepines Derivative Habit Forming: Yes Therapeutic Class: NEURO CNS Action Class: Benzodiazepines
Subscribe to:
Comments (Atom)