from __future__ import print_function
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import spacy
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
from preprocess import preprocess_text
import matplotlib.pyplot as plt
nlp = spacy.load("en_core_web_sm")
def remove_verbs_and_adjectives(text):
doc = nlp(text)
additional_stopwords = ["new", "like", "many", "also", "even", "get", "say", "according", "would", "could",
"know", "made", "make", "come", "didnt", "dont", "doesnt", "go", "may", "back",
"going", "including", "added", "set", "take", "want", "use",
"000", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "20", "u",
"one", "two", "three", "year", "first", "last", "good", "best", "well", "told", "said"]
days_of_week = ["monday", "tuesday", "wednesday", "thursday", "friday", "saturday", "sunday"]
additional_stopwords += days_of_week
words = [token.text for token in doc if (token.pos_ not in ["VERB", "NUM", "ADJ", "ADV", "ADP", "SCONJ", "DET",
"X", "INTJ", "CCONJ", "AUX", 'PART', 'PRON', 'PUNCT', 'SYM'])]
words = [x for x in words if len(x) > 2]
words = [x for x in words if x not in additional_stopwords]
doc = " ".join(words)
return doc
df1 = pd.read_csv('bbc_news_train.csv')
%%time
df1['Preprocess_text'] = df1['Text'].apply(preprocess_text)
df1['Preprocess_text'] = df1['Preprocess_text'].apply(remove_verbs_and_adjectives)
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
stop_words = 'english',
lowercase = True,
token_pattern = r'\b[a-zA-Z]{3,}\b',
max_df = 0.5,
min_df = 10)
dtm_tf = tf_vectorizer.fit_transform(df1['Preprocess_text'])
%%time
lda_tf = LatentDirichletAllocation(n_components=5, random_state=0)
lda_tf.fit(dtm_tf) # LatentDirichletAllocation(n_components=5, random_state=0)
pyLDAvis.sklearn.prepare(lda_tf, dtm_tf, tf_vectorizer)
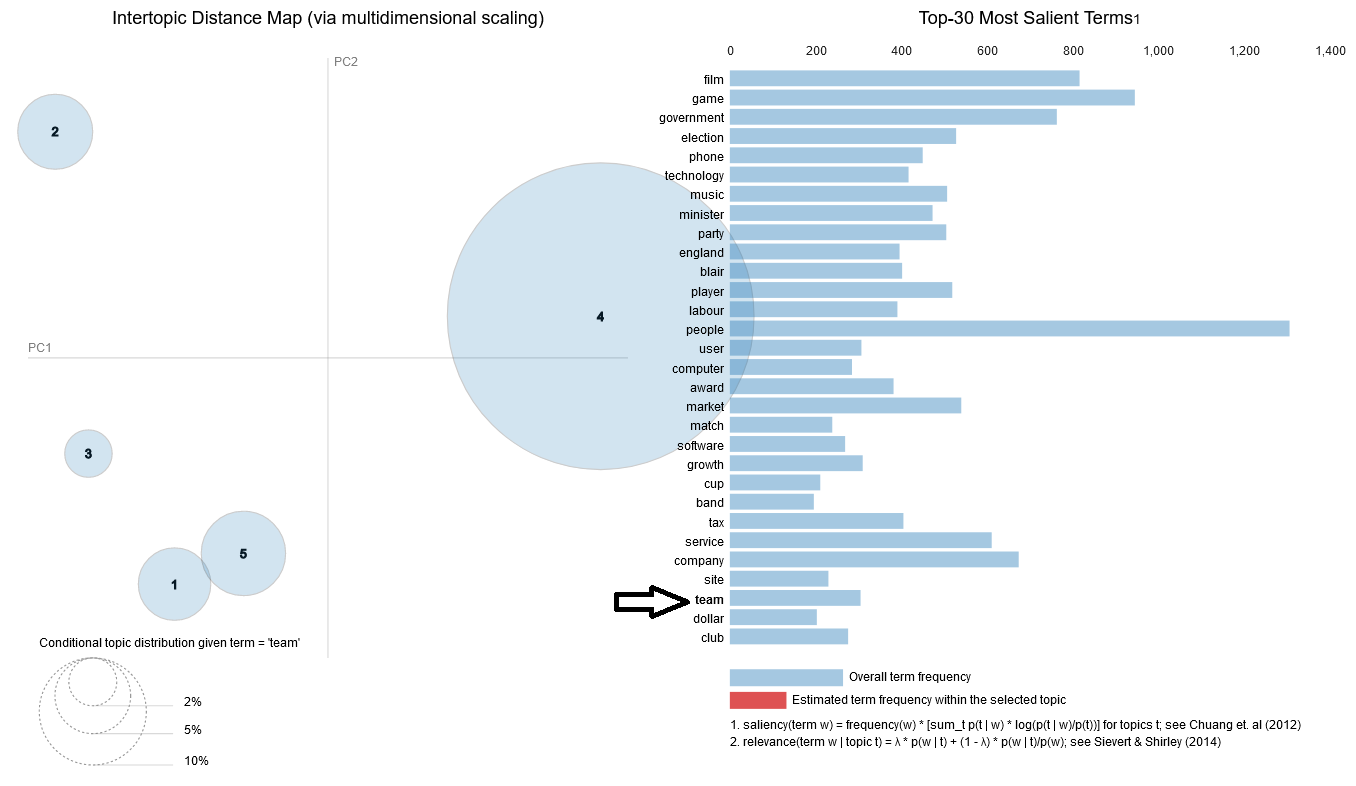
1. High Level View

2. Exploring Sports Cluster

3. Exploring the term "Team"
 def plot_top_words(model, feature_names, n_top_words, title):
#fig, axes = plt.subplots(2, 5, figsize=(30, 15), sharex=True)
fig, axes = plt.subplots(1, 5, figsize=(30, 15), sharex=True)
axes = axes.flatten()
for topic_idx, topic in enumerate(model.components_):
top_features_ind = topic.argsort()[: -n_top_words - 1 : -1]
top_features = [feature_names[i] for i in top_features_ind]
weights = topic[top_features_ind]
ax = axes[topic_idx]
ax.barh(top_features, weights, height=0.7)
ax.set_title(f"Topic {topic_idx +1}", fontdict={"fontsize": 30})
ax.invert_yaxis()
ax.tick_params(axis="both", which="major", labelsize=20)
for i in "top right left".split():
ax.spines[i].set_visible(False)
fig.suptitle(title, fontsize=40)
plt.subplots_adjust(top=0.90, bottom=0.05, wspace=0.90, hspace=0.3)
plt.show()
n_top_words = 20
plot_top_words(lda_tf, tf_vectorizer.get_feature_names(), n_top_words, "Topics in LDA model")
def plot_top_words(model, feature_names, n_top_words, title):
#fig, axes = plt.subplots(2, 5, figsize=(30, 15), sharex=True)
fig, axes = plt.subplots(1, 5, figsize=(30, 15), sharex=True)
axes = axes.flatten()
for topic_idx, topic in enumerate(model.components_):
top_features_ind = topic.argsort()[: -n_top_words - 1 : -1]
top_features = [feature_names[i] for i in top_features_ind]
weights = topic[top_features_ind]
ax = axes[topic_idx]
ax.barh(top_features, weights, height=0.7)
ax.set_title(f"Topic {topic_idx +1}", fontdict={"fontsize": 30})
ax.invert_yaxis()
ax.tick_params(axis="both", which="major", labelsize=20)
for i in "top right left".split():
ax.spines[i].set_visible(False)
fig.suptitle(title, fontsize=40)
plt.subplots_adjust(top=0.90, bottom=0.05, wspace=0.90, hspace=0.3)
plt.show()
n_top_words = 20
plot_top_words(lda_tf, tf_vectorizer.get_feature_names(), n_top_words, "Topics in LDA model")
 for topic_idx, topic in enumerate(lda_tf.components_):
top_features_ind = topic.argsort()[: -n_top_words - 1 : -1]
top_features = [tf_vectorizer.get_feature_names()[i] for i in top_features_ind]
weights = topic[top_features_ind]
print()
print(top_features)
print(weights)
['film', 'market', 'award', 'sale', 'growth', 'company', 'price', 'bank', 'rate', 'economy', 'share', 'director', 'month', 'actor', 'dollar', 'firm', 'china', 'star', 'profit', 'analyst']
[782.39034709 366.28139534 322.86071389 284.59708969 273.47636047
270.04200023 246.46217158 222.28393084 221.57275007 220.44223774
217.44204193 217.16230918 210.70770464 208.58603001 205.89147443
200.87216491 200.44549958 191.36606456 181.4342261 173.2076483 ]
['music', 'band', 'company', 'court', 'club', 'album', 'number', 'group', 'chart', 'song', 'record', 'sale', 'london', 'case', 'singer', 'charge', 'drug', 'day', 'deal', 'bid']
[252.53858311 188.25792769 185.23003226 148.14318776 145.85605702
144.19663752 140.08497961 135.82856133 129.27287007 128.42244733
125.84229174 116.22180106 116.07193359 109.62077913 109.5121517
108.17668145 105.2106134 104.29483314 102.85209462 101.69194202]
['game', 'time', 'england', 'player', 'world', 'team', 'match', 'win', 'cup', 'minute', 'season', 'champion', 'ireland', 'injury', 'wale', 'france', 'goal', 'chelsea', 'week', 'coach']
[602.21909322 378.09944132 341.67737838 336.05299822 279.3877861
255.26640777 243.15720494 242.95257795 214.19830526 191.78217721
188.27405349 185.72607709 181.66983554 178.32170657 174.85059546
166.49655125 159.49832106 159.12597256 156.66993433 155.74636717]
['government', 'election', 'people', 'party', 'minister', 'blair', 'labour', 'country', 'tax', 'plan', 'law', 'lord', 'leader', 'issue', 'time', 'secretary', 'home', 'britain', 'campaign', 'service']
[737.11131292 535.16527677 503.88220861 492.81224241 472.1748853
405.93862213 392.08668008 377.9692403 374.10296897 321.81905251
251.941626 228.98752682 224.14880061 208.55888715 194.76072149
194.1927585 192.50127191 186.69009254 181.17916067 180.81032583]
['people', 'phone', 'technology', 'service', 'game', 'user', 'computer', 'software', 'music', 'firm', 'site', 'time', 'network', 'video', 'mail', 'internet', 'way', 'consumer', 'number', 'virus']
[680.17474713 452.3961128 422.18599053 392.05349486 315.97985885
310.19888871 287.0726163 272.19648631 260.04783894 233.83933227
229.49176761 224.82279539 219.68765596 219.425011 215.04665086
214.76647326 209.25888074 202.79667119 198.7542187 197.672328 ]
df_test = pd.read_csv('bbc_news_test.csv')
%%time
df_test['Preprocess_text'] = df_test['Text'].apply(preprocess_text)
df_test['Preprocess_text'] = df_test['Preprocess_text'].apply(remove_verbs_and_adjectives)
df_test_tf = tf_vectorizer.transform(df_test['Preprocess_text'])
lda_tf.transform(df_test_tf)
array([[0.128288 , 0.00543088, 0.85561882, 0.00534719, 0.00531511],
[0.00191148, 0.00193182, 0.00193953, 0.28883497, 0.70538221],
[0.00360513, 0.00360238, 0.98555182, 0.00363063, 0.00361004],
...,
[0.11366724, 0.32884101, 0.00273285, 0.32595816, 0.22880073],
[0.52009706, 0.00362464, 0.03958206, 0.24591173, 0.1907845 ],
[0.0339508 , 0.00166348, 0.0016659 , 0.96107025, 0.00164957]])
for topic_idx, topic in enumerate(lda_tf.components_):
top_features_ind = topic.argsort()[: -n_top_words - 1 : -1]
top_features = [tf_vectorizer.get_feature_names()[i] for i in top_features_ind]
weights = topic[top_features_ind]
print()
print(top_features)
print(weights)
['film', 'market', 'award', 'sale', 'growth', 'company', 'price', 'bank', 'rate', 'economy', 'share', 'director', 'month', 'actor', 'dollar', 'firm', 'china', 'star', 'profit', 'analyst']
[782.39034709 366.28139534 322.86071389 284.59708969 273.47636047
270.04200023 246.46217158 222.28393084 221.57275007 220.44223774
217.44204193 217.16230918 210.70770464 208.58603001 205.89147443
200.87216491 200.44549958 191.36606456 181.4342261 173.2076483 ]
['music', 'band', 'company', 'court', 'club', 'album', 'number', 'group', 'chart', 'song', 'record', 'sale', 'london', 'case', 'singer', 'charge', 'drug', 'day', 'deal', 'bid']
[252.53858311 188.25792769 185.23003226 148.14318776 145.85605702
144.19663752 140.08497961 135.82856133 129.27287007 128.42244733
125.84229174 116.22180106 116.07193359 109.62077913 109.5121517
108.17668145 105.2106134 104.29483314 102.85209462 101.69194202]
['game', 'time', 'england', 'player', 'world', 'team', 'match', 'win', 'cup', 'minute', 'season', 'champion', 'ireland', 'injury', 'wale', 'france', 'goal', 'chelsea', 'week', 'coach']
[602.21909322 378.09944132 341.67737838 336.05299822 279.3877861
255.26640777 243.15720494 242.95257795 214.19830526 191.78217721
188.27405349 185.72607709 181.66983554 178.32170657 174.85059546
166.49655125 159.49832106 159.12597256 156.66993433 155.74636717]
['government', 'election', 'people', 'party', 'minister', 'blair', 'labour', 'country', 'tax', 'plan', 'law', 'lord', 'leader', 'issue', 'time', 'secretary', 'home', 'britain', 'campaign', 'service']
[737.11131292 535.16527677 503.88220861 492.81224241 472.1748853
405.93862213 392.08668008 377.9692403 374.10296897 321.81905251
251.941626 228.98752682 224.14880061 208.55888715 194.76072149
194.1927585 192.50127191 186.69009254 181.17916067 180.81032583]
['people', 'phone', 'technology', 'service', 'game', 'user', 'computer', 'software', 'music', 'firm', 'site', 'time', 'network', 'video', 'mail', 'internet', 'way', 'consumer', 'number', 'virus']
[680.17474713 452.3961128 422.18599053 392.05349486 315.97985885
310.19888871 287.0726163 272.19648631 260.04783894 233.83933227
229.49176761 224.82279539 219.68765596 219.425011 215.04665086
214.76647326 209.25888074 202.79667119 198.7542187 197.672328 ]
df_test = pd.read_csv('bbc_news_test.csv')
%%time
df_test['Preprocess_text'] = df_test['Text'].apply(preprocess_text)
df_test['Preprocess_text'] = df_test['Preprocess_text'].apply(remove_verbs_and_adjectives)
df_test_tf = tf_vectorizer.transform(df_test['Preprocess_text'])
lda_tf.transform(df_test_tf)
array([[0.128288 , 0.00543088, 0.85561882, 0.00534719, 0.00531511],
[0.00191148, 0.00193182, 0.00193953, 0.28883497, 0.70538221],
[0.00360513, 0.00360238, 0.98555182, 0.00363063, 0.00361004],
...,
[0.11366724, 0.32884101, 0.00273285, 0.32595816, 0.22880073],
[0.52009706, 0.00362464, 0.03958206, 0.24591173, 0.1907845 ],
[0.0339508 , 0.00166348, 0.0016659 , 0.96107025, 0.00164957]])
What you are seeing above: Probability that a document contains that topic.
Wednesday, June 29, 2022
Creating a Taxonomy for BBC News Articles (Part 10 - Topic modeling using Latent Dirichlet Allocation from sklearn and visualization using pyLDAvis)



Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment