Word2Vec
In 2012, Thomas Mikolov, an intern at Microsoft, found a way to encode the meaning of words in a modest number of vector dimensions. Mikolov trained a neural network5 to predict word occurrences near each target word. In 2013, once at Google, Mikolov and his teammates released the software for creating these word vectors and called it Word2vec. Word2vec learns the meaning of words merely by processing a large corpus of unlabeled text. No one has to label the words in the Word2vec vocabulary. No one has to tell the Word2vec algorithm that Marie Curie is a scientist, that the Timbers are a soccer team, that Seattle is a city, or that Portland is a city in both Oregon and Maine. And no one has to tell Word2vec that soccer is a sport, or that a team is a group of people, or that cities are both places as well as communities. Word2vec can learn that and much more, all on its own! All you need is a corpus large enough to mention Marie Curie and Timbers and Portland near other words associated with science or soccer or cities. This unsupervised nature of Word2vec is what makes it so powerful. The world is full of unlabeled, uncategorized, unstructured natural language text. Instead of trying to train a neural network to learn the target word meanings directly (on the basis of labels for that meaning), you teach the network to predict words near the target word in your sentences. So in this sense, you do have labels: the nearby words you’re trying to predict. But because the labels are coming from the dataset itself and require no hand-labeling, the Word2vec training algorithm is definitely an unsupervised learning algorithm. And the prediction itself isn’t what makes Word2vec work. The prediction is merely a means to an end. What you do care about is the internal representation, the vector that Word2vec gradually builds up to help it generate those predictions. Word2vec will learn about things you might not think to associate with all words. Did you know that every word has some geography, sentiment (positivity), and gender associated with it? If any word in your corpus has some quality, like “placeness,” “peopleness,” “conceptness,” or “femaleness,” all the other words will also be given a score for these qualities in your word vectors. The meaning of a word “rubs off” on the neighboring words when Word2vec learns word vectors. Word2vec allows you to transform your natural language vectors of token occurrence counts and frequencies into the vector space of much lower-dimensional Word2vec vectors. In this lower-dimensional space, you can do your math and then convert back to a natural language space. You can imagine how useful this capability is to a chatbot, search engine, question answering system, or information extraction algorithm. The research team also discovered that the difference between a singular and a plural word is often roughly the same magnitude, and in the same direction:Equation 6.2: Distance between the singular and plural versions of a word But their discovery didn’t stop there. They also discovered that the distance relationships go far beyond simple singular versus plural relationships. Distances apply to other semantic relationships. The Word2vec researchers soon discovered they could answer questions that involve geography, culture, and demographics, like this: "San Francisco is to California as what is to Colorado?" San Francisco - California + Colorado = DenverHow to compute Word2vec representations
Word vectors represent the semantic meaning of words as vectors in the context of the training corpus. This allows you not only to answer analogy questions but also reason about the meaning of words in more general ways with vector algebra. But how do you calculate these vector representations? There are two possible ways to train Word2vec embeddings: Skip-gram approach The skip-gram approach predicts the context of words (output words) from a word of interest (the input word). Continuous bag-of-words The continuous bag-of-words (CBOW) approach predicts the target word (the output word) from the nearby words (input words). We show you how and when to use each of these to train a Word2vec model in the coming sections.SKIP-GRAM APPROACH
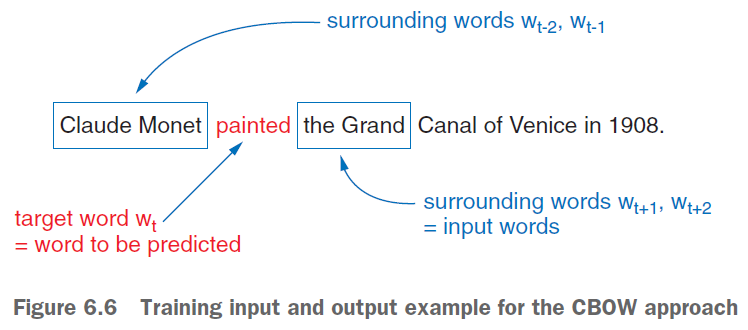
In the skip-gram training approach, you’re trying to predict the surrounding window of words based on an input word. In the sentence about Monet, in our following example, “painted” is the training input to the neural network. The corresponding trainingoutput example skip-grams are shown in figure 6.3. The predicted words for these skipgrams are the neighboring words “Claude,” “Monet,” “the,” and “Grand.” Let's say we have a sentence: Claude Monet painted the Grand Canal of venice in 1908. We are going to predict neighbouring words for the word "Monet".CONTINUOUS BAG-OF-WORDS APPROACH
In the continuous bag-of-words approach, you’re trying to predict the center word based on the surrounding words (see figures 6.5 and 6.6 and table 6.2). Instead of creating pairs of input and output tokens, you’ll create a multi-hot vector of all surrounding terms as an input vector. The multi-hot input vector is the sum of all one-hot vectors of the surrounding tokens to the center, target token.Continuous bag of words vs. bag of words
In previous chapters, we introduced the concept of a bag of words, but how is it different than a continuous bag of words? To establish the relationships between words in a sentence you slide a rolling window across the sentence to select the surrounding words for the target word. All words within the sliding window are considered to be the content of the continuous bag of words for the target word at the middle of that window.SKIP-GRAM VS. CBOW: WHEN TO USE WHICH APPROACH
Mikolov highlighted that the skip-gram approach works well with small corpora and rare terms. With the skip-gram approach, you’ll have more examples due to the network structure. But the continuous bag-of-words approach shows higher accuracies for frequent words and is much faster to train.Negative sampling
One last trick Mikolov came up with was the idea of negative sampling. If a single training example with a pair of words is presented to the network, it’ll cause all weights for the network to be updated. This changes the values of all the vectors for all the words in your vocabulary. But if your vocabulary contains thousands or millions of words, updating all the weights for the large one-hot vector is inefficient. To speed up the training of word vector models, Mikolov used negative sampling. Instead of updating all word weights that weren’t included in the word window, Mikolov suggested sampling just a few negative samples (in the output vector) to update their weights. Instead of updating all weights, you pick n negative example word pairs (words that don’t match your target output for that example) and update the weights that contributed to their specific output. That way, the computation can be reduced dramatically and the performance of the trained network doesn’t decrease significantly. NOTE If you train your word model with a small corpus, you might want to use a negative sampling rate of 5 to 20 samples. For larger corpora and vocabularies, you can reduce the negative sample rate to as low as two to five samples, according to Mikolov and his team.Word2vec vs. GloVe (Global Vectors)
Word2vec was a breakthrough, but it relies on a neural network model that must be trained using backpropagation. Backpropagation is usually less efficient than direct optimization of a cost function using gradient descent. Stanford NLP researchers21 led by Jeffrey Pennington set about to understand the reason why Word2vec worked so well and to find the cost function that was being optimized. They started by counting the word co-occurrences and recording them in a square matrix. They found they could compute the singular value decomposition22 of this co-occurrence matrix, splitting it into the same two weight matrices that Word2vec produces.23 The key was to normalize the co-occurrence matrix the same way. But in some cases the Word2vec model failed to converge to the same global optimum that the Stanford researchers were able to achieve with their SVD approach. It’s this direct optimization of the global vectors of word co-occurrences (co-occurrences across the entire corpus) that gives GloVe its name. GloVe can produce matrices equivalent to the input weight matrix and output weight matrix of Word2vec, producing a language model with the same accuracy as Word2vec but in much less time. GloVe speeds the process by using the text data more efficiently. GloVe can be trained on smaller corpora and still converge.24 And SVD algorithms have been refined for decades, so GloVe has a head start on debugging and algorithm optimization. Word2vec relies on backpropagation to update the weights that form the word embeddings. Neural network backpropagation is less efficient than more mature optimization algorithms such as those used within SVD for GloVe. Even though Word2vec first popularized the concept of semantic reasoning with word vectors, your workhorse should probably be GloVe to train new word vector models. With GloVe you’ll be more likely to find the global optimum for those vector representations, giving you more accurate results. Advantages of GloVe are: # Faster training # Better RAM/CPU efficiency (can handle larger documents) # More efficient use of data (helps with smaller corpora) # More accurate for the same amount of trainingfastText
Researchers from Facebook took the concept of Word2vec one step further25 by adding a new twist to the model training. The new algorithm, which they named fastText, predicts the surrounding n-character grams rather than just the surrounding words, like Word2vec does. For example, the word “whisper” would generate the following 2- and 3-character grams: wh, whi, hi, his, is, isp, sp, spe, pe, per, er fastText trains a vector representation for every n-character gram, which includes words, misspelled words, partial words, and even single characters. The advantage of this approach is that it handles rare words much better than the original Word2vec approach. As part of the fastText release, Facebook published pretrained fastText models for 294 languages. On the Github page of Facebook research,26 you can find models ranging from Abkhazian to Zulu. The model collection even includes rare languages such as Saterland Frisian, which is only spoken by a handful of Germans. The pretrained fastText models provided by Facebook have only been trained on the available Wikipedia corpora. Therefore the vocabulary and accuracy of the models will vary across languages.Word vectors are biased!
Word vectors learn word relationships based on the training corpus. If your corpus is about finance then your “bank” word vector will be mainly about businesses that hold deposits. If your corpus is about geology, then your “bank” word vector will be trained on associations with rivers and streams. And if you corpus is mostly about a matriarchal society with women bankers and men washing clothes in the river, then your word vectors would take on that gender bias. The following example shows the gender bias of a word model trained on Google News articles. If you calculate the distance between “man” and “nurse” and compare that to the distance between “woman” and “nurse,” you’ll be able to see the bias: >>> word_model.distance('man', 'nurse') 0.7453 >>> word_model.distance('woman', 'nurse') 0.5586 Identifying and compensating for biases like this is a challenge for any NLP practitioner that trains her models on documents written in a biased world.Document similarity with Doc2vec
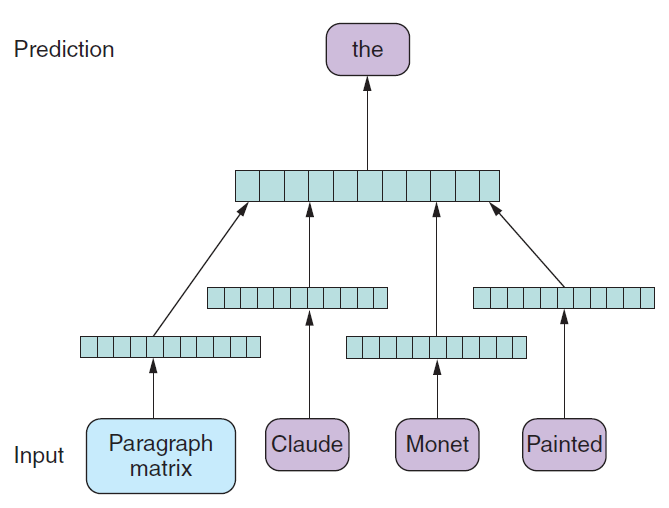
The concept of Word2vec can also be extended to sentences, paragraphs, or entire documents. The idea of predicting the next word based on the previous words can be extended by training a paragraph or document vector (see figure 6.10).33 In this case, the prediction not only considers the previous words, but also the vector representing the paragraph or the document. It can be considered as an additional word input to the prediction. Over time, the algorithm learns a document or paragraph representation from the training set. How are document vectors generated for unseen documents after the training phase? During the inference stage, the algorithm adds more document vectors to the document matrix and computes the added vector based on the frozen word vector matrix, and its weights. By inferring a document vector, you can now create a semantic representation of the whole document.Figure 6.10 Doc2vec training uses an additional document vector as input.
Monday, June 6, 2022
Reasoning With Word Vectors (Word2Vec, GloVe, fastText and Doc2Vec)






Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment