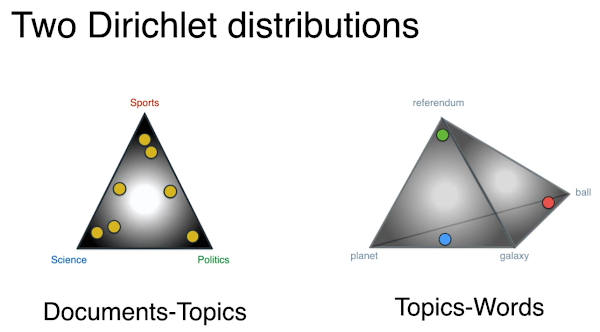
Here is the problem: We have a collection or corpus of documents and you can think of them as news articles if you would like. Each news article has a topic. Some of them are science, some are politics or sports. Some of them are allowed to have two topics. A article may have multiple topics: science and politics, or sports and science. But the problem is we don't know the topics to begin with. We only know the text of the articles. We would like to have an algorithm that will help us sort these documents into topics. So here is a small example. Let's say our collection of documents has these four documents and each document has only five words. Vocabulary of words is: ball, referendum, planet and galaxy. Doc 1: ball ball ball planet galaxy Doc 2: referendum planet planet referendum referendum Doc 3: planet planet galaxy planet ball Doc 4: planet galaxy referendum planet ball And, we have three possibilities for topics: Science, Politics and Sports. Let me show you what I did.But I want you to ask youselves this: We are able to understand words and topics and hence able to do it. We know what words mean, but the computer doesn't. Computer only knows if two words are different or two words appear in a document or not. LATENT DIRICHLET ALLOCATION The Problem: We have a collection of documents or news articles and we want to sort them into topics. This is where LDA comes into picture. What LDA does is: it takes a geometric approach. If you have 3 topics, then it builds a triangle. Corners represent the topics. Then it puts the documents inside the triangle. The documents are close to the corner if they belong to the topic representing that corner. Question is: How do we put the documents in the triangle in a perfect way. I like to think of LDA as a machine that generates articles. This machine has some settings to play with and it also has a button. When we push the button, the machine starts and it's two gears start spinning and generate a document. Most likely, the document you would produce would be gibberish. It is just a bunch of words put together. With some very, very, very low probability, you could get a Shakespeare novel or declaration of indepedence. Let's say we have two machines and they both output two documents. We compare those two documents with the original document. The document that matches better with the original document, the one that matches better was from a machine with better settings. We do this activity to figure out the best setting that is most likely to give us our document. Those settings will give us the topics.
BLUEPRINT OF THE LDA


LET US LOOK AT THE EQUATION
On the left we have the probability of getting back the original article:


DIRICHLET DISTRIBUTIONS



























Thursday, June 23, 2022
Latent Dirichlet Allocation (Algorithm for Topic Modeling of Text Data)


































Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment