Explore the fundamental concepts behind Delta Lake. Delta Lake is a robust storage solution designed specifically to work with Apache Spark. Organizations use Delta Lake to build a modern cloud data platform for supporting decision making. In this course, we explore the fundamental concepts behind Delta Lake. Learning objectives - Explain what Delta Lake is. - Summarize how Delta Lake helps organizations solve common challenges related to enterprise-scale data analytics. Prerequisites - Beginning knowledge of data processing concepts - Beginning knowledge of Apache Spark --- --- --- In this course, we explore the fundamental concepts behind Delta Lake. Delta Lake is a robust storage solution designed specifically to work with Apache Spark. Organizations use Delta Lake to build a modern cloud data platform for supporting decision making. Course goals By the end of this course, you will be able to describe what Delta Lake is and explain how Delta Lake helps organizations solve common challenges related to enterprise-scale data analytics. Who should take this course? Executives (CEO, CTO, CIO), directors of data engineering, platform architects, data engineers, data scientists, Spark programmers, data analysts, business intelligence analysts. Prerequisite knowledge required Familiarity with data processing concepts, familiarity with Apache Spark --- --- ---Lesson 1: A New Data Management Paradigm
Over the past few years at Databricks, we’ve seen a new data management paradigm that emerged independently across many customers and use cases: the cloud data platform. The evolution of data management
 Data Warehouses Data warehouses have a long history in decision support and business intelligence applications. Since its inception in the late 1980s, data warehouse technology continued to evolve. Massively parallel processing (MPP) architectures led to systems able to handle larger data sizes. While warehouses excel in handling structured data, most enterprises have to deal with unstructured, semi-structured, and data with high variety, velocity, and volume. Data warehouses are not suited for many of these use cases, and they are certainly not the most cost-efficient. Data Lakes As companies began to collect large amounts of data from many different sources, architects began envisioning a single system to house data for many different analytic products and workloads. About a decade ago companies began building data lakes – repositories for raw data in a variety of formats. While suitable for storing data, data lakes lack some critical features. Data lakes do not support ACID transactions, do not enforce data quality, and their lack of consistency/isolation makes it almost impossible to mix appends and reads, and batch and stream jobs. Diverse Data Applications Companies require systems for diverse data applications including: - SQL analytics - real-time monitoring - data science - machine learning and artificial intelligence Most of the recent advances in the modern data landscape have been building better models to process unstructured data (text, images, video, audio). These are precisely the types of data for which a data warehouse is sub-optimal. A Multitude of Systems A common approach to building these systems for diverse data applications is to use multiple systems: - a data lake - several data warehouses - streaming systems - time-series, graph, and image databases Having a multitude of systems introduces complexity, and more importantly, introduces delay as data professionals invariably need to move or copy data between different systems. What is a cloud data platform? Recent innovations in data system design make the cloud data platform design pattern possible. This design is to implement data warehouse data structures and data management features directly on the kind of low-cost storage used for data lakes. A data lakehouse is what you would get if you redesigned data warehouses in the modern world, now that cheap and highly reliable storage (in the form of object stores) are available. A data lakehouse has the following key features: - storage is decoupled from compute - open storage formats, tools, and processing engines - support for diverse data types ranging from unstructured to structured data - support for diverse workloads, including SQL and analytics, data science, and machine learning - transaction support - end-to-end streaming
Data Warehouses Data warehouses have a long history in decision support and business intelligence applications. Since its inception in the late 1980s, data warehouse technology continued to evolve. Massively parallel processing (MPP) architectures led to systems able to handle larger data sizes. While warehouses excel in handling structured data, most enterprises have to deal with unstructured, semi-structured, and data with high variety, velocity, and volume. Data warehouses are not suited for many of these use cases, and they are certainly not the most cost-efficient. Data Lakes As companies began to collect large amounts of data from many different sources, architects began envisioning a single system to house data for many different analytic products and workloads. About a decade ago companies began building data lakes – repositories for raw data in a variety of formats. While suitable for storing data, data lakes lack some critical features. Data lakes do not support ACID transactions, do not enforce data quality, and their lack of consistency/isolation makes it almost impossible to mix appends and reads, and batch and stream jobs. Diverse Data Applications Companies require systems for diverse data applications including: - SQL analytics - real-time monitoring - data science - machine learning and artificial intelligence Most of the recent advances in the modern data landscape have been building better models to process unstructured data (text, images, video, audio). These are precisely the types of data for which a data warehouse is sub-optimal. A Multitude of Systems A common approach to building these systems for diverse data applications is to use multiple systems: - a data lake - several data warehouses - streaming systems - time-series, graph, and image databases Having a multitude of systems introduces complexity, and more importantly, introduces delay as data professionals invariably need to move or copy data between different systems. What is a cloud data platform? Recent innovations in data system design make the cloud data platform design pattern possible. This design is to implement data warehouse data structures and data management features directly on the kind of low-cost storage used for data lakes. A data lakehouse is what you would get if you redesigned data warehouses in the modern world, now that cheap and highly reliable storage (in the form of object stores) are available. A data lakehouse has the following key features: - storage is decoupled from compute - open storage formats, tools, and processing engines - support for diverse data types ranging from unstructured to structured data - support for diverse workloads, including SQL and analytics, data science, and machine learning - transaction support - end-to-end streaming
Lesson 2: Delta Lake and Apache Spark
What is Delta Lake? Delta Lake is a technology for building robust data lakes and is a component of building your cloud data platform. Delta Lake is a storage solution specifically designed to work with Apache Spark and is read from and written to using Apache Spark. A data lake built using Delta Lake is ACID compliant, meaning that the data stored inside of the data lake has guaranteed consistency. Due to this guaranteed data consistency, Delta Lake is considered to be a robust data store, whereas a traditional data lake is not. Elements of Delta Lake Delta Lake is comprised of the following elements: Delta Table: A Delta table is a collection of data kept using the Delta Lake technology and consists of three things: 1. the Delta files containing the data and kept in object storage 2. a Delta table registered in the Metastore 3. the Delta Transaction Log kept with the Delta files in object storage Delta Files: Delta Lake, by design, uses Parquet files (sometimes referred to as Delta files) to store an organization’s data in their object storage. Parquet files are a state-of-the-art file format for keeping tabular data. They are faster and considered more powerful than traditional methods for storing tabular data because they store data using columns as opposed to rows. Delta files leverage all of the technical capabilities of working with Parquet files but also track data versioning and metadata, and store transaction logs to keep track of all commits made to a table or object storage directory to provide ACID transactions. ACID Properties of a Database Atomicity: Transactions are often composed of multiple statements. Atomicity guarantees that each transaction is treated as a single "unit", which either succeeds completely, or fails completely: if any of the statements constituting a transaction fails to complete, the entire transaction fails and the database is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors and crashes. A guarantee of atomicity prevents updates to the database occurring only partially, which can cause greater problems than rejecting the whole series outright. As a consequence, the transaction cannot be observed to be in progress by another database client. At one moment in time, it has not yet happened, and at the next it has already occurred in whole (or nothing happened if the transaction was cancelled in progress). An example of an atomic transaction is a monetary transfer from bank account A to account B. It consists of two operations, withdrawing the money from account A and saving it to account B. Performing these operations in an atomic transaction ensures that the database remains in a consistent state, that is, money is neither debited nor credited if either of those two operations fail. Consistency: Consistency ensures that a transaction can only bring the database from one valid state to another, maintaining database invariants: any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is correct. Referential integrity guarantees the primary key – foreign key relationship. Isolation: Transactions are often executed concurrently (e.g., multiple transactions reading and writing to a table at the same time). Isolation ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially. Isolation is the main goal of concurrency control; depending on the method used, the effects of an incomplete transaction might not even be visible to other transactions. Durability: Durability guarantees that once a transaction has been committed, it will remain committed even in the case of a system failure (e.g., power outage or crash). This usually means that completed transactions (or their effects) are recorded in non-volatile memory. ~ ~ ~ Delta optimization engine: Because Delta Lake is specifically designed to be used with Apache Spark, reads and writes made to Delta tables benefit from the inherent massively parallel processing capabilities of Apache Spark. When Apache Spark code is run to read and write to Delta Lake, the following optimizations are available: - File management optimizations including compaction, data skipping, and localized data storage - Auto optimized writes and file compaction - Performance optimization via Delta caching Delta Lake storage layer Building with Delta Lake, we store data using Delta Lake and then access the data via Apache Spark. With this pattern, organizations have a highly performant persistent storage layer built on low-cost, easily scalable object storage (Azure Data Lake Storage/ADLS, Amazon Web Services Simple Storage Service/S3). Keeping all of your data in files in object storage is the central design pattern that defines a data lake. Using the Delta Lake storage layer design pattern ensures consistency of data and allows the flexibility of working with a data lake. Delta architecture design pattern The Delta architecture design pattern consists of landing data in successively cleaner Delta Lake tables from raw (Bronze) to clean (Silver) to aggregate (Gold), as shown in the graphic below.Key Concepts: Delta Tables As discussed above, Delta tables consist of three things: 1. The Delta files containing the data and kept in object storage 2. A Delta table registered in the Metastore ( docs.databricks.com/metastores ) 3. The Delta Transaction Log kept with the Delta files in object storage ( Diving into delta lake unpacking the transaction log ) Delta files are kept in object storage. Note that this object storage is in the Customer's cloud rather than Databricks's cloud. Delta Transaction Log The Delta Lake transaction log (also known as the DeltaLog) is an ordered record of every transaction that has ever been performed on a Delta Lake table since its inception. It is written to object storage in the same location as the Delta files. A Delta table is registered in the Metastore associated with a Databricks Workspace. Metastore references include the location of Delta files in Object Storage, in addition to the schema and properties of the table. Spark SQL Queries End users write Spark SQL queries against the table registered in the Metastore. In other words, end users write simple queries against a Delta Table as if they were interacting with a standard SQL database. Key Concepts: Delta Lake Storage Layer As discussed above, the Delta Lake storage layer consists of two parts: 1. The Delta files containing the data, kept in object storage 2. a Delta table registered in the Metastore Key Concepts: Delta Architecture Throughout our Delta Lake discussions, we'll often refer to the concept of Bronze/Silver/Gold tables. These levels refer to the state of data refinement as data flows through a processing pipeline. These levels are conceptual guidelines, and implemented architectures may have any number of layers with various levels of enrichment. Below are some general ideas about the state of data in each level.
Key Concepts: Delta Lake Storage Layer As discussed above, the Delta Lake storage layer consists of two parts: 1. The Delta files containing the data, kept in object storage 2. a Delta table registered in the Metastore Key Concepts: Delta Architecture Throughout our Delta Lake discussions, we'll often refer to the concept of Bronze/Silver/Gold tables. These levels refer to the state of data refinement as data flows through a processing pipeline. These levels are conceptual guidelines, and implemented architectures may have any number of layers with various levels of enrichment. Below are some general ideas about the state of data in each level. Bronze Tables - Raw data (or very little processing) - Data will be stored in the Delta format (can encode raw bytes as a column) Silver Tables - Data that is directly queryable and ready for insights - Bad records have been handled, types have been enforced Gold Tables - Highly refined views of the data - Aggregate tables for BI - Feature tables for data scientists - For different workflows, things like schema enforcement and deduplication may happen in different places. The Power of Delta Lake The true power of Delta Lake emerges when it is combined with Apache Spark. Benefits of combining Delta Lake with Apache Spark include: COMPUTE / STORAGE SEPARATION: Separation of compute and storage A powerful paradigm in modern data storage and processing is the separation of compute and storage. Building systems with decoupled compute and storage has benefits associated with scalability, availability, and cost. In this system, Apache Spark loads and performs computation on the data. It does not handle permanent storage. Apache Spark works with Delta Lake, the first storage solution specifically designed to do so. RELIABLE DATA LAKE Highly performant and reliable lakehouse A data infrastructure built using Apache Spark and Delta Lake allows the construction of a highly performant and reliable data lake. The ACID properties of Delta Lake and the optimizations of the Delta read and write engine make Delta Lake built on cloud-based object storage the best-in-class solution.
Bronze Tables - Raw data (or very little processing) - Data will be stored in the Delta format (can encode raw bytes as a column) Silver Tables - Data that is directly queryable and ready for insights - Bad records have been handled, types have been enforced Gold Tables - Highly refined views of the data - Aggregate tables for BI - Feature tables for data scientists - For different workflows, things like schema enforcement and deduplication may happen in different places. The Power of Delta Lake The true power of Delta Lake emerges when it is combined with Apache Spark. Benefits of combining Delta Lake with Apache Spark include: COMPUTE / STORAGE SEPARATION: Separation of compute and storage A powerful paradigm in modern data storage and processing is the separation of compute and storage. Building systems with decoupled compute and storage has benefits associated with scalability, availability, and cost. In this system, Apache Spark loads and performs computation on the data. It does not handle permanent storage. Apache Spark works with Delta Lake, the first storage solution specifically designed to do so. RELIABLE DATA LAKE Highly performant and reliable lakehouse A data infrastructure built using Apache Spark and Delta Lake allows the construction of a highly performant and reliable data lake. The ACID properties of Delta Lake and the optimizations of the Delta read and write engine make Delta Lake built on cloud-based object storage the best-in-class solution. STRUCTURED STREAMING SUPPORT Support for Structured Streaming Delta Lake has native support for Structured Streaming via Apache Spark, allowing it to handle both batched and stream data sources. Data written to Delta Lake is immediately available for query. Support for immediate access to batch and stream data sources means that the Delta architecture design pattern replaces the complex Lambda architecture pattern. Building a data lake with Delta Lake at its core means that neither table repairs nor a complex lambda architecture are necessary.
STRUCTURED STREAMING SUPPORT Support for Structured Streaming Delta Lake has native support for Structured Streaming via Apache Spark, allowing it to handle both batched and stream data sources. Data written to Delta Lake is immediately available for query. Support for immediate access to batch and stream data sources means that the Delta architecture design pattern replaces the complex Lambda architecture pattern. Building a data lake with Delta Lake at its core means that neither table repairs nor a complex lambda architecture are necessary.
Lesson 3
A Single Source of Truth for Business Delta Lake as your single source of truth If using Delta Lake to build your data infrastructure, it is possible to make your data lake your single source of truth (SSOT) to support business decision making. In this lesson, we will review what a SSOT is, and how Delta Lake can act as your SSOT. What is a single source of truth? An SSOT is the single source of data that is used by everyone in an organization when mining data to make business decisions. This concept is important across organizations to ensure that business decisions are being made using the most accurate and up to date datasets. Without an SSOT, organizations can end up with multiple, conflicting copies of data, making it difficult to determine its validity and correctness. This SSOT is the heart of an organization's enterprise decision support system (EDSS). The Enterprise Decision Support System An enterprise decision support system, or EDSS, is an information system used by an organization to help decision-making. An EDSS might be built: - on-premises or in the cloud - leveraging data lake, data warehouse, or data lakehouse technology The mission of an EDSS is to publish an organization’s data assets to data analysts and other downstream consumers. As you can imagine, an EDSS is most effective if there is an SSOT for data. Having an SSOT means that data being published all come from the same, singular credible source. Analytical and Operational Layers An important concept in data system design is the distinction between the EDSS and the Operational Data Store (ODS). The EDSS and the ODS in a typical enterprise data system perform two distinct functions: - an EDSS performs Online Analytical Processing (OLAP) - an ODS performs Online Transaction Processing (OLTP) EDSS AND OLAP An EDSS is like a movie of an organization over its history. - An EDSS contains all available transactions performed during the history of a business, as well as all versions of information needed to perform those transactions. - Data associated with every transaction is available in the database. - If an order was modified, for example, all versions of that order are available in the database. - The image below shows an EDSS situated in the analytical layer of a data infrastructure. Once an ETL process loads data into the EDSS, data can then be consumed downstream.ODS AND OLTP: An ODS is like a photograph of an organization at any given moment. - An ODS contains data of all transactions (like sales or clicks) performed during business operations and all information needed to complete these transactions. - But an ODS only contains the latest version of a particular data point. - Data associated with every order received is available in the database. - If an order is modified, only the modified order is available. - The image below shows an ODS situated in the operational layer of a data infrastructure COMPLETE DATA SYSTEM In a complete data system, an ETL process pulls data from the ODS to be loaded into the EDSS.
COMPLETE DATA SYSTEM In a complete data system, an ETL process pulls data from the ODS to be loaded into the EDSS.

Lesson 4: Levels of Data in an Architected Data System
Levels of Data In this lesson, we will review the levels of data used to build an EDSS. This concept help in later lessons where we discuss EDSS Architectures and the Bronze, Silver, and Gold tables in the Delta Architecture. Operational - Operational data is stored in an ODS. - This data is the day-to-day data that an organization collects. - It is typically accessed frequently by the moment-to-moment operations of the organization e.g. via a website, mobile app, or even physical location. - Operational data is formatted to meet the needs of these operations. - The needs of analysts who may be looking at this data are secondary. Atomic - Atomic data is typically known as the storage layer. It is stored in an EDSS and is the single source of truth. - This data contains all values of any data attribute over time. - Atomic data is the most granular level of data. - It is fully integrated across all tables and data stores. - Atomic data is formatted according to a subject (customer, product, etc.), typically associated with the needs of a department and the analysts supporting that department. Departmental - Departmental data is a subset of atomic data and is typically stored in what is referred to as a data mart. - It is designed to meet the specific needs of a team, department, or use case. - Departmental data is kept in data marts, or smaller views of atomic data that are frequently updated downstream from the SSOT. - In some contexts, departmental data is known as the query layer. Individual - Individual data is ad-hoc and temporary. - It is often used to answer highly-specific questions such as how many customers bought a particular product over a specific time frame. - This data is the most refined and is nearly all aggregate in nature. - It is the type of data that could be generated by a SQL query or an interactive Apache Spark command run from a desktop tool or notebook. Levels of Data: Examples In the following section, you will see an example for each type of data that comes into an architectured data system. Operational data - An individual’s credit scoreSay for example that you are on a financial website and request your credit score. In order for the website to complete this request, the website’s ODS would be accessed to provide this information. A credit score is operational data because it provides a snapshot into an individual’s credit history. Atomic data - An individual’s credit history Now, say that the financial institution wishes to understand credit histories for all its customers. These credit histories are considered atomic data and are stored in an atomic database because they contains all transactions and records over time (they are time-variant). Departmental data - Monthly customer report Now, say, for example, that the finance team for a company wants a monthly report of new customers by month with a credit rating of A or higher. This is departmental data. It is a subset of all data. The finance team only wants to see customers with a credit rating of A or higher. The request meets a specific need.
Now, say that the financial institution wishes to understand credit histories for all its customers. These credit histories are considered atomic data and are stored in an atomic database because they contains all transactions and records over time (they are time-variant). Departmental data - Monthly customer report Now, say, for example, that the finance team for a company wants a monthly report of new customers by month with a credit rating of A or higher. This is departmental data. It is a subset of all data. The finance team only wants to see customers with a credit rating of A or higher. The request meets a specific need. Note: Since this is departmental data, this data would be housed in a data mart for rapid retrieval in decision-making by the finance team. Individual data - One-time data query Finally, let’s assume that a business analyst wants to know the number of customers living in California whose credit rating dropped from an A to a B in the last year. This information will be used by the company’s marketing department to prepare a targeted ad campaign.
Note: Since this is departmental data, this data would be housed in a data mart for rapid retrieval in decision-making by the finance team. Individual data - One-time data query Finally, let’s assume that a business analyst wants to know the number of customers living in California whose credit rating dropped from an A to a B in the last year. This information will be used by the company’s marketing department to prepare a targeted ad campaign. The business analyst would run an individual query in this case, because the marketing department needs this information for the current ad campaign (they do not need this information in the future, meaning that the analyst does not need to store the result). With what level would you associate each of these? Considering the levels of data, think about each of the following. With which level of data would each be associated? KAFKA: Kafka is stream-processing software and is typically associated with the operational layer. Kafka is often used to ensure that all operational transactions are properly ingested by the architected data system. MySQL: MySQL is an open-source database. While it is incredibly flexible and could be deployed at many places in an architected data system, it is most commonly associated with the operational layer. OBJECT STORAGE: Object Storage like Azure Data Lake Storage (ADLS) or AWS Simple Storage Service (S3) can be employed in many ways in the architected data environment. Using a Delta Architecture: - the atomic layer would be a Silver Delta table built using Object Storage - the departmental layer would be any number of Gold Delta tables also built on Object Storage DATA WAREHOUSE: A data warehouse (Teradata, Redshift, Snowflake) is most traditionally associated with the atomic layer. Using the Delta Architecture, it is possible and even advisable to use a Silver Delta table as the atomic layer, using a data warehouse as a serving layer for departmental and individual access. BUSINESS INTELLIGENCE GATHERING: The act of gathering and preparing business intelligence is commonly associated with the individual level, in particular because of the ad hoc nature of this work. BI and Data Analysts typically issue ad hoc queries against data stored at the departmental level.
The business analyst would run an individual query in this case, because the marketing department needs this information for the current ad campaign (they do not need this information in the future, meaning that the analyst does not need to store the result). With what level would you associate each of these? Considering the levels of data, think about each of the following. With which level of data would each be associated? KAFKA: Kafka is stream-processing software and is typically associated with the operational layer. Kafka is often used to ensure that all operational transactions are properly ingested by the architected data system. MySQL: MySQL is an open-source database. While it is incredibly flexible and could be deployed at many places in an architected data system, it is most commonly associated with the operational layer. OBJECT STORAGE: Object Storage like Azure Data Lake Storage (ADLS) or AWS Simple Storage Service (S3) can be employed in many ways in the architected data environment. Using a Delta Architecture: - the atomic layer would be a Silver Delta table built using Object Storage - the departmental layer would be any number of Gold Delta tables also built on Object Storage DATA WAREHOUSE: A data warehouse (Teradata, Redshift, Snowflake) is most traditionally associated with the atomic layer. Using the Delta Architecture, it is possible and even advisable to use a Silver Delta table as the atomic layer, using a data warehouse as a serving layer for departmental and individual access. BUSINESS INTELLIGENCE GATHERING: The act of gathering and preparing business intelligence is commonly associated with the individual level, in particular because of the ad hoc nature of this work. BI and Data Analysts typically issue ad hoc queries against data stored at the departmental level.
Lesson 5: Enterprise Decision Support System Architectures
Bill Inmon's Theoretical Data Warehouse Architecture Bill Inmon is considered by many to be the father of the data warehouse and the EDSS. Inmon developed a theoretical architecture for the EDSS including all four layers, from operational to individual: - An ETL process loads operational data into an EDSS (atomic data) - Another process loads atomic data into data marts at the departmental level - End users and other applications access departmental data at the individual level Reviewing EDSS Architectures In this lesson, we review the most common architecture patterns used for the modern EDSS. Delta Lake is the next-generation implementation of Bill Inmon’s vision and iterates on his and others’ work in data warehousing. INMON ARCHITECTURE The Inmon Architecture is a general design pattern for Enterprise Decision Support Sytems (EDSS).The on-premises data warehouse system The on-premises data warehouse (ODW) system was the original design pattern used in building an EDSS. CLOUD BASED The cloud-based data warehouse system Another approach to implementing an EDSS is the cloud-based data warehouse (CDW). This architecture often includes a low-cost raw layer as part of the ETL process.
CLOUD BASED The cloud-based data warehouse system Another approach to implementing an EDSS is the cloud-based data warehouse (CDW). This architecture often includes a low-cost raw layer as part of the ETL process. The Cloud Data Platform Another approach to implementing an EDSS is to designate a data lake built on cloud-based object storage as the single source of truth.
The Cloud Data Platform Another approach to implementing an EDSS is to designate a data lake built on cloud-based object storage as the single source of truth. The on-premises data warehouse system The on-premises data warehouse (ODW) system was the original design pattern used in building an EDSS.
The on-premises data warehouse system The on-premises data warehouse (ODW) system was the original design pattern used in building an EDSS.
 Benefits of on-premises data warehouses Highly-optimized - ODWs typically involve highly optimized and tuned hardware and software. - ODW system architecture tightly couples hardware and software. - This coupling provides for best-in-class concurrent query performance. Massively parallel processing systems – ODWs typically leverage massively parallel processing (MPP) systems which allow for extremely fast ODW reads and writes. - Well-established technology – ODWs are also tried and true and are supported by decades of research and development, ensuring their reliability. Challenges with on-premises data warehouses Not cloud-native – Since ODW's are not cloud-native, leveraging data for use anywhere other than within the ODW system requires potentially long-running queries or ETL processes. Not elastic – ODWs are not elastic. This means that resources cannot easily be scaled up or down to meet expanding or contracting workload demands. In an ODW, scaling up often requires months of expensive planning and development by an engineering team. Data duplication – Performance benefits often require data replication/duplication, which goes against the principle of having a single source of truth. High data gravity – Data gravity refers to how difficult it is to move data from a given location. Data kept in an ODW has high data gravity, meaning that it is difficult to move. Data is kept in closed, proprietary formats on physical media. If an organization is using an ODW managed by a vendor, their data is effectively locked in to that particular vendor. Structured data only – An ODW is, by nature, a structured data store, meaning that it can only ingest structured data. - An ODW does not provide the flexibility to take a NoSQL approach to data processing. - In recent years, a NoSQL (Not Only SQL) approach to data processing has been found to be reliable and valuable. Expense – An ODW is very expensive to build and maintain. Expenses accrue in several areas: - Initial hardware investment - Teams of engineers required for both scaling systems and ongoing management - Time lost due to required downtime for system upgrades - Costs of having a dedicated database administrator (DBA) required to oversee an ODW - ETL processes required for leveraging downstream applications like cloud-based analytics systems The Cloud-based data warehouse system Another approach to implementing an EDSS is the cloud-based data warehouse (CDW). This architecture often includes a low-cost raw layer as part of the ETL process. Such an approach provides an optimized cloud-native system for reading data stored in the cloud.
Benefits of on-premises data warehouses Highly-optimized - ODWs typically involve highly optimized and tuned hardware and software. - ODW system architecture tightly couples hardware and software. - This coupling provides for best-in-class concurrent query performance. Massively parallel processing systems – ODWs typically leverage massively parallel processing (MPP) systems which allow for extremely fast ODW reads and writes. - Well-established technology – ODWs are also tried and true and are supported by decades of research and development, ensuring their reliability. Challenges with on-premises data warehouses Not cloud-native – Since ODW's are not cloud-native, leveraging data for use anywhere other than within the ODW system requires potentially long-running queries or ETL processes. Not elastic – ODWs are not elastic. This means that resources cannot easily be scaled up or down to meet expanding or contracting workload demands. In an ODW, scaling up often requires months of expensive planning and development by an engineering team. Data duplication – Performance benefits often require data replication/duplication, which goes against the principle of having a single source of truth. High data gravity – Data gravity refers to how difficult it is to move data from a given location. Data kept in an ODW has high data gravity, meaning that it is difficult to move. Data is kept in closed, proprietary formats on physical media. If an organization is using an ODW managed by a vendor, their data is effectively locked in to that particular vendor. Structured data only – An ODW is, by nature, a structured data store, meaning that it can only ingest structured data. - An ODW does not provide the flexibility to take a NoSQL approach to data processing. - In recent years, a NoSQL (Not Only SQL) approach to data processing has been found to be reliable and valuable. Expense – An ODW is very expensive to build and maintain. Expenses accrue in several areas: - Initial hardware investment - Teams of engineers required for both scaling systems and ongoing management - Time lost due to required downtime for system upgrades - Costs of having a dedicated database administrator (DBA) required to oversee an ODW - ETL processes required for leveraging downstream applications like cloud-based analytics systems The Cloud-based data warehouse system Another approach to implementing an EDSS is the cloud-based data warehouse (CDW). This architecture often includes a low-cost raw layer as part of the ETL process. Such an approach provides an optimized cloud-native system for reading data stored in the cloud.
 Benefits of cloud-based data warehouses Separation of compute and storage – A CDW is typically built separating compute and storage. Compare this to the inelastic ODW. The separation of computation and storage makes it easier to allocate resources elastically. Elastic resource allocation – Cloud vendors allocate CDW resources elastically. - Elastic resource allocation means that resources can dynamically be scaled up or down to meet expanding or contracting workload demands. Optimized for query throughput – By design, CDWs handle a large volume of concurrent queries, meaning that many users can simultaneously query the system. - CDWs are very quick in reading data and returning results, excelling in low latency queries. Cloud-based backup of historical Data – Because data is stored in the data lake before being passed to the data warehouse, an historical record of the data exists in these raw initial files. No database administrator required – Typically, no database administrator is required to maintain a CDW because resource maintenance and allocation is handled by a cloud service provider. Challenges with cloud-based data warehouses Medium data gravity – One significant problem for organizations using a CDW is that data must be stored in a proprietary format within the cloud object storage belonging to the CDW provider. - Organizations are locked in and typically pay more per volume for this storage then they would pay storing the data in their cloud. CDW providers typically bill for storage at a premium. Although data is in the cloud, moving the data requires expensive ETL jobs to successfully transfer it from the CDW provider's cloud object storage to an organization's cloud storage, where it can be used in another analytic application (like Tableau or Databricks). Structured data only – A CDW is by nature a structured data store. It can only ingest structured data. - In recent years, a NoSQL (not only SQL) approach has been found to be reliable and valuable in terms of the flexibility it provides. A CDW cannot do this. Black-box processing of queries – CDWs typically offer little opportunity for optimizing data queries, often lacking the ability to index data or provide transparency into the query execution plan. Data Lake not queryable – Because data in the data lake only exists as raw data, it is not queryable. - In other words, the data housed in a CDW data lake would only be accessible by running an ETL process to load it into a data warehouse. Expense: A CDW is expensive to build and maintain. Expenses accrue in several areas: - ETL processes required for leveraging other cloud-based analytics systems - Storage in vendor object-stores The Cloud Data Platform Another approach to implementing an EDSS is to designate a data lake built on cloud-based object storage as the SSOT. This is unique from other data warehouse architectures, because the designated EDSS is the data lake, instead of a data warehouse. In subsequent lessons, we will explore this architecture as implemented with Delta Lake and why it is the best option for building an EDSS.
Benefits of cloud-based data warehouses Separation of compute and storage – A CDW is typically built separating compute and storage. Compare this to the inelastic ODW. The separation of computation and storage makes it easier to allocate resources elastically. Elastic resource allocation – Cloud vendors allocate CDW resources elastically. - Elastic resource allocation means that resources can dynamically be scaled up or down to meet expanding or contracting workload demands. Optimized for query throughput – By design, CDWs handle a large volume of concurrent queries, meaning that many users can simultaneously query the system. - CDWs are very quick in reading data and returning results, excelling in low latency queries. Cloud-based backup of historical Data – Because data is stored in the data lake before being passed to the data warehouse, an historical record of the data exists in these raw initial files. No database administrator required – Typically, no database administrator is required to maintain a CDW because resource maintenance and allocation is handled by a cloud service provider. Challenges with cloud-based data warehouses Medium data gravity – One significant problem for organizations using a CDW is that data must be stored in a proprietary format within the cloud object storage belonging to the CDW provider. - Organizations are locked in and typically pay more per volume for this storage then they would pay storing the data in their cloud. CDW providers typically bill for storage at a premium. Although data is in the cloud, moving the data requires expensive ETL jobs to successfully transfer it from the CDW provider's cloud object storage to an organization's cloud storage, where it can be used in another analytic application (like Tableau or Databricks). Structured data only – A CDW is by nature a structured data store. It can only ingest structured data. - In recent years, a NoSQL (not only SQL) approach has been found to be reliable and valuable in terms of the flexibility it provides. A CDW cannot do this. Black-box processing of queries – CDWs typically offer little opportunity for optimizing data queries, often lacking the ability to index data or provide transparency into the query execution plan. Data Lake not queryable – Because data in the data lake only exists as raw data, it is not queryable. - In other words, the data housed in a CDW data lake would only be accessible by running an ETL process to load it into a data warehouse. Expense: A CDW is expensive to build and maintain. Expenses accrue in several areas: - ETL processes required for leveraging other cloud-based analytics systems - Storage in vendor object-stores The Cloud Data Platform Another approach to implementing an EDSS is to designate a data lake built on cloud-based object storage as the SSOT. This is unique from other data warehouse architectures, because the designated EDSS is the data lake, instead of a data warehouse. In subsequent lessons, we will explore this architecture as implemented with Delta Lake and why it is the best option for building an EDSS.
 Benefits of the Cloud Data Platform Separation of compute and storage – A data lake is foundationally built by separating compute and storage. Compare this to the inelastic ODW. The separation of computation and storage makes it easier to allocate resources elastically. Infinite storage capacity – With the unlimited availability of cloud-based object storage, organizations do not need to worry about running out of space. Leverage best aspects of a data warehouse – Using a data warehouse as a query layer means that all of the advantages of a data warehouse can be leveraged for reads: - DBA-free resource allocation - High query throughput and concurrent reads Expense – A cloud data platform is the least expensive option for building an SSOT. Organizations pay for compute only when needed. Low data gravity – The SSOT is data in the data lake. - Cloud object stores can use any data format. Raw data can be kept in the format deemed best by the engineering team. - This arrangement has the lowest data gravity, meaning it is easiest to move from here to any other location or format. High data throughput – High data throughput refers to this architecture's ability to handle a much higher volume of data per unit time. - Apache Spark supports high data throughput by design. - Since the cloud data platform leverages Apache Spark for moving data, this architecture also supports high data throughput. No limitations on data structure – Using a data lake as the SSOT means that there are no limits to the kinds of data that can be ingested. - A data lake is a NoSQL system meaning that it can support structured as well as semi-structured and unstructured data. - There are many advantages to a NoSQL approach. For one, it can significantly reduce the resources organizations must spend to clean up data. Mix batch and stream workloads – Building a system with Apache Spark means that the system benefits from the Structured Streaming capabilities of Apache Spark. - This means that the system can work with both stream and batch data sources. Challenges with the Cloud Data Platform Not designed for high concurrency – While this architecture is designed for high data throughput, it is not designed for high concurrency. - A cloud data platform can be less efficient running many simultaneous queries. Poor interactive query experience – Issuing queries over a data lake can have a great deal of overhead for each query, as Apache Spark is designed for data throughput. In other words, Apache Spark handles large data loads well but can struggle to handle many concurrent queries. Querying batch and stream data requires lambda architecture – While Apache Spark makes it possible to query data in a Data Lake, a complex lambda architecture will be required to validate all of the data at read time to ensure that the most accurate state of data is queried. - Using Delta Lake to build your cloud data platform means that a lambda architecture is not required. Knowledge of the Spark environment required – At a minimum, support from data engineers who can configure the Spark runtime for the system is needed.
Benefits of the Cloud Data Platform Separation of compute and storage – A data lake is foundationally built by separating compute and storage. Compare this to the inelastic ODW. The separation of computation and storage makes it easier to allocate resources elastically. Infinite storage capacity – With the unlimited availability of cloud-based object storage, organizations do not need to worry about running out of space. Leverage best aspects of a data warehouse – Using a data warehouse as a query layer means that all of the advantages of a data warehouse can be leveraged for reads: - DBA-free resource allocation - High query throughput and concurrent reads Expense – A cloud data platform is the least expensive option for building an SSOT. Organizations pay for compute only when needed. Low data gravity – The SSOT is data in the data lake. - Cloud object stores can use any data format. Raw data can be kept in the format deemed best by the engineering team. - This arrangement has the lowest data gravity, meaning it is easiest to move from here to any other location or format. High data throughput – High data throughput refers to this architecture's ability to handle a much higher volume of data per unit time. - Apache Spark supports high data throughput by design. - Since the cloud data platform leverages Apache Spark for moving data, this architecture also supports high data throughput. No limitations on data structure – Using a data lake as the SSOT means that there are no limits to the kinds of data that can be ingested. - A data lake is a NoSQL system meaning that it can support structured as well as semi-structured and unstructured data. - There are many advantages to a NoSQL approach. For one, it can significantly reduce the resources organizations must spend to clean up data. Mix batch and stream workloads – Building a system with Apache Spark means that the system benefits from the Structured Streaming capabilities of Apache Spark. - This means that the system can work with both stream and batch data sources. Challenges with the Cloud Data Platform Not designed for high concurrency – While this architecture is designed for high data throughput, it is not designed for high concurrency. - A cloud data platform can be less efficient running many simultaneous queries. Poor interactive query experience – Issuing queries over a data lake can have a great deal of overhead for each query, as Apache Spark is designed for data throughput. In other words, Apache Spark handles large data loads well but can struggle to handle many concurrent queries. Querying batch and stream data requires lambda architecture – While Apache Spark makes it possible to query data in a Data Lake, a complex lambda architecture will be required to validate all of the data at read time to ensure that the most accurate state of data is queried. - Using Delta Lake to build your cloud data platform means that a lambda architecture is not required. Knowledge of the Spark environment required – At a minimum, support from data engineers who can configure the Spark runtime for the system is needed.
Lesson 6: Building a Cloud Data Platform with Delta Lake
Fundamentals of Delta Lake In the previous lesson we discussed some of the challenges inherent to the cloud data platform architecture. These challenges become most apparent when trying to build AI, analytic, or machine learning projects using data from an EDSS built with a cloud data platform architecture. It is possible to minimize these challenges by using Delta Lake to build a cloud data platform. In this lesson we will review fundamental concepts inherent to Delta Lake. We will also explore how Delta Lake enables organizations to avoid known challenges with data lakehouses to build powerful, next generation EDSSs. Common challenges faced when building a cloud data platform When building a traditional cloud data platform (not using Delta Lake), organizations typically face challenges related to reliability, performance, and engineering. Reliability challenges Reliability challenges can present themselves as: - Poor quality or corrupt data due to failed writes or schema mismatch issues - Inconsistent views when trying to read streaming data sources - Storage issues including data lock-in and storage idiosyncrasies inherent to different on-premises or cloud environments Performance challenges at scale Performance challenges can present themselves as: - A bottleneck in processing as readers struggle to deal with too many small or few massive files in a directory. Streaming compounds this problem. - A breakdown of the indexing of tables using partitioning. Partitioning breaks down if the wrong fields are picked for or when data has many dimensions or high cardinality columns. - A lack of caching can lead to low cloud storage throughput (cloud object storage is 20-50MB/s/core vs 300MB/s/core for local SSDs). Engineering challenges associated with Lambda architecture A lambda architecture, originally developed to enable the merging of batch and stream data sources, can require up to six times as many engineers to maintain as a delta architecture, for the same data pipeline. Delta Lake pillars Next, we will introduce the fundamental concepts behind Delta Lake and explain why building a cloud data platform with Delta Lake enables organizations to bypass these challenges. Delta Lake is built upon three pillars addressing reliability, performance, and engineering challenges: 1. Clean, quality data 2. Consistent views across batch and stream data workloads 3. Optimized and easy to adopt Pillar 1: Clean, Quality Data Delta Lake provides high quality and reliable data that is always ready for analytics through a range of features for ingesting, managing, and cleaning data. This pillar speaks to reliability challenges when building a cloud data platform. Under this pillar, Delta Lake has the following features: 1. "ACID transactions" ensure that only complete writes are committed. 2. "Schema enforcement" automatically handles schema variations to prevent insertion of bad records during ingestion. 3. "Time Travel", part of Delta Lake’s built-in data versioning, enables rollbacks, full historical audit trails, and reproducible machine learning experiments. 4. "Exactly once semantics" ensures that data are neither missed nor repeated erroneously. Pillar 2: Consistent Views Across Batch and Stream Data Workloads Delta Lake supports multiple simultaneous readers and writers for mixed batch and stream data. This pillar speaks to performance challenges when building a cloud data platform. Under this pillar, Delta Lake has the following features: 1. "Snapshot isolation" provides support for multiple simultaneous writers and readers. 2. "Mixed streaming and batch" data mean that a table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingestion, batch historic backfill, and interactive queries all just work out of the box. Pillar 3: Optimized and easy to adopt Delta Lake is easy to adopt, optimized for the cloud, and using Delta Lake avoids data lock-in. This pillar speaks to engineering challenges when building a cloud data platform. Under this pillar, Delta Lake has the following features: 1. "Scalable metadata handling" leverages Spark's distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease. 2. "Effective on-premises" means that Delta Lake works well with Hadoop Distributed File System (HDFS) on-premises. 3. "Compatibility with Spark APIs" means that Delta Lake is easy to adopt for Spark users. 4. As an "open-source format", Delta Lake eliminates data lock-in. Using Delta Lake, there is no requirement only to use Delta Lake. 5. "Local development" means that Delta Lake supports laptop-based development and testing. 6. "In-place import" allows efficient, fast-import from Parquet to Delta format. Exploring the Delta Architecture Beyond these core features, using Delta Lake to build a cloud data platform also allows the use of Delta architecture. Let’s explore this architecture and its advantages when building an EDSS.Delta Architecture With the Delta architecture, multiple tables of data are kept in the same data lake. We write batch and stream data to the same table. Data is written to a series of progressively cleaner and more refined tables. Raw data ingested into a bronze data lake table
With the Delta architecture, multiple tables of data are kept in the same data lake. We write batch and stream data to the same table. Data is written to a series of progressively cleaner and more refined tables. Raw data ingested into a bronze data lake table This image depicts the first step in Delta architecture, where a data lake ingests raw data. This data can come from stream or batch data sources and is stored in inexpensive commodity object storage, as shown by the bronze table in the image. The data in this table often has long retention (years) and can be saved "as-is," avoiding error-prone parsing at this stage. A silver data lake table designated as the SSOT
This image depicts the first step in Delta architecture, where a data lake ingests raw data. This data can come from stream or batch data sources and is stored in inexpensive commodity object storage, as shown by the bronze table in the image. The data in this table often has long retention (years) and can be saved "as-is," avoiding error-prone parsing at this stage. A silver data lake table designated as the SSOT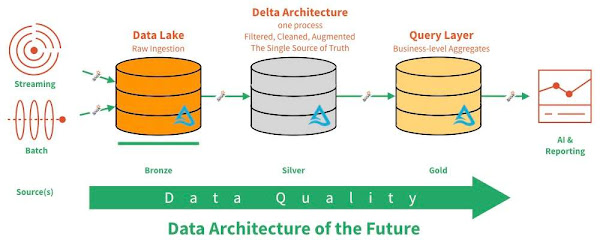 This image depicts the second step in Delta architecture, where the silver data lake is designed as the SSOT. Data in the silver table is clean and therefore easily queryable. Because the table is easy to query, debugging is much easier. The query layer or gold table
This image depicts the second step in Delta architecture, where the silver data lake is designed as the SSOT. Data in the silver table is clean and therefore easily queryable. Because the table is easy to query, debugging is much easier. The query layer or gold table This is the third step in Delta architecture, where cleaned aggregated data is available in a gold table, also known as a query layer. This data is ready for consumption via Apache Spark. A Complete Architecture That Fully Supports Batch and Stream Data Processing Delta architecture is a complete architecture that fully supports batch and stream data processing. In this image, we can see data streams moving through a data pipeline. These streams have low latency or are manually triggered, which eliminates the need for schedules or jobs. In addition, this architecture supports methods not historically supported by an ODW or CDW such as DELETE, MERGE, UPDATE, and Upserts, useful for GDPR or CCPA compliance.
This is the third step in Delta architecture, where cleaned aggregated data is available in a gold table, also known as a query layer. This data is ready for consumption via Apache Spark. A Complete Architecture That Fully Supports Batch and Stream Data Processing Delta architecture is a complete architecture that fully supports batch and stream data processing. In this image, we can see data streams moving through a data pipeline. These streams have low latency or are manually triggered, which eliminates the need for schedules or jobs. In addition, this architecture supports methods not historically supported by an ODW or CDW such as DELETE, MERGE, UPDATE, and Upserts, useful for GDPR or CCPA compliance.
Friday, November 27, 2020
Fundamentals of Delta Lake (Databricks)





























Tuesday, November 24, 2020
Basics of Workplace Stress Management

 Lazarus (building on Dr. Selye's work) suggested that there is a difference between eustress (term for positive stress), and distress (word for negative stress). In daily life, we often use the term 'stress' to describe negative situations. Nervous Breakdown
Lazarus (building on Dr. Selye's work) suggested that there is a difference between eustress (term for positive stress), and distress (word for negative stress). In daily life, we often use the term 'stress' to describe negative situations. Nervous Breakdown
 Stress cannot be avoided. It is natural response to certain situations.
Stress cannot be avoided. It is natural response to certain situations.
 Question for everyone: Do you know your breakdown point (it differs from person to person) when you transition from eustress to distress? Question: What are first signs of stress? Answer: Sign 1: If you feel you are losing the ability to think. Sign 2: Frequent headaches, body pain. Health deteriorates. Sign 3: People start to ask around you: "Are you doing alright?" "How is life?" ~ ~ ~ To counter stress... - Take a break. - Identify three things that you can do to energize yourself. Note about extroverts and introverts, and their preferences in activities to counter stress: Extrovert might do the talking. They generate energy from outside. Introvert might do meditation. They generate energy from within. People might choose different options to de-stress.
Question for everyone: Do you know your breakdown point (it differs from person to person) when you transition from eustress to distress? Question: What are first signs of stress? Answer: Sign 1: If you feel you are losing the ability to think. Sign 2: Frequent headaches, body pain. Health deteriorates. Sign 3: People start to ask around you: "Are you doing alright?" "How is life?" ~ ~ ~ To counter stress... - Take a break. - Identify three things that you can do to energize yourself. Note about extroverts and introverts, and their preferences in activities to counter stress: Extrovert might do the talking. They generate energy from outside. Introvert might do meditation. They generate energy from within. People might choose different options to de-stress. Note: Prefrontal cortex is responsible for 'being in the now', responsible for desicion making. Cognitive impact: % Difficulty in focusing. % Difficulty in problem solving. Emotional impact: % Sadness % Anger % Fear % Annoyed % Disappointment
Note: Prefrontal cortex is responsible for 'being in the now', responsible for desicion making. Cognitive impact: % Difficulty in focusing. % Difficulty in problem solving. Emotional impact: % Sadness % Anger % Fear % Annoyed % Disappointment STRESS AND ITS CAUSES
STRESS AND ITS CAUSES Internal negative monologue is an example of internal stressor. CIRCLES OF CONTROL, INFLUENCE, CONCERN
Internal negative monologue is an example of internal stressor. CIRCLES OF CONTROL, INFLUENCE, CONCERN 'Circle of control' is not shown here but it will be an even smaller circle than circle of influence. Circle of influence: All of those variable on which you have a direct influence. Circle of concern: Variable that you have concern about but no control or influence. COC and COI concept originated in the 'Behavioral Science'. WORKPLACE STRESSORS
'Circle of control' is not shown here but it will be an even smaller circle than circle of influence. Circle of influence: All of those variable on which you have a direct influence. Circle of concern: Variable that you have concern about but no control or influence. COC and COI concept originated in the 'Behavioral Science'. WORKPLACE STRESSORS 'Personal Difficulties' and 'Personal Challenges' is another dimension not mentioned in this list. 'Personal Challenges' might be like having a kid who cannot be on his own and needs attention. Or could be an elderly parent. Stresful situation created in personal life that spans into our professional life. There could be relationship strifes. Note: Domestic violence could be a challenge in personal life, the impact of which could have far reaching impact on the person. A study found that cases of domestic violence have shot up by over 30% during pandemic and lockdown in the months starting from April 2020. YOUR INNER TRAPS
'Personal Difficulties' and 'Personal Challenges' is another dimension not mentioned in this list. 'Personal Challenges' might be like having a kid who cannot be on his own and needs attention. Or could be an elderly parent. Stresful situation created in personal life that spans into our professional life. There could be relationship strifes. Note: Domestic violence could be a challenge in personal life, the impact of which could have far reaching impact on the person. A study found that cases of domestic violence have shot up by over 30% during pandemic and lockdown in the months starting from April 2020. YOUR INNER TRAPS CASE STUDY: IDENTIFY INNER TRAPS FOR THIS PERSON
CASE STUDY: IDENTIFY INNER TRAPS FOR THIS PERSON
 HANDLING YOUR INNER TRAPS
HANDLING YOUR INNER TRAPS 3 STAGES OF CALMING DOWN
3 STAGES OF CALMING DOWN Note: Prefrontal Cortex is responsible for critical thinking. Amygdala is the place where emotional thinking happens. Your prefrontal cortex should not let in the state of 'Amygdala Hijack' or the 'Emotional Hijack'.
Note: Prefrontal Cortex is responsible for critical thinking. Amygdala is the place where emotional thinking happens. Your prefrontal cortex should not let in the state of 'Amygdala Hijack' or the 'Emotional Hijack'. Now answer this question: "I effectively use each healthy living practice:" 1: To a great extent 2: To a moderate extent 3: To a minimal extent 4: Not at all Note: You can use a day planner journal to gather your thoughts for the day at its start. Or you can also write a "Gratitude List in a Journal" at the end of the day. Budddha's First Arrow and Second Arrow The Buddha once asked a student, “If a person is struck by an arrow, is it painful?” The student replied , “It is.” The Buddha then asked, “If the person is struck by a second arrow, is that even more painful?” The student replied again, “It is.” The Buddha then explained, “In life, we cannot always control the first arrow. However, the second arrow is our reaction to the first. And with this second arrow comes the possibility of choice.” The first arrow is our human conditioning to cling to comfort and pleasure and to react with anger or fear to unpleasant experience. It’s humbling to discover that willpower is often no match for these primal energies. We believe we should be able to control our “negative” emotions, then they just storm in and possess our psyches. We think we should be able to stop our obsessive thoughts or compulsive behaviors, but the anxious rehearsing, the cravings for food or attention, hound us throughout the day. The second, more painful arrow is our reaction to these “failures.” Sometimes our self-aversion is subtle; we’re not aware of how it undermines us. Yet often it is not— we hate ourselves for the way we get insecure and flustered, for being fatigued and unproductive, for our addiction to alcohol or other substances. Rather than attending to the difficult (and sometimes trauma-based) emotions underlying the first arrow, we shoot ourselves with the second arrow of self-blame. Awakening self-compassion is often the greatest challenge people face... First arrow was not in our control. How we respond to the second arrow is based on our learning from first arrow. Final Note: The greatest weapon against stress is our ability to choose one thought over another.
Now answer this question: "I effectively use each healthy living practice:" 1: To a great extent 2: To a moderate extent 3: To a minimal extent 4: Not at all Note: You can use a day planner journal to gather your thoughts for the day at its start. Or you can also write a "Gratitude List in a Journal" at the end of the day. Budddha's First Arrow and Second Arrow The Buddha once asked a student, “If a person is struck by an arrow, is it painful?” The student replied , “It is.” The Buddha then asked, “If the person is struck by a second arrow, is that even more painful?” The student replied again, “It is.” The Buddha then explained, “In life, we cannot always control the first arrow. However, the second arrow is our reaction to the first. And with this second arrow comes the possibility of choice.” The first arrow is our human conditioning to cling to comfort and pleasure and to react with anger or fear to unpleasant experience. It’s humbling to discover that willpower is often no match for these primal energies. We believe we should be able to control our “negative” emotions, then they just storm in and possess our psyches. We think we should be able to stop our obsessive thoughts or compulsive behaviors, but the anxious rehearsing, the cravings for food or attention, hound us throughout the day. The second, more painful arrow is our reaction to these “failures.” Sometimes our self-aversion is subtle; we’re not aware of how it undermines us. Yet often it is not— we hate ourselves for the way we get insecure and flustered, for being fatigued and unproductive, for our addiction to alcohol or other substances. Rather than attending to the difficult (and sometimes trauma-based) emotions underlying the first arrow, we shoot ourselves with the second arrow of self-blame. Awakening self-compassion is often the greatest challenge people face... First arrow was not in our control. How we respond to the second arrow is based on our learning from first arrow. Final Note: The greatest weapon against stress is our ability to choose one thought over another.



















Wednesday, November 18, 2020
Introduction to Unified Data Analytics with Databricks
This course is for individuals who want a high-level overview of how Databricks can help organizations adopt a Unified Data Analytics approach. By the end of the course you will be able to: 1: Summarize the benefits of adopting a Unified Data Analytics approach to business. 2: Explain, at a high-level, how Databricks enables organizations to adopt a Unified Data Analytics approach to business. 3: Explain how the individual components of the Unified Data Analytics Platform help organizations increase efficiency. 4: Give examples of how real-world customers have used Databricks to streamline big data workflows.Lesson 1: Why Unified Data Analytics?
In the early days of data analytics, simple relational databases, historical data, and spreadsheet expertise were used to drive business decisions. Today, with the emergence of big data, these methods are no longer sufficient. Businesses today spend a significant amount of resources trying to piece together solutions for how to extract insights from big data. You might be asking yourself, “Why is extracting insights from big data so complicated”? In the video below, we’ll review the challenges that many organizations face as they try to work with their big data. These concepts are important, as they are what set the stage for the emergence of Unified Data Analytics. Big Data is complex to work with because of 3Vs: Volume, Velocity and Variety


Lesson 2: What is Unified Data Analytics?
As we explored in our last lesson, working with big data is complicated. UDA arose to help data practitioners spend more time analyzing and extracting insights from data rather than figuring out how to store it, manage it, and more. In this lesson, we’ll review the basic elements behind a UDA approach to business. The concept behind a UDA approach sounds pretty straight-forward, right? At a high-level, it is. In summary, a UDA approach simply means that an organization is able to collect and process big data, store that data over a long period of time, and have that data at their disposal whenever they need it for a variety of business purposes. In our next lesson, we’ll apply this idea to a real-world scenario so that you can see what a UDA approach might look like in real-life.
The concept behind a UDA approach sounds pretty straight-forward, right? At a high-level, it is. In summary, a UDA approach simply means that an organization is able to collect and process big data, store that data over a long period of time, and have that data at their disposal whenever they need it for a variety of business purposes. In our next lesson, we’ll apply this idea to a real-world scenario so that you can see what a UDA approach might look like in real-life.
Lesson 3: Applying a Unified Data Analytics approach
In our previous lesson, we introduced the conceptual idea behind a UDA approach to business. In this lesson, we’ll take this conceptual idea and apply it to help illustrate what a UDA approach might look like in a real-world organization.

 Did you come up with any examples we didn't include in the video? If you did, nice work! A little later in the course, you'll hear from Databricks customers about how they've applied a UDA approach in their businesses - businesses you are probably familiar with. Next, we'll explore how Databricks helps organizations adopt this type of approach to work with their big data. Before we continue to our next lesson, you'll have the chance to take a quick quiz about what you've learned so far.
Did you come up with any examples we didn't include in the video? If you did, nice work! A little later in the course, you'll hear from Databricks customers about how they've applied a UDA approach in their businesses - businesses you are probably familiar with. Next, we'll explore how Databricks helps organizations adopt this type of approach to work with their big data. Before we continue to our next lesson, you'll have the chance to take a quick quiz about what you've learned so far.
Lesson 4: Test



Lesson 5: A brief introduction to Databricks
In the previous lesson, you learned all about UDA - why it is gaining popularity, what it entails, and what it might look like, at a high-level, in a real-world organization. At this point in our course, we’ll pivot to talk about Databricks, which was created to help organizations set up their big data infrastructure using a UDA approach.

Collaborative Data Science Workspace
In this lesson, we’ll review high-level functionality behind the Collaborative Data Science Workspace (Workspace). Workspace functionality The Workspace is the physical location where everyone on your data science team works together, from data ingest to production. Depending on the role of the data practitioner, they’ll use different functionality within the workspace, but they will still be in the same workspace and will have the ability to collaborate with each other. Each Workspace is connected to an organization’s data store, which can (currently) either be in AWS or Azure. This data store serves as their single source of truth, meaning that individuals working in the Workspace can all access and work with the same data. There are three major components of the Data Science Workspace including collaborative notebooks, Managed MLFlow, and the Runtime for Machine Learning. We'll review each of these now.

Lesson 6: Unified Data Service
In this lesson, we'll review the components of the Unified Data Service including the Databricks Runtime, Delta Lake, and Databricks Ingest.Databricks Runtime: 1. Optimized version of Spark 2. Runs on auto-scaling infrastructure Delta Lake: 1. Adds intelligence to a data lake 2. Benefits include: - Data reliability - Easier data management - Connections to visualization tools Databricks Ingest How does the Unified Data Service tie back into a Unified Data Analytics approach? First, as already mentioned, the Unified Data Service powers all of the data workflows being conducted by data practitioners as they work with data, from ingest to production. In addition, the Unified Data Service includes features like Delta Lake and Auto Ingest which enable data practitioners to easily store and manage data as business requirements change. The data processed and managed by Unified Data Service are what are used in periodic reporting, real-time dashboards, and artificial intelligence workflows. In our next lesson, we’ll review the final component of the Unified Data Analytics Platform-- the Enterprise Cloud Service.
How does the Unified Data Service tie back into a Unified Data Analytics approach? First, as already mentioned, the Unified Data Service powers all of the data workflows being conducted by data practitioners as they work with data, from ingest to production. In addition, the Unified Data Service includes features like Delta Lake and Auto Ingest which enable data practitioners to easily store and manage data as business requirements change. The data processed and managed by Unified Data Service are what are used in periodic reporting, real-time dashboards, and artificial intelligence workflows. In our next lesson, we’ll review the final component of the Unified Data Analytics Platform-- the Enterprise Cloud Service.
Lesson 7: Enterprise Cloud Service
Characterstics of the Enterprise Cloud Service: Security Features: - Retain control over your data - Private, isolated, compliant workspaces - Use corporate directories (such as Okta) to help establish data access - Single sign-on - Meet compliance standards (like GDPR (General Data Protection Regulation) and HIPAA (HIPAA is a US regulation that stands for Health Insurance Portability and Accountability Act.)) Simple Administration: - Automatically onboard and offboard users - Audit and analyze user activity - Enforce policy configurations - Set alerts Production-ready Infrastructure: - Ready-to-use environments - APIs to automate version control - On-demand auto-scaling infrastructure How does the Enterprise Cloud Service tie back into a Unified Data Analytics approach? It protects all of the work being done with your data - from ingestion to storage to performing analytics and generating real-time dashboards and periodic reports.Lesson 8: Knowledge Check
























Subscribe to:
Posts (Atom)