In terms of their use as activation functions, when is sigmoid used and when is hyperbolic tangent used?
Sigmoid and hyperbolic tangent (tanh) are both activation functions commonly used in neural networks, but they have different characteristics that make them suitable for different situations. Sigmoid Function (Logistic Function): Range: It squashes input values to the range (0, 1). Output: The output is always positive, and it is particularly useful in binary classification problems where the goal is to output probabilities that sum to 1. Issues: Sigmoid tends to suffer from the "vanishing gradient" problem, which can make training deep networks challenging. Use Cases: Output layer of binary classification models. Situations where you need a binary decision, such as in logistic regression. Hyperbolic Tangent Function (tanh): Range: It squashes input values to the range (-1, 1). Output: Like the sigmoid, it is suitable for models that require outputs in the form of probabilities. However, its output range includes negative values, making it zero-centered. This helps mitigate the vanishing gradient problem to some extent. Advantages: Zero-centered nature helps in the optimization process during training, compared to the sigmoid. Use Cases: Hidden layers of neural networks, especially in cases where zero-centered activation functions are preferred. Situations where the output needs to be in a range that spans both positive and negative values. In practice, the choice between sigmoid and tanh depends on the specific requirements of your neural network and the nature of the problem you're trying to solve. In modern deep learning architectures, rectified linear units (ReLU) and its variants are also popular choices for hidden layers due to their training efficiency and ability to mitigate the vanishing gradient problem.Why and how do sigmoid activation function results in vanishing gradient problem?
The vanishing gradient problem is a challenge that can occur during the training of deep neural networks, particularly when using activation functions with certain characteristics, such as the sigmoid function. The problem arises in the context of gradient-based optimization algorithms, like backpropagation, which are commonly used to update the weights of neural networks during training. Here's why the sigmoid activation function can lead to the vanishing gradient problem: Output Range: The sigmoid function squashes input values to the range (0, 1). This means that for large positive or negative inputs, the sigmoid saturates, and the output becomes very close to 0 or 1. Once the output is near these extremes, the gradient of the sigmoid becomes extremely small. Derivative Characteristics: The derivative of the sigmoid function is maximum at its center (around 0.25) and approaches zero as you move away from the center. This means that the gradients for large positive or negative inputs are close to zero. In the context of backpropagation, the gradient is used to update the weights of the network, and if the gradients are very small, the updates to the weights become negligible. Multiplicative Nature of Gradients: In a deep neural network, during backpropagation, gradients are propagated backward through the layers. Since the gradients are multiplied at each layer, if the gradients are very small, they can quickly diminish as they are propagated backward through the network. This can result in the gradients becoming effectively zero for the weights in the early layers of the network, preventing effective learning in those layers. In summary, the vanishing gradient problem occurs because the sigmoid function, when used in deep networks, can produce very small gradients for weights in the early layers, hindering the training process. This can lead to slower convergence and, in extreme cases, the early layers may not learn meaningful representations. To mitigate the vanishing gradient problem, other activation functions like hyperbolic tangent (tanh) or rectified linear units (ReLU) are often used, as they exhibit better training characteristics in deep networks.On a side note...
Derivative of Sigmoid function


Derivative of tanh(z)
An alternative to the logistic sigmoid is the hyperbolic tangent, or tanh function (Figure 1, green curves):Like the logistic sigmoid, the tanh function is also sigmoidal (“s”-shaped), but instead outputs values that range (-1,1). Thus strongly negative inputs to the tanh will map to negative outputs. Additionally, only zero-valued inputs are mapped to near-zero outputs. These properties make the network less likely to get “stuck” during training. Calculating the gradient for the tanh function also uses the quotient rule: Similar to the derivative for the logistic sigmoid, the derivative of gtanh(z) is a function of feed-forward activation evaluated at z, namely (1-gtanh(z)2). Thus the same caching trick can be used for layers that implement tanh activation functions.
Similar to the derivative for the logistic sigmoid, the derivative of gtanh(z) is a function of feed-forward activation evaluated at z, namely (1-gtanh(z)2). Thus the same caching trick can be used for layers that implement tanh activation functions.
Common Activation Functions and Plots of Their Derivatives



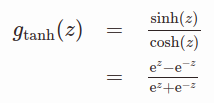


Side notes
(1) How are tanh and sigmoid related? Can you write tanh as a function of sigmoid?
The hyperbolic tangent function (tanh) and the sigmoid function (often the logistic sigmoid) are related through a simple mathematical transformation. The tanh function can be expressed in terms of the sigmoid function as follows:
Here, represents the sigmoid function, defined as .
So, to obtain the tanh function, you take twice the input (), apply the sigmoid function to it (), multiply the result by 2 (), and then subtract 1 (). This transformation ensures that the output of the tanh function is in the range of , similar to how the sigmoid function squashes values into the range .
No comments:
Post a Comment